
Deep Learning (14) - CNN / CIFAR-10 / 전이 학습
컨볼루션 신경망
전이 학습
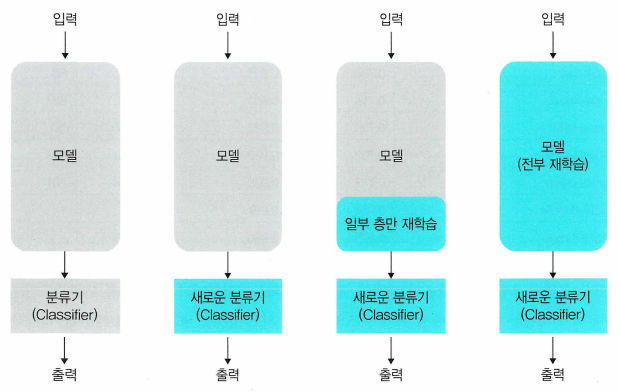
- 전이 학습(transfer learning)의 핵심은 사전 학습(pre-trained)된 네트워크의 가중치를 사용하는 것이다.
- 모델을 변형하지 않고 사용하는 방법
- 모델의 분류기를 재학습하는 방법(기본적으로 가장 많이 사용)
- 모델의 일부를 동결 해제하여 재학습하는 방법
In [1]:
from keras.datasets import cifar10
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
plt.imshow(x_test[0])
# 기본 전처리
x_mean = np.mean(x_train, axis=(0, 1, 2))
x_std = np.std(x_train, axis=(0, 1, 2))
x_train = (x_train - x_mean) / x_std
x_test = (x_test - x_mean) / x_std
# 검증 데이터 분리
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.3, random_state=777)
y_train.shape
Out [1]:
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 3s 0us/step
(35000, 1)

In [2]:
y_train = np.squeeze(y_train)
y_val = np.squeeze(y_val)
- 전이 학습 사용해보기
In [3]:
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
horizontal_flip=True, zoom_range=0.2,
width_shift_range=0.1, height_shift_range=0.1,
rotation_range=30, fill_mode='nearest')
val_datagen = ImageDataGenerator()
batch_size = 32
train_generator = train_datagen.flow(x_train, y_train, batch_size=batch_size)
val_generator = val_datagen.flow(x_val, y_val, batch_size=batch_size)
In [4]:
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Activation, BatchNormalization
from keras.optimizers import Adam
from keras.applications import VGG16
vgg16 = VGG16(weights='imagenet', input_shape=(32, 32, 3), include_top=False)
# include_top: 기존 학습된 input_shape 사용여부
vgg16.summary()
Out [4]:
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
58889256/58889256 [==============================] - 0s 0us/step
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
- 일부 층만 사용할 경우
In [5]:
# 뒤쪽 4개 층을 제외하고 동결하여 훈련 불가능하게 변경
for layer in vgg16.layers[:-4]:
layer.trainable=False
In [6]:
vgg16.summary()
Out [6]:
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
block1_conv1 (Conv2D) (None, 32, 32, 64) 1792
block1_conv2 (Conv2D) (None, 32, 32, 64) 36928
block1_pool (MaxPooling2D) (None, 16, 16, 64) 0
block2_conv1 (Conv2D) (None, 16, 16, 128) 73856
block2_conv2 (Conv2D) (None, 16, 16, 128) 147584
block2_pool (MaxPooling2D) (None, 8, 8, 128) 0
block3_conv1 (Conv2D) (None, 8, 8, 256) 295168
block3_conv2 (Conv2D) (None, 8, 8, 256) 590080
block3_conv3 (Conv2D) (None, 8, 8, 256) 590080
block3_pool (MaxPooling2D) (None, 4, 4, 256) 0
block4_conv1 (Conv2D) (None, 4, 4, 512) 1180160
block4_conv2 (Conv2D) (None, 4, 4, 512) 2359808
block4_conv3 (Conv2D) (None, 4, 4, 512) 2359808
block4_pool (MaxPooling2D) (None, 2, 2, 512) 0
block5_conv1 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv2 (Conv2D) (None, 2, 2, 512) 2359808
block5_conv3 (Conv2D) (None, 2, 2, 512) 2359808
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 7,079,424
Non-trainable params: 7,635,264
_________________________________________________________________
In [7]:
model = Sequential([
vgg16,
Flatten(),
Dense(256),
BatchNormalization(),
Activation('relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer=Adam(1e-4),
loss='sparse_categorical_crossentropy',
metrics=['acc'])
def get_step(train_len, batch_size):
if train_len % batch_size > 0:
return train_len // batch_size + 1
else:
return train_len // batch_size
In [8]:
history = model.fit(train_generator, epochs=30,
steps_per_epoch=get_step(len(x_train), batch_size),
validation_data=val_generator,
validation_steps=get_step(len(x_val), batch_size))
Out [8]:
Epoch 1/30
1094/1094 [==============================] - 39s 27ms/step - loss: 1.1247 - acc: 0.6102 - val_loss: 1.0213 - val_acc: 0.6545
Epoch 2/30
1094/1094 [==============================] - 30s 28ms/step - loss: 0.9251 - acc: 0.6768 - val_loss: 0.8677 - val_acc: 0.6989
Epoch 3/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.8513 - acc: 0.7017 - val_loss: 0.7333 - val_acc: 0.7447
Epoch 4/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.7988 - acc: 0.7200 - val_loss: 0.8174 - val_acc: 0.7191
Epoch 5/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.7633 - acc: 0.7329 - val_loss: 0.7794 - val_acc: 0.7304
Epoch 6/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.7333 - acc: 0.7436 - val_loss: 0.6911 - val_acc: 0.7583
Epoch 7/30
1094/1094 [==============================] - 30s 27ms/step - loss: 0.7045 - acc: 0.7528 - val_loss: 0.7653 - val_acc: 0.7339
Epoch 8/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.6763 - acc: 0.7633 - val_loss: 0.6518 - val_acc: 0.7752
Epoch 9/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.6532 - acc: 0.7723 - val_loss: 0.6640 - val_acc: 0.7698
Epoch 10/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.6325 - acc: 0.7796 - val_loss: 0.6676 - val_acc: 0.7725
Epoch 11/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.6028 - acc: 0.7854 - val_loss: 0.6575 - val_acc: 0.7762
Epoch 12/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.5807 - acc: 0.7947 - val_loss: 0.6645 - val_acc: 0.7709
Epoch 13/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.5599 - acc: 0.8024 - val_loss: 0.6654 - val_acc: 0.7799
Epoch 14/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.5419 - acc: 0.8083 - val_loss: 0.6402 - val_acc: 0.7850
Epoch 15/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.5299 - acc: 0.8149 - val_loss: 0.6291 - val_acc: 0.7849
Epoch 16/30
1094/1094 [==============================] - 30s 27ms/step - loss: 0.5123 - acc: 0.8173 - val_loss: 0.6684 - val_acc: 0.7841
Epoch 17/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.4919 - acc: 0.8262 - val_loss: 0.6793 - val_acc: 0.7790
Epoch 18/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.4829 - acc: 0.8286 - val_loss: 0.7339 - val_acc: 0.7648
Epoch 19/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.4607 - acc: 0.8360 - val_loss: 0.6818 - val_acc: 0.7849
Epoch 20/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.4523 - acc: 0.8393 - val_loss: 0.6353 - val_acc: 0.7901
Epoch 21/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.4299 - acc: 0.8482 - val_loss: 0.6690 - val_acc: 0.7887
Epoch 22/30
1094/1094 [==============================] - 30s 27ms/step - loss: 0.4106 - acc: 0.8550 - val_loss: 0.6840 - val_acc: 0.7871
Epoch 23/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.4056 - acc: 0.8574 - val_loss: 0.6843 - val_acc: 0.7856
Epoch 24/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.3843 - acc: 0.8637 - val_loss: 0.7155 - val_acc: 0.7731
Epoch 25/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.3736 - acc: 0.8692 - val_loss: 0.6896 - val_acc: 0.7832
Epoch 26/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.3657 - acc: 0.8706 - val_loss: 0.7434 - val_acc: 0.7756
Epoch 27/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.3572 - acc: 0.8730 - val_loss: 0.7501 - val_acc: 0.7793
Epoch 28/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.3315 - acc: 0.8833 - val_loss: 0.7372 - val_acc: 0.7831
Epoch 29/30
1094/1094 [==============================] - 29s 27ms/step - loss: 0.3304 - acc: 0.8828 - val_loss: 0.7520 - val_acc: 0.7801
Epoch 30/30
1094/1094 [==============================] - 29s 26ms/step - loss: 0.3128 - acc: 0.8899 - val_loss: 0.7409 - val_acc: 0.7843
In [9]:
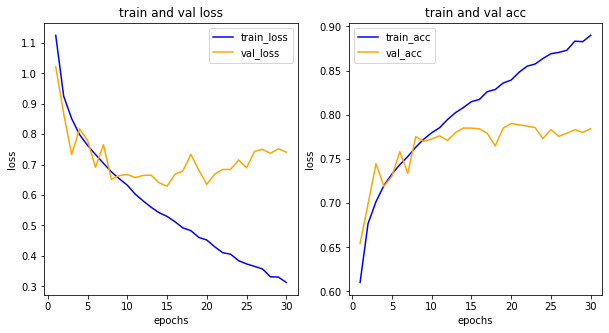
import matplotlib.pyplot as plt
his_dict = history.history
loss = his_dict['loss']
val_loss = his_dict['val_loss']
epochs = range(1, len(loss)+1)
fig = plt.figure(figsize=(10, 5))
# 손실 그리기
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(epochs, loss, color='blue', label='train_loss')
ax1.plot(epochs, val_loss, color='orange', label='val_loss')
ax1.set_title('train and val loss')
ax1.set_xlabel('epochs')
ax1.set_ylabel('loss')
ax1.legend()
acc = his_dict['acc']
val_acc = his_dict['val_acc']
# 정확도 그리기
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(epochs, acc, color='blue', label='train_acc')
ax2.plot(epochs, val_acc, color='orange', label='val_acc')
ax2.set_title('train and val acc')
ax2.set_xlabel('epochs')
ax2.set_ylabel('loss')
ax2.legend()
plt.show()
Out [9]:
- 테스트 해보기
In [14]:
test_datagen = ImageDataGenerator()
test_generator = test_datagen.flow(x_test, batch_size=batch_size)
pred = model.predict(test_generator)
np.argmax(np.round(pred[0], 2))
Out [14]:
313/313 [==============================] - 3s 9ms/step
8
In [13]:
y_test[0]
Out [13]:
array([3], dtype=uint8)
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기