
Deep Learning (15) - CNN / Functional API
Functional API를 이용한 모델
In [1]:
from keras.datasets.mnist import load_data
import numpy as np
In [2]:
(x_train, y_train), (x_test, y_test) = load_data()
Out [2]:
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 [==============================] - 2s 0us/step
0~9의 숫자를 짝수, 홀수로 가려보자!
In [3]:
# 홀수 여부 체크(홀수1, 짝수0)
y_train_odd = []
for y in y_train:
if y % 2 == 0:
y_train_odd.append(0)
else:
y_train_odd.append(1)
y_train_odd = np.array(y_train_odd)
y_train_odd.shape
Out [3]:
(60000,)
In [4]:
print(y_train[:10])
print(y_train_odd[:10])
Out [4]:
[5 0 4 1 9 2 1 3 1 4]
[1 0 0 1 1 0 1 1 1 0]
In [5]:
y_test_odd = []
for y in y_test:
if y % 2 == 0:
y_test_odd.append(0)
else:
y_test_odd.append(1)
y_test_odd = np.array(y_test_odd)
y_test_odd.shape
Out [5]:
(10000,)
In [6]:
x_train.min(), x_train.max()
Out [6]:
(0, 255)
- x 값의 범위 조절
In [7]:
x_train = x_train / 255.
x_test = x_test / 255.
In [8]:
x_train.min(), x_train.max()
Out [8]:
(0.0, 1.0)
- CNN에 통과시키기 위해 4차원 형태로 변환
In [9]:
x_train.shape
Out [9]:
(60000, 28, 28)
In [10]:
x_train_in = np.expand_dims(x_train, -1)
x_test_in = np.expand_dims(x_test, -1)
x_train_in.shape, x_test_in.shape
Out [10]:
((60000, 28, 28, 1), (10000, 28, 28, 1))
In [11]:
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPool2D, Flatten, Dense, Concatenate
In [12]:
# 입력단 설정
inputs = Input(shape=(28, 28, 1))
# 첫번째 분기
conv = Conv2D(32, (3, 3), activation='relu')(inputs)
pool = MaxPool2D((2, 2))(conv)
flat = Flatten()(pool)
# 두번째 분기
flat_inputs = Flatten()(inputs)
# 분기 합치기
concat = Concatenate()([flat, flat_inputs])
outputs = Dense(10, activation='softmax')(concat)
# 모델 설정
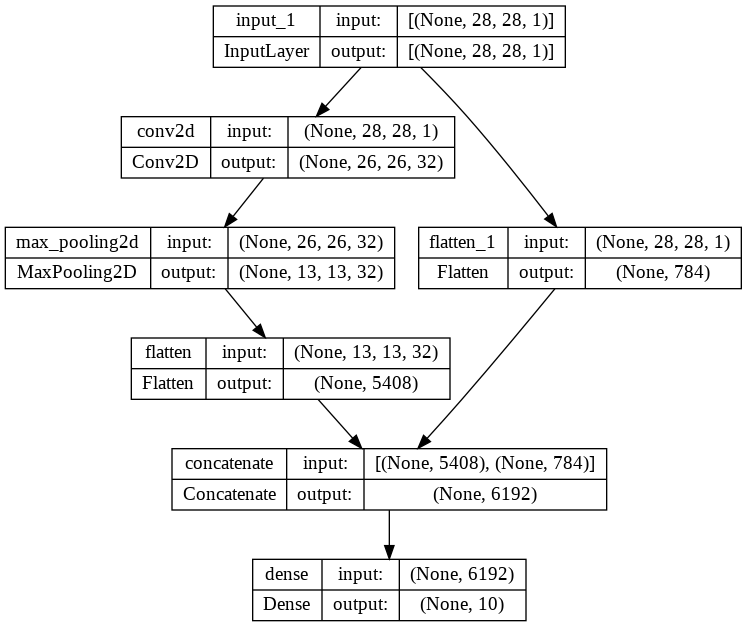
model = Model(inputs=inputs, outputs=outputs)
model.summary()
Out [12]:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 28, 28, 1)] 0 []
conv2d (Conv2D) (None, 26, 26, 32) 320 ['input_1[0][0]']
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0 ['conv2d[0][0]']
flatten (Flatten) (None, 5408) 0 ['max_pooling2d[0][0]']
flatten_1 (Flatten) (None, 784) 0 ['input_1[0][0]']
concatenate (Concatenate) (None, 6192) 0 ['flatten[0][0]',
'flatten_1[0][0]']
dense (Dense) (None, 10) 61930 ['concatenate[0][0]']
==================================================================================================
Total params: 62,250
Trainable params: 62,250
Non-trainable params: 0
__________________________________________________________________________________________________
In [13]:
from keras.utils import plot_model
In [14]:
plot_model(model, show_shapes=True, show_layer_names=True)
Out [14]:
In [15]:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
In [16]:
history = model.fit(x_train_in, y_train,
validation_data=(x_test_in, y_test), epochs=10)
model.evaluate(x_test_in, y_test)
Out [16]:
Epoch 1/10
1875/1875 [==============================] - 15s 3ms/step - loss: 0.2072 - accuracy: 0.9411 - val_loss: 0.0930 - val_accuracy: 0.9714
Epoch 2/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0808 - accuracy: 0.9771 - val_loss: 0.0712 - val_accuracy: 0.9769
Epoch 3/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0628 - accuracy: 0.9815 - val_loss: 0.0568 - val_accuracy: 0.9814
Epoch 4/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0518 - accuracy: 0.9836 - val_loss: 0.0582 - val_accuracy: 0.9815
Epoch 5/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0431 - accuracy: 0.9872 - val_loss: 0.0576 - val_accuracy: 0.9819
Epoch 6/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0365 - accuracy: 0.9889 - val_loss: 0.0546 - val_accuracy: 0.9834
Epoch 7/10
1875/1875 [==============================] - 6s 3ms/step - loss: 0.0308 - accuracy: 0.9905 - val_loss: 0.0545 - val_accuracy: 0.9835
Epoch 8/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0264 - accuracy: 0.9920 - val_loss: 0.0588 - val_accuracy: 0.9827
Epoch 9/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0225 - accuracy: 0.9930 - val_loss: 0.0592 - val_accuracy: 0.9819
Epoch 10/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0207 - accuracy: 0.9933 - val_loss: 0.0580 - val_accuracy: 0.9833
313/313 [==============================] - 1s 2ms/step - loss: 0.0580 - accuracy: 0.9833
[0.05801292881369591, 0.983299970626831]
각 층에 이름을 붙이기
In [17]:
# 입력단 설정
inputs = Input(shape=(28, 28, 1), name='inputs')
# 첫번째 분기
conv = Conv2D(32, (3, 3), activation='relu', name='conv2d')(inputs)
pool = MaxPool2D((2, 2), name='maxpool')(conv)
flat = Flatten(name='flatten')(pool)
# 두번째 분기
flat_inputs = Flatten()(inputs)
# 분기 합치기
concat = Concatenate()([flat, flat_inputs])
digit_outputs = Dense(10, activation='softmax', name='digit_output')(concat)
odd_outputs = Dense(1, activation='sigmoid', name='odd_output')(flat_inputs)
# 모델 설정
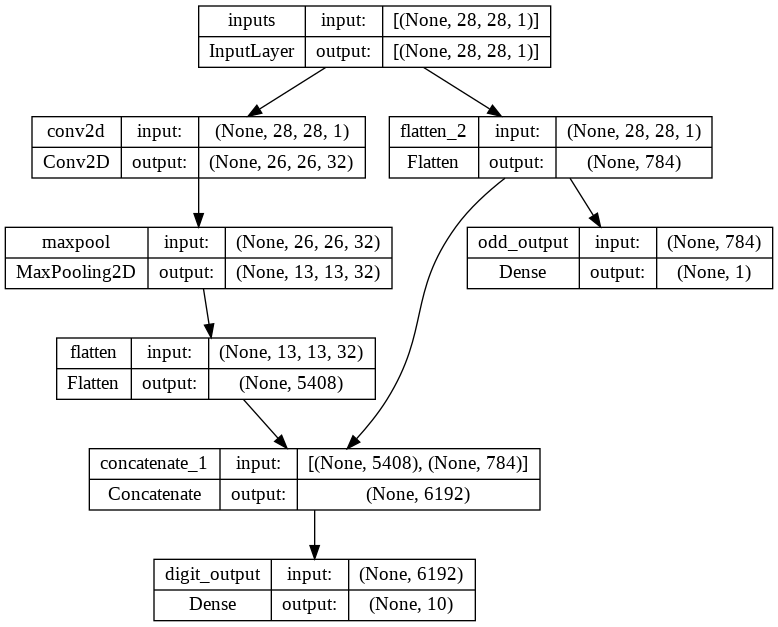
model = Model(inputs=inputs, outputs=[digit_outputs, odd_outputs])
model.summary()
Out [17]:
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0 []
conv2d (Conv2D) (None, 26, 26, 32) 320 ['inputs[0][0]']
maxpool (MaxPooling2D) (None, 13, 13, 32) 0 ['conv2d[0][0]']
flatten (Flatten) (None, 5408) 0 ['maxpool[0][0]']
flatten_2 (Flatten) (None, 784) 0 ['inputs[0][0]']
concatenate_1 (Concatenate) (None, 6192) 0 ['flatten[0][0]',
'flatten_2[0][0]']
digit_output (Dense) (None, 10) 61930 ['concatenate_1[0][0]']
odd_output (Dense) (None, 1) 785 ['flatten_2[0][0]']
==================================================================================================
Total params: 63,035
Trainable params: 63,035
Non-trainable params: 0
__________________________________________________________________________________________________
In [18]:
plot_model(model, show_shapes=True, show_layer_names=True)
Out [18]:
In [19]:
print(model.input)
Out [19]:
KerasTensor(type_spec=TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name='inputs'), name='inputs', description="created by layer 'inputs'")
In [20]:
print(model.output)
Out [20]:
[<KerasTensor: shape=(None, 10) dtype=float32 (created by layer 'digit_output')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'odd_output')>]
In [21]:
model.compile(optimizer='adam',
loss={'digit_output':'sparse_categorical_crossentropy',
'odd_output':'binary_crossentropy'},
loss_weights={'digit_output':1, 'odd_output':0.5},
metrics=['accuracy'])
history = model.fit({'inputs':x_train_in},
{'digit_output':y_train, 'odd_output':y_train_odd},
validation_data=({'inputs':x_test_in},
{'digit_output':y_test, 'odd_output':y_test_odd}),
epochs=10)
Out [21]:
Epoch 1/10
1875/1875 [==============================] - 9s 4ms/step - loss: 0.3631 - digit_output_loss: 0.2027 - odd_output_loss: 0.3207 - digit_output_accuracy: 0.9420 - odd_output_accuracy: 0.8668 - val_loss: 0.2306 - val_digit_output_loss: 0.0932 - val_odd_output_loss: 0.2748 - val_digit_output_accuracy: 0.9709 - val_odd_output_accuracy: 0.8914
Epoch 2/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.2133 - digit_output_loss: 0.0777 - odd_output_loss: 0.2711 - digit_output_accuracy: 0.9776 - odd_output_accuracy: 0.8916 - val_loss: 0.1995 - val_digit_output_loss: 0.0684 - val_odd_output_loss: 0.2622 - val_digit_output_accuracy: 0.9776 - val_odd_output_accuracy: 0.8965
Epoch 3/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1913 - digit_output_loss: 0.0600 - odd_output_loss: 0.2625 - digit_output_accuracy: 0.9823 - odd_output_accuracy: 0.8956 - val_loss: 0.1966 - val_digit_output_loss: 0.0671 - val_odd_output_loss: 0.2589 - val_digit_output_accuracy: 0.9786 - val_odd_output_accuracy: 0.8987
Epoch 4/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1777 - digit_output_loss: 0.0481 - odd_output_loss: 0.2591 - digit_output_accuracy: 0.9857 - odd_output_accuracy: 0.8979 - val_loss: 0.1941 - val_digit_output_loss: 0.0657 - val_odd_output_loss: 0.2568 - val_digit_output_accuracy: 0.9791 - val_odd_output_accuracy: 0.9007
Epoch 5/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1691 - digit_output_loss: 0.0406 - odd_output_loss: 0.2568 - digit_output_accuracy: 0.9876 - odd_output_accuracy: 0.8995 - val_loss: 0.1813 - val_digit_output_loss: 0.0528 - val_odd_output_loss: 0.2570 - val_digit_output_accuracy: 0.9834 - val_odd_output_accuracy: 0.9006
Epoch 6/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1614 - digit_output_loss: 0.0336 - odd_output_loss: 0.2557 - digit_output_accuracy: 0.9891 - odd_output_accuracy: 0.8996 - val_loss: 0.1927 - val_digit_output_loss: 0.0646 - val_odd_output_loss: 0.2563 - val_digit_output_accuracy: 0.9789 - val_odd_output_accuracy: 0.9004
Epoch 7/10
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1559 - digit_output_loss: 0.0286 - odd_output_loss: 0.2546 - digit_output_accuracy: 0.9910 - odd_output_accuracy: 0.8997 - val_loss: 0.1852 - val_digit_output_loss: 0.0572 - val_odd_output_loss: 0.2561 - val_digit_output_accuracy: 0.9834 - val_odd_output_accuracy: 0.9022
Epoch 8/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1509 - digit_output_loss: 0.0239 - odd_output_loss: 0.2540 - digit_output_accuracy: 0.9929 - odd_output_accuracy: 0.9007 - val_loss: 0.1841 - val_digit_output_loss: 0.0558 - val_odd_output_loss: 0.2564 - val_digit_output_accuracy: 0.9846 - val_odd_output_accuracy: 0.9022
Epoch 9/10
1875/1875 [==============================] - 7s 4ms/step - loss: 0.1476 - digit_output_loss: 0.0207 - odd_output_loss: 0.2536 - digit_output_accuracy: 0.9935 - odd_output_accuracy: 0.9010 - val_loss: 0.1816 - val_digit_output_loss: 0.0539 - val_odd_output_loss: 0.2553 - val_digit_output_accuracy: 0.9843 - val_odd_output_accuracy: 0.9030
Epoch 10/10
1875/1875 [==============================] - 9s 5ms/step - loss: 0.1442 - digit_output_loss: 0.0175 - odd_output_loss: 0.2534 - digit_output_accuracy: 0.9944 - odd_output_accuracy: 0.9006 - val_loss: 0.1840 - val_digit_output_loss: 0.0556 - val_odd_output_loss: 0.2566 - val_digit_output_accuracy: 0.9849 - val_odd_output_accuracy: 0.9029
In [22]:
model.evaluate({'inputs':x_test_in}, {'digit_output':y_test, 'odd_output':y_test_odd})
Out [22]:
313/313 [==============================] - 1s 3ms/step - loss: 0.1840 - digit_output_loss: 0.0556 - odd_output_loss: 0.2566 - digit_output_accuracy: 0.9849 - odd_output_accuracy: 0.9029
[0.1839553564786911,
0.05564071610569954,
0.2566293179988861,
0.9848999977111816,
0.902899980545044]
실제 데이터 넣고 확인
In [23]:
digit, odd = model.predict(x_test_in)
Out [23]:
313/313 [==============================] - 1s 2ms/step
In [24]:
np.argmax(np.round(digit[0], 2))
Out [24]:
7
In [25]:
(odd[0] > 0.5).astype(int)
Out [25]:
array([1])
In [26]:
import matplotlib.pyplot as plt
plt.imshow(x_test[0], cmap='gray')
Out [26]:
<matplotlib.image.AxesImage at 0x7f84c24ca790>
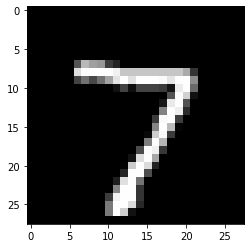
직접쓴 손글씨 테스트
In [27]:
import glob
from PIL import Image
In [28]:
paths = sorted(glob.glob('/content/drive/MyDrive/Colab Notebooks/deep_learning/03_mnist_img/*.png'))
imgs = []
imgs_ori = []
for path in paths:
img = Image.open(path).convert('L')
img = np.reshape(img, (28, 28, 1))
img = (255.0 - (img)) / 255
imgs.append(img)
imgs = np.array(imgs)
In [29]:
imgs.shape
Out [29]:
(10, 28, 28, 1)
In [30]:
digit, odd = model.predict(imgs)
Out [30]:
1/1 [==============================] - 0s 33ms/step
In [31]:
plt.figure(figsize=(13, 5))
for i in range(10):
plt.subplot(2, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.imshow(imgs[i].reshape(28, 28), cmap='gray')
plt.xlabel(f'{np.argmax(np.round(digit[i], 2))} / {"ODD" if odd[i]>0.5 else "EVEN"}')
Out [31]:
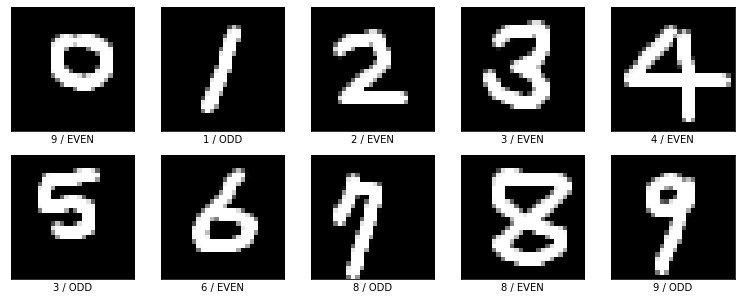
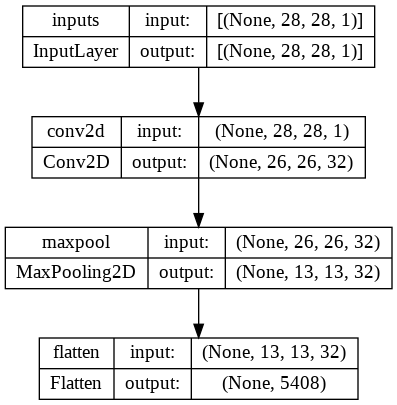
레이어 추출, 재구성하기
In [32]:
base_model_output = model.get_layer('flatten').output
In [33]:
base_model = Model(inputs=model.input, outputs=base_model_output, name='base')
base_model.summary()
plot_model(base_model, show_shapes=True, show_layer_names=True)
Out [33]:
Model: "base"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
=================================================================
Total params: 320
Trainable params: 320
Non-trainable params: 0
_________________________________________________________________
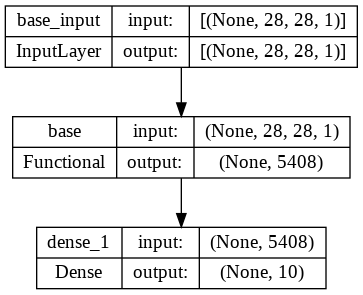
In [34]:
from keras.models import Sequential
digit_model = Sequential([
base_model,
Dense(10, activation='softmax')
])
digit_model.summary()
plot_model(digit_model, show_shapes=True, show_layer_names=True)
Out [34]:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
base (Functional) (None, 5408) 320
dense_1 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,410
Non-trainable params: 0
_________________________________________________________________
In [35]:
digit_model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
history = digit_model.fit(x_train_in, y_train,
validation_data=(x_test_in, y_test),
epochs=5)
Out [35]:
Epoch 1/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.1304 - acc: 0.9640 - val_loss: 0.0644 - val_acc: 0.9794
Epoch 2/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0577 - acc: 0.9825 - val_loss: 0.0535 - val_acc: 0.9827
Epoch 3/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0434 - acc: 0.9867 - val_loss: 0.0520 - val_acc: 0.9832
Epoch 4/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0354 - acc: 0.9891 - val_loss: 0.0504 - val_acc: 0.9841
Epoch 5/5
1875/1875 [==============================] - 5s 3ms/step - loss: 0.0285 - acc: 0.9912 - val_loss: 0.0484 - val_acc: 0.9847
기존에 학습된 가중치에서 시작하므로 처음부터 학습한 것보다 정확도가 높게 나온다.
- 가중치 보정
In [36]:
base_model_frozen = Model(inputs=model.input, outputs=base_model_output, name='base_frozen')
base_model_frozen.trainable=False # 모두 동결
base_model_frozen.summary()
Out [36]:
Model: "base_frozen"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
=================================================================
Total params: 320
Trainable params: 0
Non-trainable params: 320
_________________________________________________________________
In [37]:
# 분류기 설정
dense_output = Dense(10, activation='softmax')(base_model_frozen.output)
digit_model_frozen = Model(inputs=base_model_frozen.input, outputs=dense_output)
digit_model_frozen.summary()
Out [37]:
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
dense_2 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,090
Non-trainable params: 320
_________________________________________________________________
In [38]:
digit_model_frozen.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['acc'])
history = digit_model_frozen.fit(x_train_in, y_train,
validation_data=(x_test_in, y_test),
epochs=10)
Out [38]:
Epoch 1/10
1875/1875 [==============================] - 5s 3ms/step - loss: 0.1162 - acc: 0.9693 - val_loss: 0.0558 - val_acc: 0.9813
Epoch 2/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0490 - acc: 0.9853 - val_loss: 0.0487 - val_acc: 0.9842
Epoch 3/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0378 - acc: 0.9882 - val_loss: 0.0525 - val_acc: 0.9829
Epoch 4/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0288 - acc: 0.9914 - val_loss: 0.0477 - val_acc: 0.9842
Epoch 5/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0237 - acc: 0.9925 - val_loss: 0.0487 - val_acc: 0.9848
Epoch 6/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0195 - acc: 0.9941 - val_loss: 0.0551 - val_acc: 0.9835
Epoch 7/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0159 - acc: 0.9952 - val_loss: 0.0519 - val_acc: 0.9837
Epoch 8/10
1875/1875 [==============================] - 4s 2ms/step - loss: 0.0133 - acc: 0.9965 - val_loss: 0.0527 - val_acc: 0.9845
Epoch 9/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0118 - acc: 0.9964 - val_loss: 0.0582 - val_acc: 0.9826
Epoch 10/10
1875/1875 [==============================] - 5s 2ms/step - loss: 0.0098 - acc: 0.9972 - val_loss: 0.0578 - val_acc: 0.9846
- 층 하나만 활성화
In [39]:
digit_model_frozen.get_layer('conv2d').trainable = True
In [40]:
digit_model_frozen.summary()
Out [40]:
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
inputs (InputLayer) [(None, 28, 28, 1)] 0
conv2d (Conv2D) (None, 26, 26, 32) 320
maxpool (MaxPooling2D) (None, 13, 13, 32) 0
flatten (Flatten) (None, 5408) 0
dense_2 (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,410
Non-trainable params: 0
_________________________________________________________________
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기