
Deep Learning (13) - CNN / CIFAR-10 / 데이터 증가
컨볼루션 신경망
CIFAR-10 살펴보기
데이터 증가 사용하기
머신러닝에 비해 딥러닝은 데이터가 많이 필요하고 데이터가 적으면 일반화가 어렵다. -> 과대적합의 가능성
- 다양한 데이터를 입력시킴으로써 모델을 더욱 견고하게 만들어주기 때문에 테스트 시에 더 높은 성능을 기대할 수 있다.
- 수집된 데이터가 적은 경우에 강력한 힘을 발휘한다.
In [1]:
from keras.utils import load_img, img_to_array
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import numpy as np
In [2]:
train_datagen = ImageDataGenerator(
horizontal_flip=True, vertical_flip=True, # 수평, 수직 뒤집기
shear_range=0.5, brightness_range=[0.5, 1.5], # 반시계 방향 기울기 정도, 밝기 정도
zoom_range=0.2, width_shift_range=0.1, height_shift_range=0.1, # 확대 정도, 너비와 높이 이동 정도
rotation_range=30, fill_mode='nearest') # 회전 정도, 새로 생기는 픽셀 채울 방법
In [3]:
img = img_to_array(load_img('img000.jpg')).astype(np.uint8)
plt.imshow(img)
Out [3]:
<matplotlib.image.AxesImage at 0x7f1af33d78e0>

- 이미지 제네레이터 통과시켜 보기
In [4]:
result = img.reshape((1, ) + img.shape)
img.shape, result.shape # 데이터 건수 관련 차원을 앞에 추가
Out [4]:
((438, 730, 3), (1, 438, 730, 3))
In [5]:
train_generator = train_datagen.flow(result, batch_size=1)
In [6]:
plt.figure(figsize=(5, 5))
plt.suptitle('Image Augmentation')
for i in range(9):
data = next(train_generator)
image = data[0]
plt.subplot(3, 3, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(np.array(image, dtype=np.uint8))
plt.show()
Out [6]:

- 이미지 제네레이터를 사용하여 모델 학습하기
In [7]:
from keras.datasets import cifar10
from sklearn.model_selection import train_test_split
import numpy as np
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 기본 전처리
x_mean = np.mean(x_train, axis=(0, 1, 2))
x_std = np.std(x_train, axis=(0, 1, 2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
# 검증 데이터 분리
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.3, random_state=777)
Out [7]:
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 14s 0us/step
In [8]:
y_train.shape, y_val.shape
Out [8]:
((35000, 1), (15000, 1))
In [9]:
y_train = np.squeeze(y_train)
y_val = np.squeeze(y_val)
In [10]:
y_train.shape, y_val.shape
Out [10]:
((35000,), (15000,))
In [11]:
train_datagen = ImageDataGenerator(
horizontal_flip=True, zoom_range=0.2,
width_shift_range=0.1, height_shift_range=0.1,
rotation_range=30, fill_mode='nearest')
val_datagen = ImageDataGenerator() # 검증용은 이미지 원본 그대로
batch_size = 32
train_generator = train_datagen.flow(x_train, y_train, batch_size = batch_size)
val_generator = val_datagen.flow(x_val, y_val, batch_size = batch_size)
In [12]:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Activation, BatchNormalization
from keras.optimizers import Adam
model = Sequential([
Conv2D(filters=32, kernel_size=3, padding='same', input_shape=(32, 32, 3)),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=32, kernel_size=3, padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
Conv2D(filters=64, kernel_size=3, padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=64, kernel_size=3, padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
Conv2D(filters=128, kernel_size=3, padding='same'),
BatchNormalization(),
Activation('relu'),
Conv2D(filters=128, kernel_size=3, padding='same'),
BatchNormalization(),
Activation('relu'),
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'),
Flatten(),
Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer=Adam(1e-4),
loss='sparse_categorical_crossentropy',
metrics=['acc'])
In [13]:
def get_step(train_len, batch_size):
if train_len % batch_size > 0:
return train_len // batch_size + 1
else:
return train_len // batch_size
In [14]:
history = model.fit(train_generator, epochs=30,
steps_per_epoch=get_step(len(x_train), batch_size),
validation_data=val_generator,
validation_steps=get_step(len(x_val), batch_size))
Out [14]:
Epoch 1/30
1094/1094 [==============================] - 41s 30ms/step - loss: 1.6349 - acc: 0.4126 - val_loss: 1.3599 - val_acc: 0.5135
Epoch 2/30
1094/1094 [==============================] - 30s 27ms/step - loss: 1.3654 - acc: 0.5148 - val_loss: 1.2162 - val_acc: 0.5669
Epoch 3/30
1094/1094 [==============================] - 25s 23ms/step - loss: 1.2491 - acc: 0.5579 - val_loss: 1.2127 - val_acc: 0.5799
Epoch 4/30
1094/1094 [==============================] - 26s 23ms/step - loss: 1.1628 - acc: 0.5898 - val_loss: 1.0678 - val_acc: 0.6224
Epoch 5/30
1094/1094 [==============================] - 25s 23ms/step - loss: 1.0982 - acc: 0.6133 - val_loss: 0.9542 - val_acc: 0.6618
Epoch 6/30
1094/1094 [==============================] - 25s 23ms/step - loss: 1.0401 - acc: 0.6393 - val_loss: 0.9453 - val_acc: 0.6630
Epoch 7/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.9962 - acc: 0.6510 - val_loss: 0.9310 - val_acc: 0.6739
Epoch 8/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.9505 - acc: 0.6675 - val_loss: 0.9483 - val_acc: 0.6723
Epoch 9/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.9171 - acc: 0.6787 - val_loss: 0.9590 - val_acc: 0.6704
Epoch 10/30
1094/1094 [==============================] - 26s 24ms/step - loss: 0.8789 - acc: 0.6931 - val_loss: 1.0431 - val_acc: 0.6545
Epoch 11/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.8480 - acc: 0.7043 - val_loss: 0.7763 - val_acc: 0.7271
Epoch 12/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.8238 - acc: 0.7134 - val_loss: 0.7305 - val_acc: 0.7447
Epoch 13/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.7995 - acc: 0.7241 - val_loss: 0.8523 - val_acc: 0.7094
Epoch 14/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.7799 - acc: 0.7295 - val_loss: 0.7910 - val_acc: 0.7277
Epoch 15/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.7638 - acc: 0.7341 - val_loss: 0.6682 - val_acc: 0.7670
Epoch 16/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.7361 - acc: 0.7455 - val_loss: 0.6538 - val_acc: 0.7683
Epoch 17/30
1094/1094 [==============================] - 26s 24ms/step - loss: 0.7186 - acc: 0.7490 - val_loss: 0.7489 - val_acc: 0.7445
Epoch 18/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.7039 - acc: 0.7565 - val_loss: 0.6648 - val_acc: 0.7693
Epoch 19/30
1094/1094 [==============================] - 25s 22ms/step - loss: 0.6924 - acc: 0.7599 - val_loss: 0.7926 - val_acc: 0.7334
Epoch 20/30
1094/1094 [==============================] - 24s 22ms/step - loss: 0.6760 - acc: 0.7649 - val_loss: 0.6200 - val_acc: 0.7895
Epoch 21/30
1094/1094 [==============================] - 25s 22ms/step - loss: 0.6648 - acc: 0.7687 - val_loss: 0.6023 - val_acc: 0.7923
Epoch 22/30
1094/1094 [==============================] - 24s 22ms/step - loss: 0.6502 - acc: 0.7727 - val_loss: 0.6381 - val_acc: 0.7805
Epoch 23/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.6425 - acc: 0.7781 - val_loss: 0.5907 - val_acc: 0.7982
Epoch 24/30
1094/1094 [==============================] - 24s 22ms/step - loss: 0.6301 - acc: 0.7839 - val_loss: 0.5830 - val_acc: 0.7991
Epoch 25/30
1094/1094 [==============================] - 25s 23ms/step - loss: 0.6203 - acc: 0.7853 - val_loss: 0.5792 - val_acc: 0.8001
Epoch 26/30
1094/1094 [==============================] - 24s 22ms/step - loss: 0.6103 - acc: 0.7894 - val_loss: 0.5489 - val_acc: 0.8133
Epoch 27/30
1094/1094 [==============================] - 25s 22ms/step - loss: 0.5964 - acc: 0.7940 - val_loss: 0.6293 - val_acc: 0.7834
Epoch 28/30
1094/1094 [==============================] - 24s 22ms/step - loss: 0.5860 - acc: 0.7979 - val_loss: 0.5439 - val_acc: 0.8140
Epoch 29/30
1094/1094 [==============================] - 24s 22ms/step - loss: 0.5808 - acc: 0.7995 - val_loss: 0.5580 - val_acc: 0.8120
Epoch 30/30
1094/1094 [==============================] - 24s 22ms/step - loss: 0.5656 - acc: 0.8027 - val_loss: 0.5845 - val_acc: 0.8011
In [15]:
import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10, 5))
# 손실 그리기
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color='blue', label='train_loss')
ax1.plot(epochs, val_loss, color='orange', label='val_loss')
ax1.set_title('train and val loss')
ax1.set_xlabel('epochs')
ax1.set_ylabel('loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
# 정확도 그리기
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, acc, color='blue', label='train_acc')
ax2.plot(epochs, val_acc, color='orange', label='val_acc')
ax2.set_title('train and val acc')
ax2.set_xlabel('epochs')
ax2.set_ylabel('loss')
ax2.legend()
plt.show()
Out [15]:
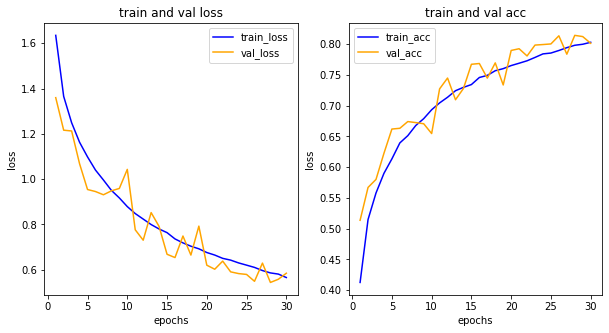
과대적합 문제를 줄이고, 향상된 성능!
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기