
Deep Learning (17) - CNN / 고양이와 개의 구별
고양이와 개의 구별
In [1]:
import tensorflow as tf
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import matplotlib.pyplot as plt
import zipfile
In [2]:
from google.colab import drive
drive.mount('/content/drive')
Out [2]:
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
데이터 불러오기
In [3]:
path = '/content/drive/MyDrive/Colab Notebooks/deep_learning/cats_and_dogs.zip'
zip_ref = zipfile.ZipFile(path, 'r')
zip_ref.extractall('dataset/')
zip_ref.close()
In [4]:
image_gen = ImageDataGenerator(rescale=1/255.)
train_dir = '/content/dataset/cats_and_dogs_filtered/train/'
valid_dir = '/content/dataset/cats_and_dogs_filtered/validation/'
train_gen = image_gen.flow_from_directory(train_dir, target_size=(224, 224),
batch_size=32, classes=['cats', 'dogs'],
class_mode='binary', seed=2020)
valid_gen = image_gen.flow_from_directory(valid_dir, target_size=(224, 224),
batch_size=32, classes=['cats', 'dogs'],
class_mode='binary', seed=2020)
Out [4]:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
데이터 확인하기
In [5]:
class_labels = ['cats', 'dogs']
batch = next(train_gen)
images, labels = batch[0], batch[1]
plt.figure(figsize=(16, 8))
for i in range(32):
ax = plt.subplot(4, 8, i+1)
plt.imshow(images[i])
plt.title(class_labels[labels[i].astype(int)]) # int(labels[i]) 또는 labels[i].astype(int)
plt.axis('off') # 눈금 안보이게 처리
plt.tight_layout()
plt.show()
Out [5]:

In [6]:
images.shape
Out [6]:
(32, 224, 224, 3)
모델 구성
In [7]:
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D, BatchNormalization
from keras.optimizers import Adam
from keras.losses import BinaryCrossentropy
In [8]:
def build_model():
model = Sequential([
BatchNormalization(),
Conv2D(32, (3, 3), padding='same', activation='relu'),
MaxPooling2D((2, 2)),
BatchNormalization(),
Conv2D(64, (3, 3), padding='same', activation='relu'),
MaxPooling2D((2, 2)),
BatchNormalization(),
Conv2D(128, (3, 3), padding='same', activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(256, activation='relu'),
Dropout(0.3),
Dense(1, activation='sigmoid') # 이진분류
])
return model
In [9]:
model = build_model()
In [10]:
model.compile(optimizer=Adam(0.001), loss=BinaryCrossentropy(), metrics=['accuracy'])
history = model.fit(train_gen, validation_data=valid_gen, epochs=20)
Out [10]:
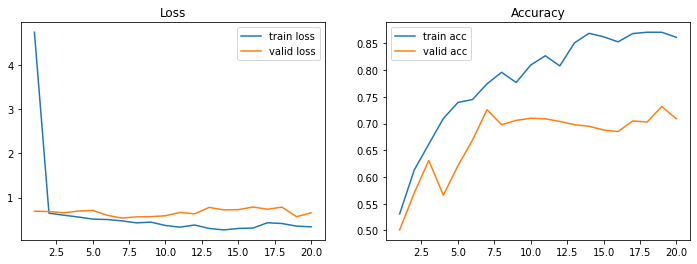
Epoch 1/20
63/63 [==============================] - 18s 247ms/step - loss: 4.7438 - accuracy: 0.5310 - val_loss: 0.6924 - val_accuracy: 0.5010
Epoch 2/20
63/63 [==============================] - 10s 163ms/step - loss: 0.6463 - accuracy: 0.6130 - val_loss: 0.6833 - val_accuracy: 0.5700
Epoch 3/20
63/63 [==============================] - 10s 161ms/step - loss: 0.6017 - accuracy: 0.6615 - val_loss: 0.6555 - val_accuracy: 0.6310
Epoch 4/20
63/63 [==============================] - 10s 161ms/step - loss: 0.5610 - accuracy: 0.7095 - val_loss: 0.6945 - val_accuracy: 0.5660
Epoch 5/20
63/63 [==============================] - 11s 182ms/step - loss: 0.5136 - accuracy: 0.7395 - val_loss: 0.7109 - val_accuracy: 0.6210
Epoch 6/20
63/63 [==============================] - 10s 160ms/step - loss: 0.5036 - accuracy: 0.7450 - val_loss: 0.5990 - val_accuracy: 0.6690
Epoch 7/20
63/63 [==============================] - 10s 159ms/step - loss: 0.4733 - accuracy: 0.7745 - val_loss: 0.5365 - val_accuracy: 0.7260
Epoch 8/20
63/63 [==============================] - 10s 160ms/step - loss: 0.4280 - accuracy: 0.7960 - val_loss: 0.5627 - val_accuracy: 0.6980
Epoch 9/20
63/63 [==============================] - 11s 176ms/step - loss: 0.4442 - accuracy: 0.7770 - val_loss: 0.5677 - val_accuracy: 0.7060
Epoch 10/20
63/63 [==============================] - 10s 161ms/step - loss: 0.3682 - accuracy: 0.8095 - val_loss: 0.5893 - val_accuracy: 0.7100
Epoch 11/20
63/63 [==============================] - 10s 159ms/step - loss: 0.3304 - accuracy: 0.8270 - val_loss: 0.6634 - val_accuracy: 0.7090
Epoch 12/20
63/63 [==============================] - 10s 159ms/step - loss: 0.3794 - accuracy: 0.8080 - val_loss: 0.6330 - val_accuracy: 0.7040
Epoch 13/20
63/63 [==============================] - 10s 163ms/step - loss: 0.3013 - accuracy: 0.8510 - val_loss: 0.7775 - val_accuracy: 0.6980
Epoch 14/20
63/63 [==============================] - 10s 161ms/step - loss: 0.2681 - accuracy: 0.8690 - val_loss: 0.7211 - val_accuracy: 0.6950
Epoch 15/20
63/63 [==============================] - 10s 160ms/step - loss: 0.3016 - accuracy: 0.8625 - val_loss: 0.7267 - val_accuracy: 0.6880
Epoch 16/20
63/63 [==============================] - 10s 164ms/step - loss: 0.3090 - accuracy: 0.8530 - val_loss: 0.7867 - val_accuracy: 0.6850
Epoch 17/20
63/63 [==============================] - 10s 158ms/step - loss: 0.4304 - accuracy: 0.8685 - val_loss: 0.7371 - val_accuracy: 0.7050
Epoch 18/20
63/63 [==============================] - 10s 161ms/step - loss: 0.4130 - accuracy: 0.8710 - val_loss: 0.7835 - val_accuracy: 0.7030
Epoch 19/20
63/63 [==============================] - 10s 164ms/step - loss: 0.3537 - accuracy: 0.8710 - val_loss: 0.5666 - val_accuracy: 0.7320
Epoch 20/20
63/63 [==============================] - 10s 159ms/step - loss: 0.3377 - accuracy: 0.8615 - val_loss: 0.6559 - val_accuracy: 0.7090
In [11]:
def plot_loss_acc(history, epoch):
loss, val_loss = history.history['loss'], history.history['val_loss']
acc, val_acc = history.history['accuracy'], history.history['val_accuracy']
fig, axes = plt.subplots(1, 2, figsize=(12, 4))
axes[0].plot(range(1, epoch+1), loss, label='train loss')
axes[0].plot(range(1, epoch+1), val_loss, label='valid loss')
axes[0].legend(loc='best')
axes[0].set_title('Loss')
axes[1].plot(range(1, epoch+1), acc, label='train acc')
axes[1].plot(range(1, epoch+1), val_acc, label='valid acc')
axes[1].legend(loc='best')
axes[1].set_title('Accuracy')
plt.show()
In [12]:
plot_loss_acc(history, 20)
Out [12]:
이미지 데이터 증가
In [13]:
image_gen = ImageDataGenerator(rescale=(1/255.), horizontal_flip=True,
zoom_range=0.2, rotation_range=30)
train_gen_aug = image_gen.flow_from_directory(train_dir, target_size=(224, 224),
batch_size=32, classes=['cats', 'dogs'],
class_mode='binary', seed=2020)
valid_gen_aug = image_gen.flow_from_directory(valid_dir, target_size=(224, 224),
batch_size=32, classes=['cats', 'dogs'],
class_mode='binary', seed=2020)
Out [13]:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
In [14]:
aug_model = build_model()
aug_model.compile(optimizer=Adam(0.001), loss=BinaryCrossentropy(), metrics=['accuracy'])
aug_history = aug_model.fit(train_gen_aug, validation_data=valid_gen_aug, epochs=20)
Out [14]:
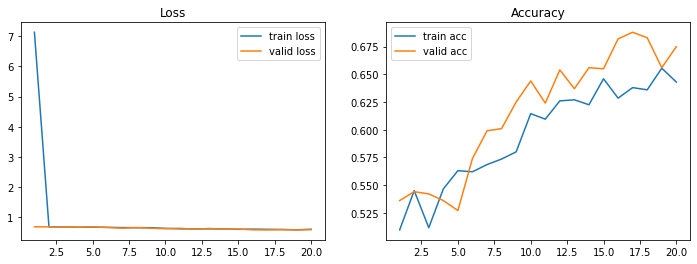
Epoch 1/20
63/63 [==============================] - 38s 602ms/step - loss: 7.1295 - accuracy: 0.5095 - val_loss: 0.6919 - val_accuracy: 0.5360
Epoch 2/20
63/63 [==============================] - 37s 584ms/step - loss: 0.6870 - accuracy: 0.5450 - val_loss: 0.6901 - val_accuracy: 0.5440
Epoch 3/20
63/63 [==============================] - 36s 565ms/step - loss: 0.6857 - accuracy: 0.5115 - val_loss: 0.6838 - val_accuracy: 0.5420
Epoch 4/20
63/63 [==============================] - 35s 565ms/step - loss: 0.6763 - accuracy: 0.5465 - val_loss: 0.6793 - val_accuracy: 0.5360
Epoch 5/20
63/63 [==============================] - 36s 565ms/step - loss: 0.6785 - accuracy: 0.5630 - val_loss: 0.6877 - val_accuracy: 0.5270
Epoch 6/20
63/63 [==============================] - 36s 566ms/step - loss: 0.6729 - accuracy: 0.5620 - val_loss: 0.6701 - val_accuracy: 0.5740
Epoch 7/20
63/63 [==============================] - 36s 568ms/step - loss: 0.6651 - accuracy: 0.5685 - val_loss: 0.6448 - val_accuracy: 0.5990
Epoch 8/20
63/63 [==============================] - 37s 593ms/step - loss: 0.6617 - accuracy: 0.5735 - val_loss: 0.6644 - val_accuracy: 0.6010
Epoch 9/20
63/63 [==============================] - 36s 569ms/step - loss: 0.6626 - accuracy: 0.5800 - val_loss: 0.6445 - val_accuracy: 0.6250
Epoch 10/20
63/63 [==============================] - 36s 566ms/step - loss: 0.6391 - accuracy: 0.6145 - val_loss: 0.6290 - val_accuracy: 0.6440
Epoch 11/20
63/63 [==============================] - 35s 565ms/step - loss: 0.6235 - accuracy: 0.6095 - val_loss: 0.6425 - val_accuracy: 0.6240
Epoch 12/20
63/63 [==============================] - 36s 569ms/step - loss: 0.6195 - accuracy: 0.6260 - val_loss: 0.6100 - val_accuracy: 0.6540
Epoch 13/20
63/63 [==============================] - 37s 586ms/step - loss: 0.6219 - accuracy: 0.6270 - val_loss: 0.6363 - val_accuracy: 0.6370
Epoch 14/20
63/63 [==============================] - 36s 568ms/step - loss: 0.6193 - accuracy: 0.6225 - val_loss: 0.6119 - val_accuracy: 0.6560
Epoch 15/20
63/63 [==============================] - 36s 568ms/step - loss: 0.6070 - accuracy: 0.6460 - val_loss: 0.6192 - val_accuracy: 0.6550
Epoch 16/20
63/63 [==============================] - 35s 565ms/step - loss: 0.6142 - accuracy: 0.6285 - val_loss: 0.5901 - val_accuracy: 0.6820
Epoch 17/20
63/63 [==============================] - 36s 568ms/step - loss: 0.6075 - accuracy: 0.6380 - val_loss: 0.5881 - val_accuracy: 0.6880
Epoch 18/20
63/63 [==============================] - 35s 564ms/step - loss: 0.6034 - accuracy: 0.6360 - val_loss: 0.5962 - val_accuracy: 0.6830
Epoch 19/20
63/63 [==============================] - 37s 589ms/step - loss: 0.5910 - accuracy: 0.6555 - val_loss: 0.5882 - val_accuracy: 0.6560
Epoch 20/20
63/63 [==============================] - 35s 562ms/step - loss: 0.6106 - accuracy: 0.6430 - val_loss: 0.5946 - val_accuracy: 0.6750
In [15]:
plot_loss_acc(aug_history, 20)
Out [15]:
전이 학습
In [16]:
from keras.applications import ResNet50V2
In [17]:
pre_trained_base = ResNet50V2(include_top=False, input_shape=[224, 224, 3])
pre_trained_base.trainable = False
In [18]:
def build_transter_model():
model = Sequential([
pre_trained_base,
Flatten(),
Dense(256, activation='relu'),
Dropout(0.3),
Dense(1, activation='sigmoid')
])
return model
In [19]:
t_model = build_transter_model()
t_model.compile(optimizer=Adam(0.001), loss=BinaryCrossentropy(), metrics=['accuracy'])
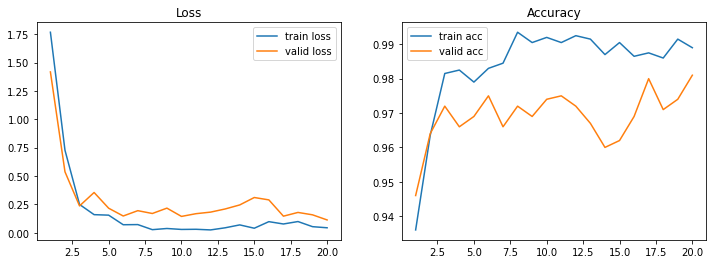
t_history = t_model.fit(train_gen_aug, validation_data=valid_gen_aug, epochs=20)
plot_loss_acc(t_history, 20)
Out [19]:
Epoch 1/20
63/63 [==============================] - 42s 610ms/step - loss: 1.7668 - accuracy: 0.9360 - val_loss: 1.4171 - val_accuracy: 0.9460
Epoch 2/20
63/63 [==============================] - 36s 581ms/step - loss: 0.7271 - accuracy: 0.9635 - val_loss: 0.5371 - val_accuracy: 0.9640
Epoch 3/20
63/63 [==============================] - 37s 583ms/step - loss: 0.2494 - accuracy: 0.9815 - val_loss: 0.2364 - val_accuracy: 0.9720
Epoch 4/20
63/63 [==============================] - 38s 605ms/step - loss: 0.1594 - accuracy: 0.9825 - val_loss: 0.3547 - val_accuracy: 0.9660
Epoch 5/20
63/63 [==============================] - 37s 586ms/step - loss: 0.1550 - accuracy: 0.9790 - val_loss: 0.2161 - val_accuracy: 0.9690
Epoch 6/20
63/63 [==============================] - 36s 579ms/step - loss: 0.0706 - accuracy: 0.9830 - val_loss: 0.1475 - val_accuracy: 0.9750
Epoch 7/20
63/63 [==============================] - 36s 579ms/step - loss: 0.0719 - accuracy: 0.9845 - val_loss: 0.1945 - val_accuracy: 0.9660
Epoch 8/20
63/63 [==============================] - 36s 578ms/step - loss: 0.0272 - accuracy: 0.9935 - val_loss: 0.1696 - val_accuracy: 0.9720
Epoch 9/20
63/63 [==============================] - 38s 604ms/step - loss: 0.0375 - accuracy: 0.9905 - val_loss: 0.2169 - val_accuracy: 0.9690
Epoch 10/20
63/63 [==============================] - 38s 611ms/step - loss: 0.0291 - accuracy: 0.9920 - val_loss: 0.1439 - val_accuracy: 0.9740
Epoch 11/20
63/63 [==============================] - 37s 588ms/step - loss: 0.0304 - accuracy: 0.9905 - val_loss: 0.1680 - val_accuracy: 0.9750
Epoch 12/20
63/63 [==============================] - 37s 590ms/step - loss: 0.0249 - accuracy: 0.9925 - val_loss: 0.1817 - val_accuracy: 0.9720
Epoch 13/20
63/63 [==============================] - 37s 591ms/step - loss: 0.0436 - accuracy: 0.9915 - val_loss: 0.2095 - val_accuracy: 0.9670
Epoch 14/20
63/63 [==============================] - 37s 584ms/step - loss: 0.0691 - accuracy: 0.9870 - val_loss: 0.2451 - val_accuracy: 0.9600
Epoch 15/20
63/63 [==============================] - 38s 604ms/step - loss: 0.0398 - accuracy: 0.9905 - val_loss: 0.3105 - val_accuracy: 0.9620
Epoch 16/20
63/63 [==============================] - 37s 588ms/step - loss: 0.0977 - accuracy: 0.9865 - val_loss: 0.2896 - val_accuracy: 0.9690
Epoch 17/20
63/63 [==============================] - 37s 588ms/step - loss: 0.0771 - accuracy: 0.9875 - val_loss: 0.1460 - val_accuracy: 0.9800
Epoch 18/20
63/63 [==============================] - 41s 656ms/step - loss: 0.0987 - accuracy: 0.9860 - val_loss: 0.1790 - val_accuracy: 0.9710
Epoch 19/20
63/63 [==============================] - 37s 591ms/step - loss: 0.0535 - accuracy: 0.9915 - val_loss: 0.1578 - val_accuracy: 0.9740
Epoch 20/20
63/63 [==============================] - 38s 613ms/step - loss: 0.0438 - accuracy: 0.9890 - val_loss: 0.1128 - val_accuracy: 0.9810
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기