
Deep Learning (16) - CNN / 유로 위성사진 데이터
유로 위성사진 데이터
In [1]:
import tensorflow as tf
import numpy as np
import json
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds
데이터 확인하기
In [2]:
data_dir = 'dataset/'
(train_ds, valid_ds), info = tfds.load('eurosat/rgb',
split=['train[:80%]','train[80%:]'],
shuffle_files=True, as_supervised=True,
with_info=True, data_dir=data_dir)
Out [2]:
Downloading and preparing dataset 89.91 MiB (download: 89.91 MiB, generated: Unknown size, total: 89.91 MiB) to dataset/eurosat/rgb/2.0.0...
Dl Completed...: 0 url [00:00, ? url/s]
Dl Size...: 0 MiB [00:00, ? MiB/s]
Extraction completed...: 0 file [00:00, ? file/s]
Generating splits...: 0%| | 0/1 [00:00<?, ? splits/s]
Generating train examples...: 0%| | 0/27000 [00:00<?, ? examples/s]
Shuffling dataset/eurosat/rgb/2.0.0.incompleteWH3BFP/eurosat-train.tfrecord*...: 0%| | 0/27000 [00:…
Dataset eurosat downloaded and prepared to dataset/eurosat/rgb/2.0.0. Subsequent calls will reuse this data.
In [3]:
train_ds, valid_ds
Out [3]:
(<PrefetchDataset element_spec=(TensorSpec(shape=(64, 64, 3), dtype=tf.uint8, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))>,
<PrefetchDataset element_spec=(TensorSpec(shape=(64, 64, 3), dtype=tf.uint8, name=None), TensorSpec(shape=(), dtype=tf.int64, name=None))>)
In [4]:
info
Out [4]:
tfds.core.DatasetInfo(
name='eurosat',
full_name='eurosat/rgb/2.0.0',
description="""
EuroSAT dataset is based on Sentinel-2 satellite images covering 13 spectral
bands and consisting of 10 classes with 27000 labeled and
geo-referenced samples.
Two datasets are offered:
- rgb: Contains only the optical R, G, B frequency bands encoded as JPEG image.
- all: Contains all 13 bands in the original value range (float32).
URL: https://github.com/phelber/eurosat
""",
config_description="""
Sentinel-2 RGB channels
""",
homepage='https://github.com/phelber/eurosat',
data_path='dataset/eurosat/rgb/2.0.0',
file_format=tfrecord,
download_size=89.91 MiB,
dataset_size=89.50 MiB,
features=FeaturesDict({
'filename': Text(shape=(), dtype=tf.string),
'image': Image(shape=(64, 64, 3), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=10),
}),
supervised_keys=('image', 'label'),
disable_shuffling=False,
splits={
'train': <SplitInfo num_examples=27000, num_shards=1>,
},
citation="""@misc{helber2017eurosat,
title={EuroSAT: A Novel Dataset and Deep Learning Benchmark for Land Use and Land Cover Classification},
author={Patrick Helber and Benjamin Bischke and Andreas Dengel and Damian Borth},
year={2017},
eprint={1709.00029},
archivePrefix={arXiv},
primaryClass={cs.CV}
}""",
)
In [5]:
tfds.show_examples(train_ds, info)
Out [5]:


In [6]:
tfds.as_dataframe(valid_ds.take(5), info)
Out [6]:
| image | label | |
|---|---|---|
| 0 |  |
5 (Pasture) |
| 1 |  |
7 (Residential) |
| 2 |  |
0 (AnnualCrop) |
| 3 |  |
1 (Forest) |
| 4 |  |
0 (AnnualCrop) |
In [7]:
# 레이블 클래스의 가짓수
num_classes = info.features['label'].num_classes
num_classes
Out [7]:
10
In [8]:
# 레이블 번호에 해당하는 클래스 이름 반환
print(info.features['label'].int2str(8))
Out [8]:
River
데이터 전처리
In [9]:
batch_size = 64 # 한번에 작업할 수
buffer_size = 1000 # 작업 대기중인 수
# 사전 전처리 함수
def preprocess_data(image, label):
image = tf.cast(image, tf.float32) / 255.
return image, label
train_data = train_ds.map(preprocess_data, num_parallel_calls=tf.data.AUTOTUNE)
valid_data = valid_ds.map(preprocess_data, num_parallel_calls=tf.data.AUTOTUNE)
# num_parallel_calls: 병렬처리로 속도가 빨라짐
train_data = train_data.shuffle(buffer_size).batch(batch_size).prefetch(tf.data.AUTOTUNE)
valid_data = valid_data.batch(batch_size).cache().prefetch(tf.data.AUTOTUNE)
모델 구성
In [10]:
from keras.models import Sequential
from keras.layers import Dense, Flatten, Dropout, Conv2D, MaxPooling2D, BatchNormalization
def build_model():
model = Sequential([
BatchNormalization(),
Conv2D(32, (3, 3), padding='same', activation='relu'),
MaxPooling2D((2, 2)),
BatchNormalization(),
Conv2D(64, (3, 3), padding='same', activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.3),
Dense(64, activation='relu'),
Dropout(0.3),
Dense(num_classes, activation='softmax')
])
return model
model = build_model()
In [11]:
# model.summary()
In [12]:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
In [13]:
history = model.fit(train_data, validation_data=valid_data, epochs=50)
Out [13]:
Epoch 1/50
338/338 [==============================] - 16s 20ms/step - loss: 1.6098 - acc: 0.4350 - val_loss: 1.6729 - val_acc: 0.4257
Epoch 2/50
338/338 [==============================] - 4s 11ms/step - loss: 1.2250 - acc: 0.5633 - val_loss: 0.8213 - val_acc: 0.7085
Epoch 3/50
338/338 [==============================] - 4s 12ms/step - loss: 1.0656 - acc: 0.6186 - val_loss: 0.7350 - val_acc: 0.7559
Epoch 4/50
338/338 [==============================] - 5s 16ms/step - loss: 0.9505 - acc: 0.6578 - val_loss: 0.8194 - val_acc: 0.7106
Epoch 5/50
338/338 [==============================] - 4s 11ms/step - loss: 0.8850 - acc: 0.6857 - val_loss: 0.6531 - val_acc: 0.7859
Epoch 6/50
338/338 [==============================] - 4s 12ms/step - loss: 0.7965 - acc: 0.7178 - val_loss: 0.5653 - val_acc: 0.8109
Epoch 7/50
338/338 [==============================] - 4s 11ms/step - loss: 0.7573 - acc: 0.7371 - val_loss: 0.5696 - val_acc: 0.8176
Epoch 8/50
338/338 [==============================] - 6s 16ms/step - loss: 0.6774 - acc: 0.7618 - val_loss: 0.5102 - val_acc: 0.8246
Epoch 9/50
338/338 [==============================] - 4s 12ms/step - loss: 0.6281 - acc: 0.7855 - val_loss: 0.5019 - val_acc: 0.8237
Epoch 10/50
338/338 [==============================] - 4s 12ms/step - loss: 0.5863 - acc: 0.8058 - val_loss: 0.4770 - val_acc: 0.8422
Epoch 11/50
338/338 [==============================] - 4s 12ms/step - loss: 0.5334 - acc: 0.8200 - val_loss: 0.5515 - val_acc: 0.8235
Epoch 12/50
338/338 [==============================] - 4s 12ms/step - loss: 0.4988 - acc: 0.8345 - val_loss: 0.4245 - val_acc: 0.8611
Epoch 13/50
338/338 [==============================] - 4s 12ms/step - loss: 0.4673 - acc: 0.8445 - val_loss: 0.3980 - val_acc: 0.8715
Epoch 14/50
338/338 [==============================] - 5s 14ms/step - loss: 0.4328 - acc: 0.8513 - val_loss: 0.4120 - val_acc: 0.8685
Epoch 15/50
338/338 [==============================] - 4s 11ms/step - loss: 0.4047 - acc: 0.8666 - val_loss: 0.4024 - val_acc: 0.8694
Epoch 16/50
338/338 [==============================] - 4s 12ms/step - loss: 0.3720 - acc: 0.8719 - val_loss: 0.4456 - val_acc: 0.8533
Epoch 17/50
338/338 [==============================] - 4s 11ms/step - loss: 0.3566 - acc: 0.8810 - val_loss: 0.3983 - val_acc: 0.8761
Epoch 18/50
338/338 [==============================] - 4s 11ms/step - loss: 0.3377 - acc: 0.8846 - val_loss: 0.4407 - val_acc: 0.8652
Epoch 19/50
338/338 [==============================] - 4s 12ms/step - loss: 0.3159 - acc: 0.8919 - val_loss: 0.4246 - val_acc: 0.8657
Epoch 20/50
338/338 [==============================] - 4s 11ms/step - loss: 0.3036 - acc: 0.8966 - val_loss: 0.4562 - val_acc: 0.8567
Epoch 21/50
338/338 [==============================] - 4s 11ms/step - loss: 0.2814 - acc: 0.8996 - val_loss: 0.4614 - val_acc: 0.8715
Epoch 22/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2779 - acc: 0.9057 - val_loss: 0.4153 - val_acc: 0.8807
Epoch 23/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2649 - acc: 0.9080 - val_loss: 0.3853 - val_acc: 0.8828
Epoch 24/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2552 - acc: 0.9139 - val_loss: 0.4657 - val_acc: 0.8643
Epoch 25/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2432 - acc: 0.9166 - val_loss: 0.4436 - val_acc: 0.8789
Epoch 26/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2335 - acc: 0.9194 - val_loss: 0.4250 - val_acc: 0.8861
Epoch 27/50
338/338 [==============================] - 4s 11ms/step - loss: 0.2355 - acc: 0.9185 - val_loss: 0.4658 - val_acc: 0.8769
Epoch 28/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2349 - acc: 0.9195 - val_loss: 0.4541 - val_acc: 0.8743
Epoch 29/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2247 - acc: 0.9237 - val_loss: 0.4748 - val_acc: 0.8828
Epoch 30/50
338/338 [==============================] - 4s 11ms/step - loss: 0.2181 - acc: 0.9250 - val_loss: 0.4536 - val_acc: 0.8778
Epoch 31/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2236 - acc: 0.9225 - val_loss: 0.5598 - val_acc: 0.8561
Epoch 32/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2077 - acc: 0.9293 - val_loss: 0.4987 - val_acc: 0.8750
Epoch 33/50
338/338 [==============================] - 4s 12ms/step - loss: 0.2044 - acc: 0.9311 - val_loss: 0.5110 - val_acc: 0.8750
Epoch 34/50
338/338 [==============================] - 4s 11ms/step - loss: 0.1833 - acc: 0.9374 - val_loss: 0.4934 - val_acc: 0.8731
Epoch 35/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1943 - acc: 0.9355 - val_loss: 0.4160 - val_acc: 0.8907
Epoch 36/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1857 - acc: 0.9371 - val_loss: 0.4531 - val_acc: 0.8848
Epoch 37/50
338/338 [==============================] - 4s 11ms/step - loss: 0.1678 - acc: 0.9424 - val_loss: 0.4573 - val_acc: 0.8807
Epoch 38/50
338/338 [==============================] - 4s 11ms/step - loss: 0.1571 - acc: 0.9445 - val_loss: 0.4791 - val_acc: 0.8843
Epoch 39/50
338/338 [==============================] - 4s 11ms/step - loss: 0.1729 - acc: 0.9422 - val_loss: 0.5089 - val_acc: 0.8776
Epoch 40/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1575 - acc: 0.9469 - val_loss: 0.4956 - val_acc: 0.8830
Epoch 41/50
338/338 [==============================] - 4s 11ms/step - loss: 0.1615 - acc: 0.9463 - val_loss: 0.4939 - val_acc: 0.8833
Epoch 42/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1489 - acc: 0.9499 - val_loss: 0.5382 - val_acc: 0.8720
Epoch 43/50
338/338 [==============================] - 4s 11ms/step - loss: 0.1482 - acc: 0.9499 - val_loss: 0.4924 - val_acc: 0.8835
Epoch 44/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1469 - acc: 0.9510 - val_loss: 0.5691 - val_acc: 0.8785
Epoch 45/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1474 - acc: 0.9493 - val_loss: 0.5530 - val_acc: 0.8804
Epoch 46/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1329 - acc: 0.9544 - val_loss: 0.4845 - val_acc: 0.8835
Epoch 47/50
338/338 [==============================] - 4s 11ms/step - loss: 0.1376 - acc: 0.9514 - val_loss: 0.5898 - val_acc: 0.8796
Epoch 48/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1376 - acc: 0.9526 - val_loss: 0.4842 - val_acc: 0.8843
Epoch 49/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1464 - acc: 0.9503 - val_loss: 0.5540 - val_acc: 0.8724
Epoch 50/50
338/338 [==============================] - 4s 12ms/step - loss: 0.1322 - acc: 0.9544 - val_loss: 0.6168 - val_acc: 0.8633
In [14]:
def plot_loss_acc(history, epoch):
loss, val_loss = history.history['loss'], history.history['val_loss']
acc, val_acc = history.history['acc'], history.history['val_acc']
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(range(1, epoch+1), loss, label='train loss')
axes[0].plot(range(1, epoch+1), val_loss, label='valid loss')
axes[0].legend(loc='best')
axes[0].set_title('Loss')
axes[1].plot(range(1, epoch+1), acc, label='train acc')
axes[1].plot(range(1, epoch+1), val_acc, label='valid acc')
axes[1].legend(loc='best')
axes[1].set_title('Accuracy')
plt.show()
plot_loss_acc(history, 50)
Out [14]:
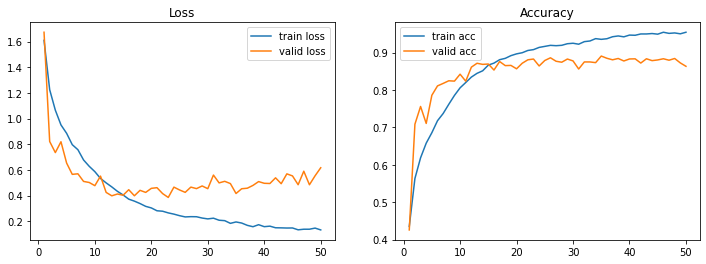
이미지 증가
In [15]:
image_batch, label_batch = next(iter(train_data.take(1))) # 1개를 가져오지만 batch_size하나 만큼 가져옴
image = image_batch[0]
label = label_batch[0].numpy()
plt.imshow(image)
plt.title(info.features['label'].int2str(label))
Out [15]:
Text(0.5, 1.0, 'Residential')

In [16]:
def plot_augmentation(original, augmented):
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].imshow(original)
axes[0].set_title('Original')
axes[1].imshow(augmented)
axes[1].set_title('Augmented')
plt.show()
In [17]:
# 좌우 뒤집기
plot_augmentation(image, tf.image.flip_left_right(image))
Out [17]:

In [18]:
# 상하 뒤집기
plot_augmentation(image, tf.image.flip_up_down(image))
Out [18]:

In [19]:
# 회전
plot_augmentation(image, tf.image.rot90(image))
Out [19]:

In [20]:
# 상하좌우 뒤집기
plot_augmentation(image, tf.image.transpose(image))
Out [20]:

In [21]:
# 잘라내기
plot_augmentation(image, tf.image.central_crop(image, central_fraction=0.6))
Out [21]:

In [22]:
# 사이즈 변경, 채워넣기
plot_augmentation(image, tf.image.resize_with_crop_or_pad(image, 64+20, 64+20))
Out [22]:

In [23]:
# 밝기
plot_augmentation(image, tf.image.adjust_brightness(image, 0.3))
Out [23]:
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

In [24]:
# 채도
plot_augmentation(image, tf.image.adjust_saturation(image, 0.5))
Out [24]:

In [25]:
# 대비
plot_augmentation(image, tf.image.adjust_contrast(image, 2))
Out [25]:
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

In [26]:
# 무작위 잘라내기
plot_augmentation(image, tf.image.random_crop(image, size=[32, 32, 3]))
Out [26]:

In [27]:
# 무작위 밝기
plot_augmentation(image, tf.image.random_brightness(image, 0.3))
Out [27]:

이미지 증가 데이터 전처리
In [28]:
batch_size = 64 # 한번에 작업할 수
buffer_size = 1000 # 작업 대기중인 수
# 사전 전처리 함수
def preprocess_data(image, label):
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
iamge = tf.image.random_brightness(image, max_delta=0.3)
image = tf.image.random_contrast(image, lower=0.5, upper=1.5)
image = tf.cast(image, tf.float32) / 255.
return image, label
train_aug = train_ds.map(preprocess_data, num_parallel_calls=tf.data.AUTOTUNE)
valid_aug = valid_ds.map(preprocess_data, num_parallel_calls=tf.data.AUTOTUNE)
# num_parallel_calls: 병렬처리로 속도가 빨라짐
train_aug = train_aug.shuffle(buffer_size).batch(batch_size).prefetch(tf.data.AUTOTUNE)
valid_aug = valid_aug.batch(batch_size).cache().prefetch(tf.data.AUTOTUNE)
In [29]:
image_batch, label_batch = next(iter(train_aug.take(1)))
image = image_batch[0]
label = label_batch[0].numpy()
plt.imshow(image)
plt.title(info.features['label'].int2str(label))
Out [29]:
Text(0.5, 1.0, 'Residential')

In [30]:
def plot_loss_acc(history, epoch):
loss, val_loss = history.history['loss'], history.history['val_loss']
acc, val_acc = history.history['acc'], history.history['val_acc']
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(range(1, epoch+1), loss, label='train loss')
axes[0].plot(range(1, epoch+1), val_loss, label='valid loss')
axes[0].legend(loc='best')
axes[0].set_title('Loss')
axes[1].plot(range(1, epoch+1), acc, label='train acc')
axes[1].plot(range(1, epoch+1), val_acc, label='valid acc')
axes[1].legend(loc='best')
axes[1].set_title('Accuracy')
plt.show()
In [31]:
aug_model = build_model()
aug_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
aug_history = aug_model.fit(train_aug, validation_data=valid_aug, epochs=50)
Out [31]:
Epoch 1/50
338/338 [==============================] - 7s 19ms/step - loss: 1.7669 - acc: 0.3859 - val_loss: 1.5681 - val_acc: 0.4769
Epoch 2/50
338/338 [==============================] - 6s 16ms/step - loss: 1.3763 - acc: 0.5230 - val_loss: 1.0838 - val_acc: 0.6396
Epoch 3/50
338/338 [==============================] - 5s 16ms/step - loss: 1.1953 - acc: 0.5861 - val_loss: 0.9062 - val_acc: 0.7063
Epoch 4/50
338/338 [==============================] - 6s 16ms/step - loss: 1.0847 - acc: 0.6273 - val_loss: 0.8803 - val_acc: 0.7007
Epoch 5/50
338/338 [==============================] - 6s 17ms/step - loss: 1.0088 - acc: 0.6507 - val_loss: 0.8254 - val_acc: 0.7309
Epoch 6/50
338/338 [==============================] - 6s 16ms/step - loss: 0.9514 - acc: 0.6707 - val_loss: 0.6866 - val_acc: 0.7796
Epoch 7/50
338/338 [==============================] - 6s 16ms/step - loss: 0.8968 - acc: 0.6898 - val_loss: 0.6950 - val_acc: 0.7685
Epoch 8/50
338/338 [==============================] - 6s 16ms/step - loss: 0.8393 - acc: 0.7121 - val_loss: 0.6425 - val_acc: 0.7809
Epoch 9/50
338/338 [==============================] - 6s 16ms/step - loss: 0.8061 - acc: 0.7261 - val_loss: 0.5906 - val_acc: 0.7952
Epoch 10/50
338/338 [==============================] - 6s 16ms/step - loss: 0.7700 - acc: 0.7371 - val_loss: 0.5588 - val_acc: 0.8113
Epoch 11/50
338/338 [==============================] - 6s 16ms/step - loss: 0.7326 - acc: 0.7499 - val_loss: 0.5961 - val_acc: 0.8091
Epoch 12/50
338/338 [==============================] - 6s 16ms/step - loss: 0.7191 - acc: 0.7563 - val_loss: 0.5548 - val_acc: 0.8137
Epoch 13/50
338/338 [==============================] - 6s 17ms/step - loss: 0.6736 - acc: 0.7739 - val_loss: 0.5060 - val_acc: 0.8459
Epoch 14/50
338/338 [==============================] - 6s 16ms/step - loss: 0.6637 - acc: 0.7777 - val_loss: 0.5059 - val_acc: 0.8298
Epoch 15/50
338/338 [==============================] - 5s 16ms/step - loss: 0.6293 - acc: 0.7889 - val_loss: 0.6643 - val_acc: 0.7800
Epoch 16/50
338/338 [==============================] - 6s 16ms/step - loss: 0.6287 - acc: 0.7885 - val_loss: 0.4795 - val_acc: 0.8409
Epoch 17/50
338/338 [==============================] - 6s 17ms/step - loss: 0.5891 - acc: 0.8025 - val_loss: 0.4486 - val_acc: 0.8569
Epoch 18/50
338/338 [==============================] - 6s 17ms/step - loss: 0.5808 - acc: 0.8049 - val_loss: 0.4924 - val_acc: 0.8324
Epoch 19/50
338/338 [==============================] - 6s 16ms/step - loss: 0.5637 - acc: 0.8136 - val_loss: 0.4122 - val_acc: 0.8696
Epoch 20/50
338/338 [==============================] - 6s 17ms/step - loss: 0.5505 - acc: 0.8143 - val_loss: 0.4265 - val_acc: 0.8646
Epoch 21/50
338/338 [==============================] - 6s 16ms/step - loss: 0.5372 - acc: 0.8202 - val_loss: 0.3674 - val_acc: 0.8772
Epoch 22/50
338/338 [==============================] - 6s 16ms/step - loss: 0.5284 - acc: 0.8212 - val_loss: 0.3872 - val_acc: 0.8715
Epoch 23/50
338/338 [==============================] - 6s 16ms/step - loss: 0.5211 - acc: 0.8280 - val_loss: 0.3944 - val_acc: 0.8646
Epoch 24/50
338/338 [==============================] - 6s 16ms/step - loss: 0.5109 - acc: 0.8294 - val_loss: 0.3958 - val_acc: 0.8761
Epoch 25/50
338/338 [==============================] - 6s 17ms/step - loss: 0.4883 - acc: 0.8356 - val_loss: 0.4004 - val_acc: 0.8687
Epoch 26/50
338/338 [==============================] - 6s 16ms/step - loss: 0.4964 - acc: 0.8363 - val_loss: 0.3533 - val_acc: 0.8843
Epoch 27/50
338/338 [==============================] - 6s 16ms/step - loss: 0.4790 - acc: 0.8430 - val_loss: 0.4282 - val_acc: 0.8635
Epoch 28/50
338/338 [==============================] - 6s 16ms/step - loss: 0.4690 - acc: 0.8423 - val_loss: 0.4033 - val_acc: 0.8687
Epoch 29/50
338/338 [==============================] - 5s 16ms/step - loss: 0.4607 - acc: 0.8459 - val_loss: 0.3547 - val_acc: 0.8809
Epoch 30/50
338/338 [==============================] - 6s 16ms/step - loss: 0.4643 - acc: 0.8462 - val_loss: 0.3668 - val_acc: 0.8772
Epoch 31/50
338/338 [==============================] - 6s 16ms/step - loss: 0.4428 - acc: 0.8543 - val_loss: 0.3736 - val_acc: 0.8728
Epoch 32/50
338/338 [==============================] - 6s 19ms/step - loss: 0.4356 - acc: 0.8575 - val_loss: 0.3546 - val_acc: 0.8856
Epoch 33/50
338/338 [==============================] - 6s 16ms/step - loss: 0.4185 - acc: 0.8640 - val_loss: 0.3503 - val_acc: 0.8809
Epoch 34/50
338/338 [==============================] - 6s 16ms/step - loss: 0.4127 - acc: 0.8678 - val_loss: 0.3714 - val_acc: 0.8811
Epoch 35/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3816 - acc: 0.8786 - val_loss: 0.3321 - val_acc: 0.8885
Epoch 36/50
338/338 [==============================] - 6s 17ms/step - loss: 0.3839 - acc: 0.8795 - val_loss: 0.3118 - val_acc: 0.8939
Epoch 37/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3620 - acc: 0.8875 - val_loss: 0.3187 - val_acc: 0.8983
Epoch 38/50
338/338 [==============================] - 6s 17ms/step - loss: 0.3685 - acc: 0.8847 - val_loss: 0.3733 - val_acc: 0.8815
Epoch 39/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3579 - acc: 0.8883 - val_loss: 0.3060 - val_acc: 0.9002
Epoch 40/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3679 - acc: 0.8881 - val_loss: 0.3043 - val_acc: 0.8985
Epoch 41/50
338/338 [==============================] - 6s 17ms/step - loss: 0.3344 - acc: 0.8956 - val_loss: 0.3022 - val_acc: 0.9013
Epoch 42/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3266 - acc: 0.9007 - val_loss: 0.2938 - val_acc: 0.9031
Epoch 43/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3098 - acc: 0.9018 - val_loss: 0.4057 - val_acc: 0.8670
Epoch 44/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3142 - acc: 0.9041 - val_loss: 0.2914 - val_acc: 0.9039
Epoch 45/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3135 - acc: 0.9020 - val_loss: 0.3228 - val_acc: 0.8946
Epoch 46/50
338/338 [==============================] - 6s 16ms/step - loss: 0.2909 - acc: 0.9120 - val_loss: 0.2895 - val_acc: 0.9048
Epoch 47/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3029 - acc: 0.9108 - val_loss: 0.3479 - val_acc: 0.8894
Epoch 48/50
338/338 [==============================] - 6s 16ms/step - loss: 0.2947 - acc: 0.9101 - val_loss: 0.3748 - val_acc: 0.8757
Epoch 49/50
338/338 [==============================] - 6s 16ms/step - loss: 0.3031 - acc: 0.9077 - val_loss: 0.2988 - val_acc: 0.9026
Epoch 50/50
338/338 [==============================] - 6s 17ms/step - loss: 0.2886 - acc: 0.9120 - val_loss: 0.2838 - val_acc: 0.9041
In [32]:
plot_loss_acc(aug_history, 50)
Out [32]:
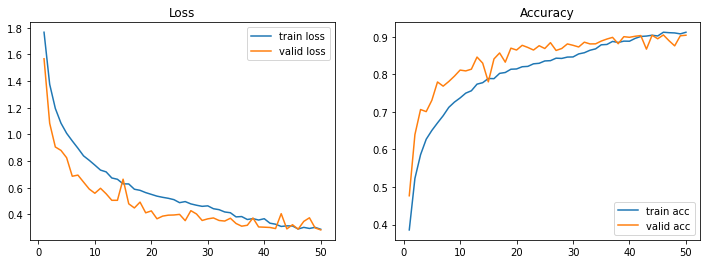
과적합이 늦게 일어난다!
전이 학습
In [33]:
from keras.applications import ResNet50V2
from keras.utils import plot_model
pre_trained_base = ResNet50V2()
plot_model(pre_trained_base, show_shapes=True, show_layer_names=True) # input이 사용하려는 자료와 shape이 다름
Out [33]:
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/resnet/resnet50v2_weights_tf_dim_ordering_tf_kernels.h5
102869336/102869336 [==============================] - 5s 0us/step

In [34]:
pre_trained_base = ResNet50V2(include_top=False, input_shape=[64, 64, 3])
pre_trained_base.trainable = False # 학습하지 않게 모두 동결
plot_model(pre_trained_base, show_shapes=True, show_layer_names=True)
Out [34]:
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/resnet/resnet50v2_weights_tf_dim_ordering_tf_kernels_notop.h5
94668760/94668760 [==============================] - 5s 0us/step

In [35]:
pre_trained_base.summary() # Trainable params: 0 확인!
Out [35]:
Model: "resnet50v2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 64, 64, 3)] 0 []
conv1_pad (ZeroPadding2D) (None, 70, 70, 3) 0 ['input_2[0][0]']
...
post_bn (BatchNormalization) (None, 2, 2, 2048) 8192 ['conv5_block3_out[0][0]']
post_relu (Activation) (None, 2, 2, 2048) 0 ['post_bn[0][0]']
==================================================================================================
Total params: 23,564,800
Trainable params: 0
Non-trainable params: 23,564,800
__________________________________________________________________________________________________
In [36]:
def build_transfer_model():
model = Sequential([
pre_trained_base,
Flatten(),
Dense(128, activation='relu'),
Dropout(0.3),
Dense(64, activation='relu'),
Dropout(0.3),
Dense(num_classes, activation='softmax')
])
return model
In [37]:
t_model = build_transfer_model()
t_model.summary()
Out [37]:
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resnet50v2 (Functional) (None, 2, 2, 2048) 23564800
flatten_2 (Flatten) (None, 8192) 0
dense_6 (Dense) (None, 128) 1048704
dropout_4 (Dropout) (None, 128) 0
dense_7 (Dense) (None, 64) 8256
dropout_5 (Dropout) (None, 64) 0
dense_8 (Dense) (None, 10) 650
=================================================================
Total params: 24,622,410
Trainable params: 1,057,610
Non-trainable params: 23,564,800
_________________________________________________________________
In [38]:
t_model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
t_history = t_model.fit(train_aug, validation_data=valid_aug, epochs=50)
plot_loss_acc(t_history, 50)
Out [38]:
Epoch 1/50
338/338 [==============================] - 15s 34ms/step - loss: 1.0016 - acc: 0.6780 - val_loss: 0.5930 - val_acc: 0.8100
Epoch 2/50
338/338 [==============================] - 10s 29ms/step - loss: 0.7142 - acc: 0.7699 - val_loss: 0.5126 - val_acc: 0.8289
Epoch 3/50
338/338 [==============================] - 10s 30ms/step - loss: 0.6194 - acc: 0.8004 - val_loss: 0.4993 - val_acc: 0.8324
Epoch 4/50
338/338 [==============================] - 10s 28ms/step - loss: 0.5752 - acc: 0.8121 - val_loss: 0.4632 - val_acc: 0.8454
Epoch 5/50
338/338 [==============================] - 10s 28ms/step - loss: 0.5562 - acc: 0.8243 - val_loss: 0.4628 - val_acc: 0.8428
Epoch 6/50
338/338 [==============================] - 9s 28ms/step - loss: 0.5183 - acc: 0.8287 - val_loss: 0.4425 - val_acc: 0.8502
Epoch 7/50
338/338 [==============================] - 9s 27ms/step - loss: 0.5005 - acc: 0.8366 - val_loss: 0.4457 - val_acc: 0.8493
Epoch 8/50
338/338 [==============================] - 10s 28ms/step - loss: 0.4867 - acc: 0.8389 - val_loss: 0.4337 - val_acc: 0.8565
Epoch 9/50
338/338 [==============================] - 10s 28ms/step - loss: 0.4733 - acc: 0.8458 - val_loss: 0.4255 - val_acc: 0.8552
Epoch 10/50
338/338 [==============================] - 9s 28ms/step - loss: 0.4597 - acc: 0.8497 - val_loss: 0.4253 - val_acc: 0.8543
Epoch 11/50
338/338 [==============================] - 10s 28ms/step - loss: 0.4468 - acc: 0.8555 - val_loss: 0.4156 - val_acc: 0.8628
Epoch 12/50
338/338 [==============================] - 9s 28ms/step - loss: 0.4328 - acc: 0.8578 - val_loss: 0.4122 - val_acc: 0.8644
Epoch 13/50
338/338 [==============================] - 10s 28ms/step - loss: 0.4283 - acc: 0.8585 - val_loss: 0.4202 - val_acc: 0.8613
Epoch 14/50
338/338 [==============================] - 10s 28ms/step - loss: 0.4303 - acc: 0.8582 - val_loss: 0.4009 - val_acc: 0.8600
Epoch 15/50
338/338 [==============================] - 9s 28ms/step - loss: 0.4146 - acc: 0.8609 - val_loss: 0.4205 - val_acc: 0.8578
Epoch 16/50
338/338 [==============================] - 9s 28ms/step - loss: 0.4083 - acc: 0.8639 - val_loss: 0.4086 - val_acc: 0.8631
Epoch 17/50
338/338 [==============================] - 10s 28ms/step - loss: 0.4000 - acc: 0.8659 - val_loss: 0.4067 - val_acc: 0.8646
Epoch 18/50
338/338 [==============================] - 10s 30ms/step - loss: 0.3889 - acc: 0.8697 - val_loss: 0.4201 - val_acc: 0.8572
Epoch 19/50
338/338 [==============================] - 9s 28ms/step - loss: 0.4004 - acc: 0.8691 - val_loss: 0.4015 - val_acc: 0.8696
Epoch 20/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3861 - acc: 0.8719 - val_loss: 0.4062 - val_acc: 0.8648
Epoch 21/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3761 - acc: 0.8728 - val_loss: 0.3992 - val_acc: 0.8672
Epoch 22/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3756 - acc: 0.8733 - val_loss: 0.4038 - val_acc: 0.8661
Epoch 23/50
338/338 [==============================] - 10s 29ms/step - loss: 0.3728 - acc: 0.8763 - val_loss: 0.4002 - val_acc: 0.8670
Epoch 24/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3657 - acc: 0.8786 - val_loss: 0.4088 - val_acc: 0.8615
Epoch 25/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3561 - acc: 0.8792 - val_loss: 0.4191 - val_acc: 0.8639
Epoch 26/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3589 - acc: 0.8780 - val_loss: 0.4056 - val_acc: 0.8648
Epoch 27/50
338/338 [==============================] - 9s 27ms/step - loss: 0.3496 - acc: 0.8859 - val_loss: 0.4164 - val_acc: 0.8637
Epoch 28/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3533 - acc: 0.8797 - val_loss: 0.4011 - val_acc: 0.8696
Epoch 29/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3438 - acc: 0.8840 - val_loss: 0.4050 - val_acc: 0.8656
Epoch 30/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3462 - acc: 0.8847 - val_loss: 0.3931 - val_acc: 0.8752
Epoch 31/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3358 - acc: 0.8868 - val_loss: 0.4013 - val_acc: 0.8711
Epoch 32/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3286 - acc: 0.8892 - val_loss: 0.4043 - val_acc: 0.8704
Epoch 33/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3313 - acc: 0.8894 - val_loss: 0.4089 - val_acc: 0.8696
Epoch 34/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3311 - acc: 0.8874 - val_loss: 0.4122 - val_acc: 0.8678
Epoch 35/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3190 - acc: 0.8943 - val_loss: 0.4113 - val_acc: 0.8744
Epoch 36/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3208 - acc: 0.8938 - val_loss: 0.4033 - val_acc: 0.8711
Epoch 37/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3175 - acc: 0.8920 - val_loss: 0.4030 - val_acc: 0.8715
Epoch 38/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3209 - acc: 0.8929 - val_loss: 0.4078 - val_acc: 0.8680
Epoch 39/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3135 - acc: 0.8934 - val_loss: 0.4038 - val_acc: 0.8722
Epoch 40/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3048 - acc: 0.8955 - val_loss: 0.4199 - val_acc: 0.8683
Epoch 41/50
338/338 [==============================] - 9s 28ms/step - loss: 0.3028 - acc: 0.8978 - val_loss: 0.4141 - val_acc: 0.8715
Epoch 42/50
338/338 [==============================] - 10s 28ms/step - loss: 0.2975 - acc: 0.8979 - val_loss: 0.4145 - val_acc: 0.8696
Epoch 43/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3120 - acc: 0.8958 - val_loss: 0.4167 - val_acc: 0.8696
Epoch 44/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3053 - acc: 0.8978 - val_loss: 0.4070 - val_acc: 0.8728
Epoch 45/50
338/338 [==============================] - 10s 28ms/step - loss: 0.3021 - acc: 0.8994 - val_loss: 0.4150 - val_acc: 0.8741
Epoch 46/50
338/338 [==============================] - 9s 28ms/step - loss: 0.2948 - acc: 0.9010 - val_loss: 0.4124 - val_acc: 0.8741
Epoch 47/50
338/338 [==============================] - 10s 28ms/step - loss: 0.2925 - acc: 0.9006 - val_loss: 0.4100 - val_acc: 0.8781
Epoch 48/50
338/338 [==============================] - 9s 28ms/step - loss: 0.2920 - acc: 0.9009 - val_loss: 0.4149 - val_acc: 0.8722
Epoch 49/50
338/338 [==============================] - 9s 28ms/step - loss: 0.2912 - acc: 0.8988 - val_loss: 0.4252 - val_acc: 0.8754
Epoch 50/50
338/338 [==============================] - 9s 28ms/step - loss: 0.2772 - acc: 0.9039 - val_loss: 0.4173 - val_acc: 0.8720
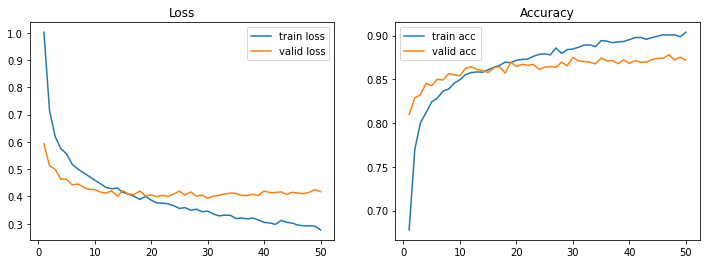
In [39]:
pred = t_model.predict(image.numpy().reshape(-1, 64, 64, 3))
np.argmax(pred)
Out [39]:
1/1 [==============================] - 1s 1s/step
7
In [40]:
plt.imshow(image)
plt.title(info.features['label'].int2str(np.argmax(pred)))
Out [40]:
Text(0.5, 1.0, 'Residential')

Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기