
Deep Learning (10) - CNN / CIFAR-10 / 규제화 함수
컨볼루션 신경망
CIFAR-10 살펴보기
과대적합 피하기
In [1]:
from keras.datasets import cifar10
from sklearn.model_selection import train_test_split
import numpy as np
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 기본 전처리
x_mean = np.mean(x_train, axis=(0, 1, 2))
x_std = np.std(x_train, axis=(0, 1, 2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
# 검증 데이터 분리
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.3, random_state=777)
Out [1]:
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 6s 0us/step
규제화 함수 사용해보기
In [2]:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten
from keras.optimizers import Adam
from keras.regularizers import l2 # L2: 제곱을 사용하여 가중치를 줄여 과적합 방지
model = Sequential([
Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', input_shape=(32, 32, 3)),
Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', kernel_regularizer=l2(0.001)),
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'),
Conv2D(filters=64, kernel_size=3, padding='same', activation='relu', kernel_regularizer=l2(0.001)),
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'),
Conv2D(filters=128, kernel_size=3, padding='same', activation='relu', kernel_regularizer=l2(0.001)),
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
Flatten(),
Dense(256, activation='relu', kernel_regularizer=l2(0.001)), # l2에 알파값 0.001부여
Dense(10, activation='softmax')
])
model.compile(optimizer=Adam(1e-4),
loss='sparse_categorical_crossentropy',
metrics=['acc'])
In [3]:
history = model.fit(x_train, y_train, epochs=30,
batch_size=32, validation_data=(x_val, y_val))
Out [3]:
Epoch 1/30
1094/1094 [==============================] - 17s 7ms/step - loss: 2.1208 - acc: 0.4065 - val_loss: 1.8145 - val_acc: 0.4955
Epoch 2/30
1094/1094 [==============================] - 9s 8ms/step - loss: 1.6763 - acc: 0.5454 - val_loss: 1.5630 - val_acc: 0.5811
Epoch 3/30
1094/1094 [==============================] - 9s 8ms/step - loss: 1.4717 - acc: 0.6112 - val_loss: 1.4253 - val_acc: 0.6213
Epoch 4/30
1094/1094 [==============================] - 7s 7ms/step - loss: 1.3286 - acc: 0.6586 - val_loss: 1.3353 - val_acc: 0.6507
Epoch 5/30
1094/1094 [==============================] - 7s 7ms/step - loss: 1.2165 - acc: 0.6915 - val_loss: 1.2409 - val_acc: 0.6743
Epoch 6/30
1094/1094 [==============================] - 9s 8ms/step - loss: 1.1235 - acc: 0.7227 - val_loss: 1.1901 - val_acc: 0.6947
Epoch 7/30
1094/1094 [==============================] - 8s 7ms/step - loss: 1.0447 - acc: 0.7447 - val_loss: 1.1756 - val_acc: 0.6989
Epoch 8/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.9691 - acc: 0.7698 - val_loss: 1.1446 - val_acc: 0.7089
Epoch 9/30
1094/1094 [==============================] - 8s 7ms/step - loss: 0.8954 - acc: 0.7931 - val_loss: 1.1131 - val_acc: 0.7176
Epoch 10/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.8337 - acc: 0.8108 - val_loss: 1.0973 - val_acc: 0.7243
Epoch 11/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.7695 - acc: 0.8334 - val_loss: 1.0870 - val_acc: 0.7310
Epoch 12/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.7110 - acc: 0.8522 - val_loss: 1.0910 - val_acc: 0.7332
Epoch 13/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.6497 - acc: 0.8743 - val_loss: 1.1413 - val_acc: 0.7242
Epoch 14/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.6009 - acc: 0.8912 - val_loss: 1.2038 - val_acc: 0.7187
Epoch 15/30
1094/1094 [==============================] - 9s 8ms/step - loss: 0.5509 - acc: 0.9061 - val_loss: 1.2249 - val_acc: 0.7289
Epoch 16/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.5111 - acc: 0.9210 - val_loss: 1.2869 - val_acc: 0.7280
Epoch 17/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.4666 - acc: 0.9362 - val_loss: 1.3174 - val_acc: 0.7314
Epoch 18/30
1094/1094 [==============================] - 8s 8ms/step - loss: 0.4444 - acc: 0.9425 - val_loss: 1.3551 - val_acc: 0.7211
Epoch 19/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.4117 - acc: 0.9540 - val_loss: 1.4053 - val_acc: 0.7275
Epoch 20/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.3961 - acc: 0.9589 - val_loss: 1.5000 - val_acc: 0.7231
Epoch 21/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3760 - acc: 0.9647 - val_loss: 1.4857 - val_acc: 0.7247
Epoch 22/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3644 - acc: 0.9685 - val_loss: 1.4800 - val_acc: 0.7287
Epoch 23/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.3551 - acc: 0.9710 - val_loss: 1.5983 - val_acc: 0.7229
Epoch 24/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3508 - acc: 0.9707 - val_loss: 1.5591 - val_acc: 0.7277
Epoch 25/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3331 - acc: 0.9769 - val_loss: 1.6461 - val_acc: 0.7254
Epoch 26/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.3300 - acc: 0.9764 - val_loss: 1.6750 - val_acc: 0.7215
Epoch 27/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3246 - acc: 0.9773 - val_loss: 1.6174 - val_acc: 0.7269
Epoch 28/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.3213 - acc: 0.9772 - val_loss: 1.6719 - val_acc: 0.7185
Epoch 29/30
1094/1094 [==============================] - 7s 7ms/step - loss: 0.3122 - acc: 0.9788 - val_loss: 1.6156 - val_acc: 0.7289
Epoch 30/30
1094/1094 [==============================] - 7s 6ms/step - loss: 0.3041 - acc: 0.9805 - val_loss: 1.6684 - val_acc: 0.7153
In [4]:
import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10, 5))
# 손실 그리기
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color='blue', label='train_loss')
ax1.plot(epochs, val_loss, color='orange', label='val_loss')
ax1.set_title('train and val loss')
ax1.set_xlabel('epochs')
ax1.set_ylabel('loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
# 정확도 그리기
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, acc, color='blue', label='train_acc')
ax2.plot(epochs, val_acc, color='orange', label='val_acc')
ax2.set_title('train and val acc')
ax2.set_xlabel('epochs')
ax2.set_ylabel('loss')
ax2.legend()
Out [4]:
<matplotlib.legend.Legend at 0x7f32164fffa0>
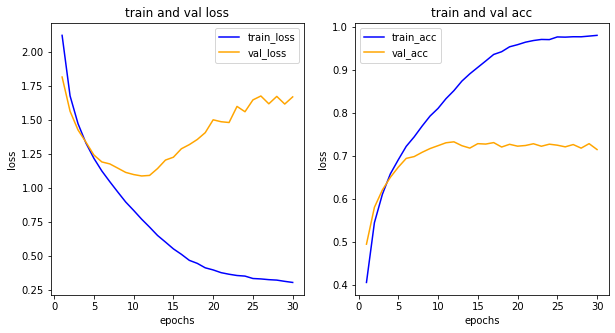
과적합이 완화되었다.
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기