
Deep Learning (04) - 신경망 / Fashion-MNIST
신경망 적용해보기
MNIST와 Fashion-MNIST
Fashion-MNIST 살펴보기
- Fashion-MNIST 데이터셋 다운받기
In [1]:
from keras.datasets.fashion_mnist import load_data
In [2]:
(x_train, y_train), (x_test, y_test) = load_data()
print(x_train.shape, x_test.shape)
Out [2]:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
29515/29515 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26421880/26421880 [==============================] - 1s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
5148/5148 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4422102/4422102 [==============================] - 0s 0us/step
(60000, 28, 28) (10000, 28, 28)
- 데이터 그려보기
In [3]:
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(777)
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
sample_size = 9
random_idx = np.random.randint(60000, size=sample_size)
plt.figure(figsize=(5, 5))
for i, idx in enumerate(random_idx):
plt.subplot(3, 3, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(x_train[idx], cmap='gray')
plt.xlabel(class_names[y_train[idx]])
plt.show()
Out [3]:

- 전처리 및 검증 데이터셋 만들기
In [4]:
x_train.min(), x_train.max()
Out [4]:
(0, 255)
In [5]:
# 딥러닝을 위해 값의 범위 축소
x_train = x_train/255
x_test = x_test/255
In [6]:
x_train.min(), x_train.max()
Out [6]:
(0.0, 1.0)
In [7]:
y_train.min(), y_train.max()
Out [7]:
(0, 9)
In [8]:
from keras.utils import to_categorical
# 레이블을 범주형 형태로 변경
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
In [9]:
y_train[0]
Out [9]:
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 1.], dtype=float32)
In [10]:
from sklearn.model_selection import train_test_split
# 학습/검증 데이터셋을 7:3 비율로 분리
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train,
test_size=0.3, random_state=777)
- 모델 구성
In [11]:
from keras.models import Sequential
from keras.layers import Dense, Flatten # Dense: 완전연결층, Flatten: 데이터를 1차원 배열로 펼침
In [12]:
first_model = Sequential()
first_model.add(Flatten(input_shape=(28, 28))) # (28, 28) -> (28*28)
first_model.add(Dense(64, activation='relu'))
first_model.add(Dense(32, activation='relu'))
first_model.add(Dense(10, activation='softmax')) # 10개의 최종 출력 # softmax: 모두 합하여 1이 됨
- 학습하기
In [13]:
first_model.compile(optimizer='adam', # 옵티마이저: adam
loss='categorical_crossentropy', # 손실함수: 카테고리컬 엔트로피
metrics=['acc']) # 평가지표: acc
In [14]:
first_model.summary() # 모델 구성 확인
Out [14]:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense (Dense) (None, 64) 50240
dense_1 (Dense) (None, 32) 2080
dense_2 (Dense) (None, 10) 330
=================================================================
Total params: 52,650
Trainable params: 52,650
Non-trainable params: 0
_________________________________________________________________
Trainable params : 학습을 통해 값이 변경되는 파라미터
Non-trainable params : 역전파(backpropagation) 훈련중에 고정시켜 변경되지 않게 한 파라미터(기존 학습에 다시)
In [15]:
first_history = first_model.fit(x_train, y_train,
epochs=30, batch_size=128,
validation_data=(x_val, y_val)) # batch_size: 한번에 읽어들이는 수, 메모리 크기에 따라 정함
Out [15]:
Epoch 1/30
329/329 [==============================] - 4s 9ms/step - loss: 0.6745 - acc: 0.7675 - val_loss: 0.5219 - val_acc: 0.8233
Epoch 2/30
329/329 [==============================] - 2s 7ms/step - loss: 0.4501 - acc: 0.8421 - val_loss: 0.4139 - val_acc: 0.8562
Epoch 3/30
329/329 [==============================] - 2s 7ms/step - loss: 0.4083 - acc: 0.8557 - val_loss: 0.3950 - val_acc: 0.8593
Epoch 4/30
329/329 [==============================] - 2s 6ms/step - loss: 0.3809 - acc: 0.8635 - val_loss: 0.4084 - val_acc: 0.8530
Epoch 5/30
329/329 [==============================] - 2s 6ms/step - loss: 0.3585 - acc: 0.8726 - val_loss: 0.3750 - val_acc: 0.8672
Epoch 6/30
329/329 [==============================] - 1s 4ms/step - loss: 0.3423 - acc: 0.8774 - val_loss: 0.3657 - val_acc: 0.8692
Epoch 7/30
329/329 [==============================] - 1s 4ms/step - loss: 0.3320 - acc: 0.8810 - val_loss: 0.3568 - val_acc: 0.8731
Epoch 8/30
329/329 [==============================] - 1s 4ms/step - loss: 0.3167 - acc: 0.8866 - val_loss: 0.3619 - val_acc: 0.8709
Epoch 9/30
329/329 [==============================] - 1s 3ms/step - loss: 0.3100 - acc: 0.8876 - val_loss: 0.3357 - val_acc: 0.8814
Epoch 10/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2990 - acc: 0.8917 - val_loss: 0.3414 - val_acc: 0.8762
Epoch 11/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2904 - acc: 0.8941 - val_loss: 0.3378 - val_acc: 0.8824
Epoch 12/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2815 - acc: 0.8968 - val_loss: 0.3312 - val_acc: 0.8852
Epoch 13/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2738 - acc: 0.9003 - val_loss: 0.3309 - val_acc: 0.8842
Epoch 14/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2676 - acc: 0.9024 - val_loss: 0.3352 - val_acc: 0.8817
Epoch 15/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2589 - acc: 0.9061 - val_loss: 0.3289 - val_acc: 0.8847
Epoch 16/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2519 - acc: 0.9080 - val_loss: 0.3176 - val_acc: 0.8904
Epoch 17/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2479 - acc: 0.9092 - val_loss: 0.3436 - val_acc: 0.8816
Epoch 18/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2493 - acc: 0.9073 - val_loss: 0.3414 - val_acc: 0.8803
Epoch 19/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2424 - acc: 0.9104 - val_loss: 0.3393 - val_acc: 0.8868
Epoch 20/30
329/329 [==============================] - 2s 6ms/step - loss: 0.2366 - acc: 0.9142 - val_loss: 0.3375 - val_acc: 0.8858
Epoch 21/30
329/329 [==============================] - 2s 7ms/step - loss: 0.2310 - acc: 0.9153 - val_loss: 0.3339 - val_acc: 0.8847
Epoch 22/30
329/329 [==============================] - 2s 7ms/step - loss: 0.2261 - acc: 0.9173 - val_loss: 0.3278 - val_acc: 0.8889
Epoch 23/30
329/329 [==============================] - 2s 7ms/step - loss: 0.2217 - acc: 0.9184 - val_loss: 0.3431 - val_acc: 0.8844
Epoch 24/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2178 - acc: 0.9192 - val_loss: 0.3385 - val_acc: 0.8867
Epoch 25/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2136 - acc: 0.9222 - val_loss: 0.3365 - val_acc: 0.8884
Epoch 26/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2097 - acc: 0.9235 - val_loss: 0.3577 - val_acc: 0.8814
Epoch 27/30
329/329 [==============================] - 1s 4ms/step - loss: 0.2112 - acc: 0.9224 - val_loss: 0.3282 - val_acc: 0.8897
Epoch 28/30
329/329 [==============================] - 1s 4ms/step - loss: 0.1998 - acc: 0.9269 - val_loss: 0.3467 - val_acc: 0.8833
Epoch 29/30
329/329 [==============================] - 1s 4ms/step - loss: 0.1983 - acc: 0.9284 - val_loss: 0.3493 - val_acc: 0.8797
Epoch 30/30
329/329 [==============================] - 1s 3ms/step - loss: 0.1964 - acc: 0.9281 - val_loss: 0.3358 - val_acc: 0.8894
- 두번째 모델 구성
In [16]:
second_model = Sequential()
second_model.add(Flatten(input_shape=(28, 28)))
second_model.add(Dense(128, activation='relu'))
second_model.add(Dense(64, activation='relu'))
second_model.add(Dense(32, activation='relu'))
second_model.add(Dense(10, activation='softmax'))
second_model.compile(optimizer='adam', # 옵티마이저: adam
loss='categorical_crossentropy', # 손실함수: 카테고리컬 엔트로피
metrics=['acc']) # 평가지표: acc
second_history = second_model.fit(x_train, y_train,
epochs=30, batch_size=128,
validation_data=(x_val, y_val))
Out [16]:
Epoch 1/30
329/329 [==============================] - 2s 5ms/step - loss: 0.6295 - acc: 0.7814 - val_loss: 0.4768 - val_acc: 0.8301
Epoch 2/30
329/329 [==============================] - 2s 5ms/step - loss: 0.4199 - acc: 0.8509 - val_loss: 0.4134 - val_acc: 0.8494
Epoch 3/30
329/329 [==============================] - 2s 5ms/step - loss: 0.3752 - acc: 0.8659 - val_loss: 0.4398 - val_acc: 0.8366
Epoch 4/30
329/329 [==============================] - 2s 5ms/step - loss: 0.3454 - acc: 0.8748 - val_loss: 0.3480 - val_acc: 0.8767
Epoch 5/30
329/329 [==============================] - 2s 5ms/step - loss: 0.3269 - acc: 0.8814 - val_loss: 0.3528 - val_acc: 0.8745
Epoch 6/30
329/329 [==============================] - 2s 5ms/step - loss: 0.3077 - acc: 0.8875 - val_loss: 0.3284 - val_acc: 0.8814
Epoch 7/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2916 - acc: 0.8930 - val_loss: 0.3235 - val_acc: 0.8814
Epoch 8/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2866 - acc: 0.8931 - val_loss: 0.3214 - val_acc: 0.8809
Epoch 9/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2729 - acc: 0.8982 - val_loss: 0.3275 - val_acc: 0.8797
Epoch 10/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2626 - acc: 0.9013 - val_loss: 0.3128 - val_acc: 0.8893
Epoch 11/30
329/329 [==============================] - 2s 6ms/step - loss: 0.2525 - acc: 0.9069 - val_loss: 0.3081 - val_acc: 0.8907
Epoch 12/30
329/329 [==============================] - 2s 7ms/step - loss: 0.2438 - acc: 0.9090 - val_loss: 0.3254 - val_acc: 0.8875
Epoch 13/30
329/329 [==============================] - 2s 6ms/step - loss: 0.2360 - acc: 0.9114 - val_loss: 0.3239 - val_acc: 0.8846
Epoch 14/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2301 - acc: 0.9138 - val_loss: 0.3293 - val_acc: 0.8847
Epoch 15/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2241 - acc: 0.9151 - val_loss: 0.3265 - val_acc: 0.8882
Epoch 16/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2179 - acc: 0.9178 - val_loss: 0.3235 - val_acc: 0.8883
Epoch 17/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2087 - acc: 0.9229 - val_loss: 0.3443 - val_acc: 0.8797
Epoch 18/30
329/329 [==============================] - 2s 5ms/step - loss: 0.2017 - acc: 0.9241 - val_loss: 0.3455 - val_acc: 0.8858
Epoch 19/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1990 - acc: 0.9252 - val_loss: 0.3422 - val_acc: 0.8842
Epoch 20/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1949 - acc: 0.9274 - val_loss: 0.3308 - val_acc: 0.8873
Epoch 21/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1904 - acc: 0.9290 - val_loss: 0.3300 - val_acc: 0.8922
Epoch 22/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1834 - acc: 0.9305 - val_loss: 0.3541 - val_acc: 0.8881
Epoch 23/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1784 - acc: 0.9323 - val_loss: 0.3481 - val_acc: 0.8891
Epoch 24/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1745 - acc: 0.9346 - val_loss: 0.3516 - val_acc: 0.8929
Epoch 25/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1688 - acc: 0.9350 - val_loss: 0.3284 - val_acc: 0.8958
Epoch 26/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1656 - acc: 0.9373 - val_loss: 0.3494 - val_acc: 0.8927
Epoch 27/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1646 - acc: 0.9373 - val_loss: 0.3452 - val_acc: 0.8937
Epoch 28/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1573 - acc: 0.9410 - val_loss: 0.3574 - val_acc: 0.8939
Epoch 29/30
329/329 [==============================] - 2s 6ms/step - loss: 0.1544 - acc: 0.9425 - val_loss: 0.3418 - val_acc: 0.8973
Epoch 30/30
329/329 [==============================] - 2s 5ms/step - loss: 0.1532 - acc: 0.9424 - val_loss: 0.3539 - val_acc: 0.8944
In [17]:
second_model.summary()
Out [17]:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
dense_3 (Dense) (None, 128) 100480
dense_4 (Dense) (None, 64) 8256
dense_5 (Dense) (None, 32) 2080
dense_6 (Dense) (None, 10) 330
=================================================================
Total params: 111,146
Trainable params: 111,146
Non-trainable params: 0
_________________________________________________________________
- 학습과정 시각화
In [18]:
def draw_loss_acc(history1, history2, epochs):
his_dict_1 = history1.history
his_dict_2 = history2.history
keys = list(his_dict_1.keys())
epochs = range(1, epochs)
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
# axis 선과 ax의 축 레이블 제거
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.spines['left'].set_color('none')
ax.spines['right'].set_color('none')
ax.tick_params(labelcolor='w', top=False,
bottom=False, left=False, right=False)
for i in range(len(his_dict_1)):
temp_ax = fig.add_subplot(2, 2, i+1)
temp = keys[i%2] # keys(loss, acc, val_loss, val_acc) 중에 loss와 acc만
val_temp = keys[(i+2)%2+2] # keys 중에 val_loss와 val_acc만
temp_history = his_dict_1 if i < 2 else his_dict_2
temp_ax.plot(epochs, temp_history[temp][1:], color='blue', label='train_'+temp)
temp_ax.plot(epochs, temp_history[val_temp][1:], color='orange', label=val_temp)
if(i==1 or i==3):
start, end = temp_ax.get_ylim()
temp_ax.yaxis.set_ticks(np.arange(np.round(start, 2), end, 0.01)) # y축 눈금을 정리
temp_ax.legend()
ax.set_ylabel('loss', size=20)
ax.set_xlabel('Epochs', size=20)
plt.tight_layout()
plt.show()
draw_loss_acc(first_history, second_history, 30)
Out [18]:
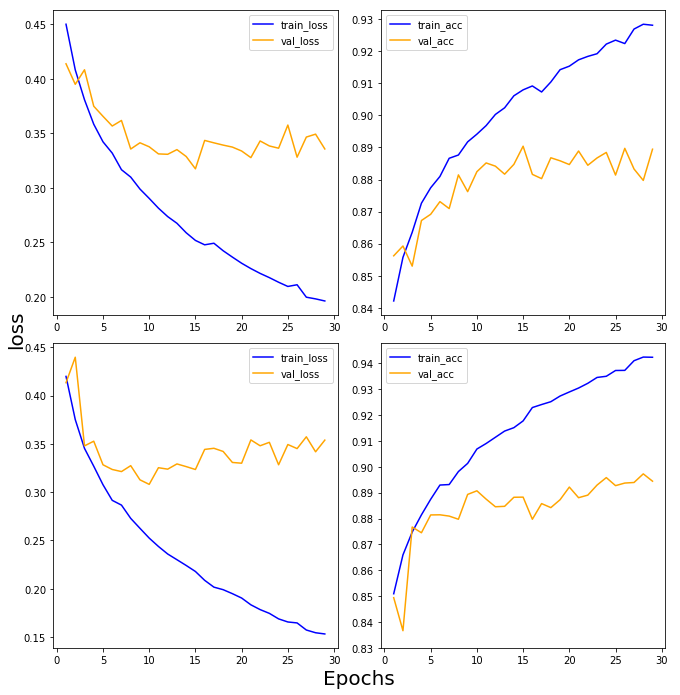
모델을 깊게 구성하면 높은 성능을 얻을 수 있는 만큼 모델이 가지는 파라미터의 수가 매우 많아지기 때문에 과대적합 문제에도 많이 노출될 수 있다.
모델의 깊이는 데이터에 알맞게 조절될 필요가 있다.
- 실제 이미지를 불러와 모델 적용
In [19]:
from PIL import Image
In [20]:
img = Image.open('/content/drive/MyDrive/Colab Notebooks/deep_learning/04_fashion_mnist_img/img03.png')
img = img.convert('L')
img = img.resize((28, 28))
img = np.array(img)
img = (255 - img)/255 # 색 반전, 범위 축소
plt.imshow(img, cmap='gray')
plt.show()
Out [20]:

In [21]:
img.shape, x_train.shape # 입력 차원이 다름
Out [21]:
((28, 28), (42000, 28, 28))
In [22]:
result = first_model.predict(img.reshape(-1, 28, 28))
result.shape
Out [22]:
1/1 [==============================] - 0s 72ms/step
(1, 10)
In [23]:
np.round(result, 2)
Out [23]:
array([[0.13, 0.15, 0.07, 0.31, 0.32, 0. , 0.01, 0. , 0. , 0. ]],
dtype=float32)
In [24]:
class_names[np.argmax(result)]
Out [24]:
'Coat'
In [25]:
result = second_model.predict(img.reshape(-1, 28, 28))
class_names[np.argmax(result)]
Out [25]:
1/1 [==============================] - 0s 51ms/step
'T-shirt/top'
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기