
Machine Learning (1) - 기본사용
머신러닝(Machine Learning)
!python -V
# !python --version
Python 3.9.13
인공지능, 머신러닝, 딥러닝
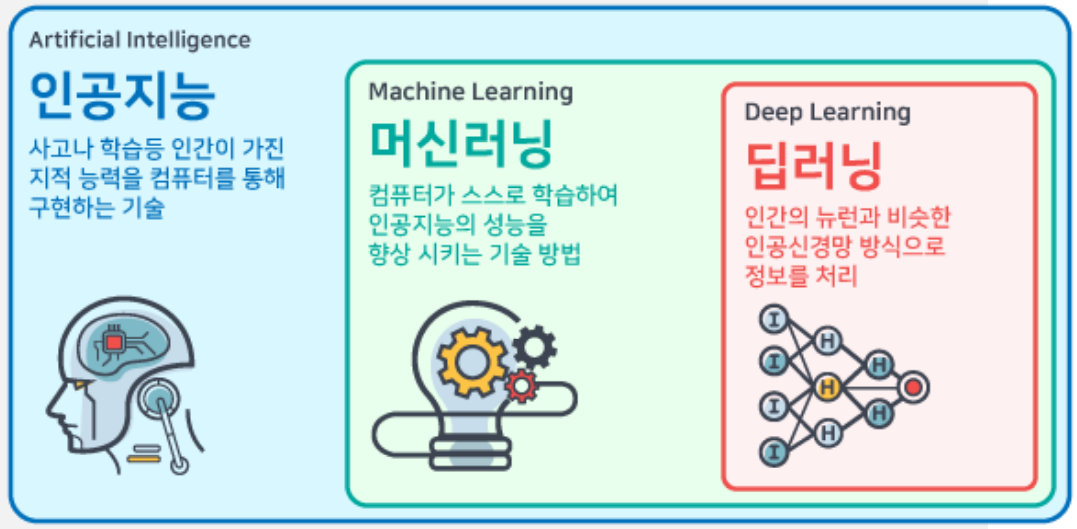
인공지능(Artificial Intelligence): 사고나 학습등 인간이 가진 지적능력을 컴퓨터를 통해 구현하는 기술이다.
머신러닝(Machine Learning): 컴퓨터가 스스로 학습하여 인공지능의 성능을 향상시키는 기술 방법이다.
딥러닝(Deep Learning): 인간이 뉴련과 비슷한 인공신경망 방식으로 정보를 처리한다.
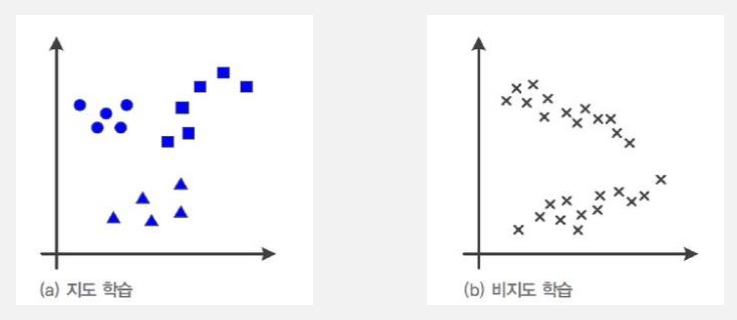
지도학습, 비지도학습, 강화학습
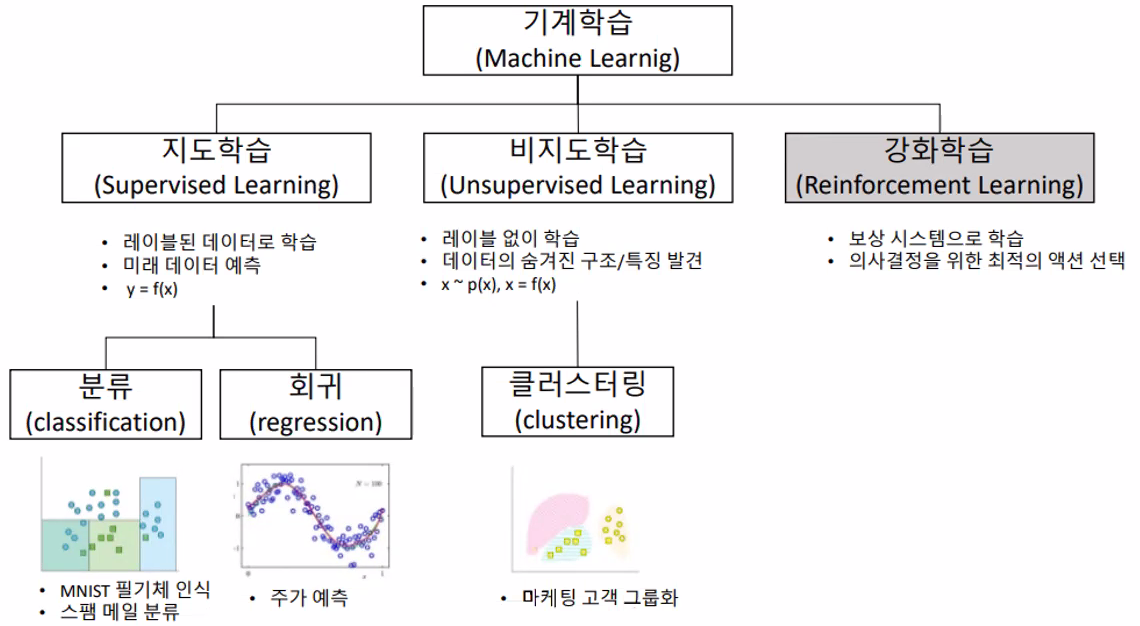
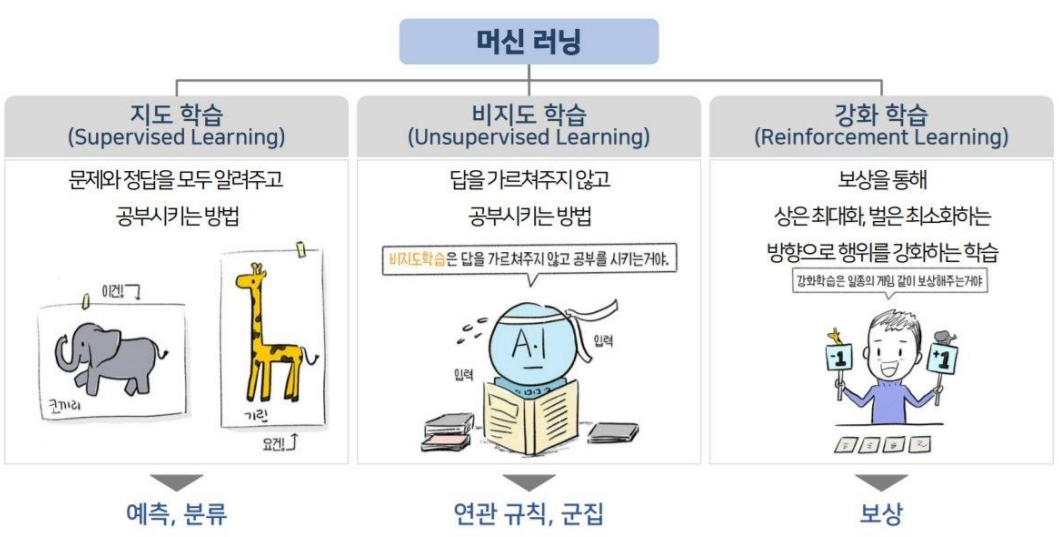
지도학습(답O), 비지도학습(답X), 강화학습(경쟁)
지도학습(Supervised Learning)
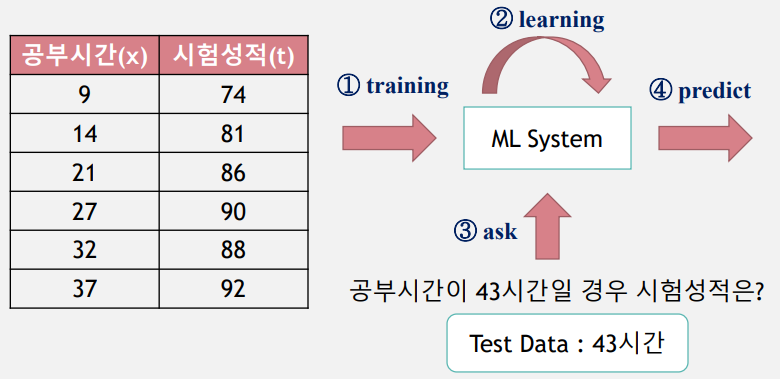
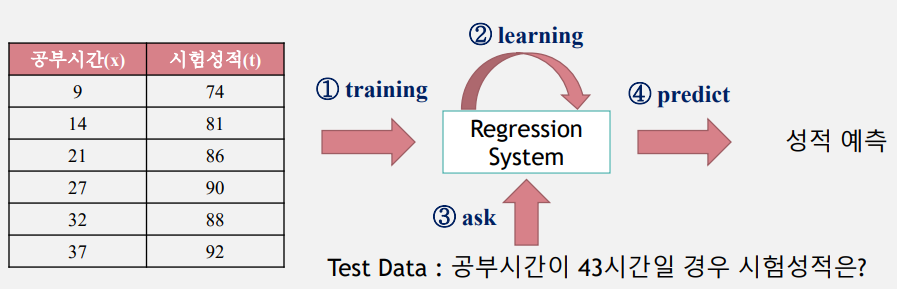
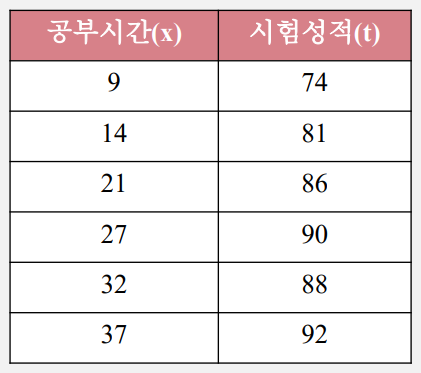
공부시간-시험성적 학습결과를 바탕으로 입력 데이터에 없는 공부시간에 대한 성적 예측한다.
지도학습은 입력 값(x)과 정답(t, label)을 포함하는 Training Data를 이용하여 학습하고, 그 학습된 결과를 바탕으로 미지의 데이터(Test Data)에 대해 미래 값을 예측(Predict)하는 방법이다.
대부분의 머신러닝 문제는 지도학습에 해당한다.
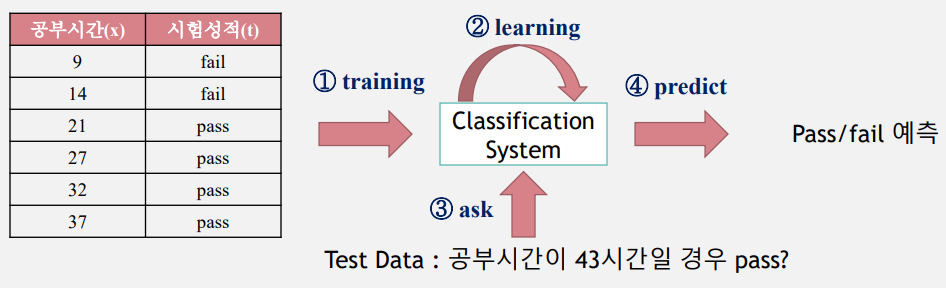
예1) 시험 공부 시간(입력)과 Pass/Fail(정답)을 이용하여 당락 여부 예측 이산값(분류)
예2) 집 평수(입력)와 가격 데이터(정답)을 이용하여 임의의 평수 가격 예측 연속값(회귀)
지도학습은 학습결과를 바탕으로 미래의 무엇을 예측하느냐에 따라 회귀(Regression), 분류(Classification) 등으로 구분할 수 있다.
회귀(Regression)는 Training Data를 이용하여 연속적인(숫자)값을 예측하는 것이다.
예) 집 평수와 가격관계, 공부시간과 시험성적 등의 관계
분류(Classification)는 Training Data를 이용하여 주어진 입력 값이 어떤 종류인지 구별하는 것이다.
예) 공부시간과 합격여부
비지도학습(Unsupervised Learning)
비지도학습은 Training Data에 정답은 없고 입력 데이터만 있기 때문에 입력에 대한 정답을 찾는 것이 아닌 패턴, 특성 등을 학습을 통해 발견하는 방법을 말한다.
예) 군집화 알고리즘을 이용한 뉴스 그룹핑, 백화점 상품 추천 시스템 등
지도학습(Supervised Learning) - 회귀(Regression)
선형회귀(Linear Regression)
Training Data를 이용하여 데이터의 특성과 상관관계 등을 파악하고, 그 결과를 바탕으로 Training Data에 없는 미지의 데이터가 주어졌을 경우에 그 결과를 연속적인(숫자)값으로 예측하는 것이다.
주어진 데이터를 이용해 일차방정식을 수정해 나가는 것이다.
학습을 거쳐서 가장 합리적인 선을 찾아내는 것이다.
학습을 많이 해도 완벽한 식을 찾아 내지 못할 수 있다.
가장 근사치의 값을 찾는 것이다.
- x(독립변수)
- y(종속변수): x에 영향을 받음
[step1] analyze training data
학습데이터(training data)는 입력 (x)인 공부시간에 비례해서 출력(y)인 시험성적도 증가하는 경향이 있다.
즉, 입력(x)과 출력(y) 은 \(y = Wx + b\) 형태로 나타낼 수 있다.
- W: 가중치
- b: 절편, 보통 0으로 주고 계산
[step2] find W and b
①, ②, ③, … 등의 다향한 \(y = Wx + b\) 직선 가운데 training data의 특성을 가장 잘 표현할 수 있는 가중치 W(기울기), 바이어스 b(y절편)를 찾는 것이 학습(Learning) 개념이다.
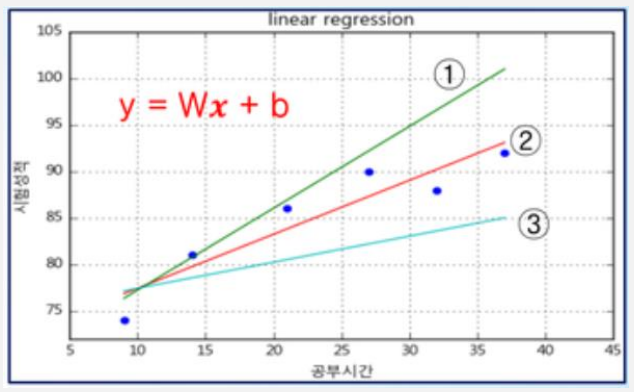
Training data의 정답(t)과 직선 \(y = Wx + b\) 값의 차이인 오차(error)는
\(오차(error) = t - y = t - (Wx + b)\) 으로 계산되며
오차가 크다면 우리가 임의로 설정한 직선의 가중치와 바이어스 값이 잘못된 것이고 오차가 작다면 직선의 가중치와 바이어스 값이 잘 된 것이기 때문에 미래 값 예측도 정확할 수 있다고 예상할 수 있다.
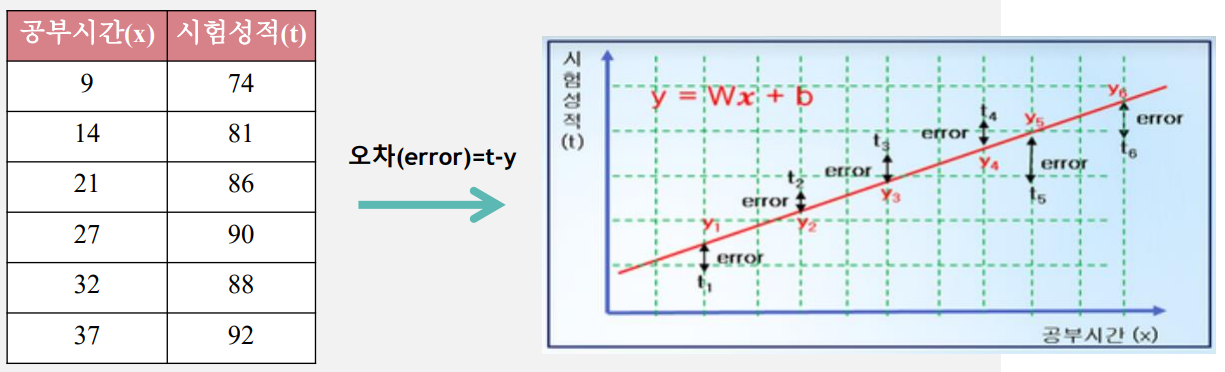
머신러닝 regression 시스템은 모든 데이터의 \(오차(error) = t - y = t - (Wx + b)\)의 합이 최소가 되어서 미래 값을 잘 예측할 수 있는 가중치 W와 바이어스 b값을 찾아야 한다.
손실함수(loss function)
손실함수에서 오차(error)를 계산할 때는 \((t - y)^2 = [t - (Wx + b)]^2\) 을 사용한다.
즉 오차는 언제나 양수이며, 제곱을 하기 때문에 정답과 계산 값 차이가 크다면 제곱에 의해 오차는 더 큰 값을 가지게 되어 머신 러닝 학습에 있어 장점을 가진다.
X와 t는 training data에서 주어지는 값이므로 손실함수(loss function)인 E(W,b)는 결국 W와 b에 영향을 받는 함수이다.
- E(W,b)값이 작다는 것은 정답(t , target)과 \(y = Wx+b\) 에 의해 계산된 값의 평균 오차가 작다는 의미이다.
- 평균 오차가 작다는 것은 미지의 데이터 x가 주어질 경우, 확률적으로 미래의 결과값도 오차가 작을 것이라고 추측할 수 있다.
- 이처럼 training data를 바탕으로 손실함수 E(W, b)가 최소값을 갖도록(W , b)를 구하는 것이 (linear) regression model의 최종 목적이다.
경사하강법(gradient decent algorithm)
계산을 쉽게 하고 손실함수의 모양을 파악하기 위해 E(W, b)에서 바이어스 b=0을 가정했다.
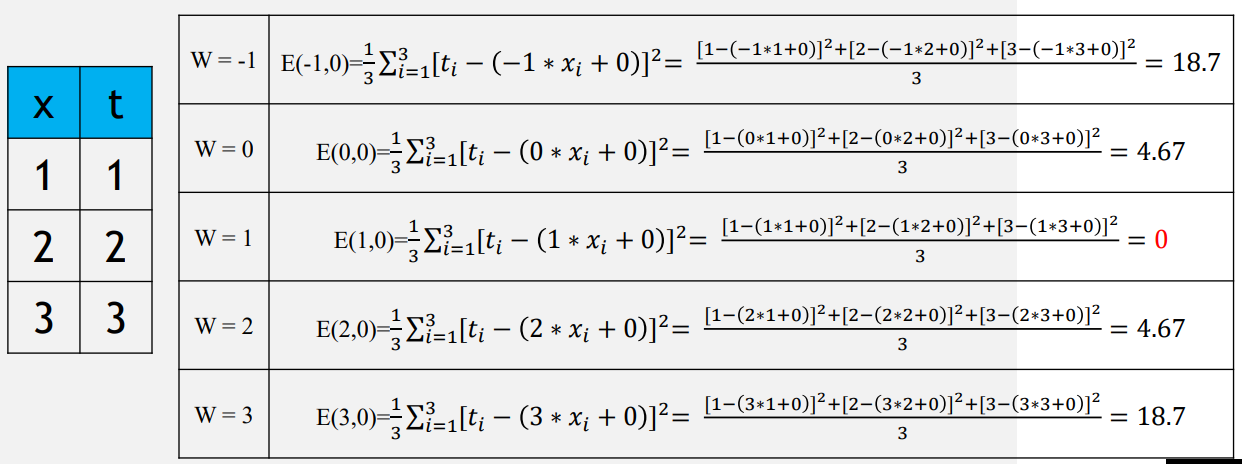
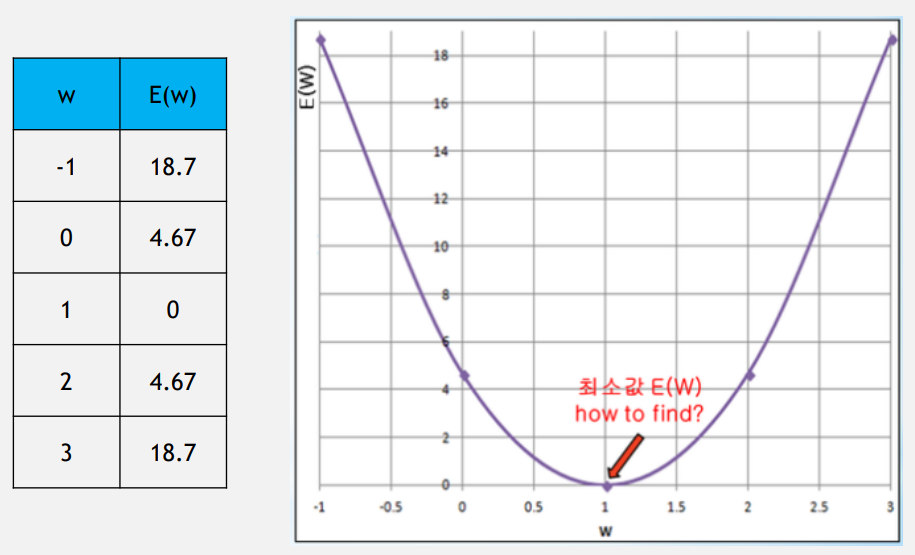
- 손실함수의 그래프
제곱을 쓰면 2차함수
절대값을 쓰면 비례(직선)
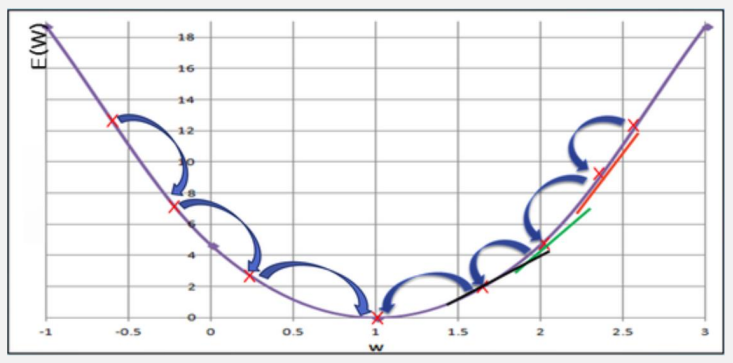
- 임의의 가중치 W 선택한다.
- 그 W에서의 직선의 기울기를 나타내는 미분 값(해당 W에서의 미분) \(\frac{𝜕E(W)}{𝜕W}\)을 구한다.
- 그 미분 값이 작아지는 방향으로 W감소(또는 증가)시켜 나간다.
- 최종적으로 기울기가 더 이상 작아지지 않는 곳을 찾을 수 있는데, 그 곳이 손실함수 E(W) 최소값임을 알 수 있다.
이처럼 W에서의 직선의 기울기인 미분 값을 이용하여 그 값이 작아지는 방향으로 진행하여 손실함수 최소값을 찾는 방법을 경사하강법(gradient decent algorithm)이라고 한다.
- W에서의 편미분 \(\frac{𝜕E(W)}{𝜕W}\) 는 해당 W에서 기울기(slope)를 나타낸다.
->\(\frac{𝜕E(W)}{𝜕W}\) 이 양수(+) 값을 갖는다면 W는 왼쪽으로 이동시켜야만(감소) 손실함수 E(W) 최소값을 찾을 수 있다.
->\(\frac{𝜕E(W)}{𝜕W}\) 이 양수(-) 값을 갖는다면 W는 오른쪽으로 이동시켜야만(증가) 손실함수 E(W) 최소값을 찾을 수 있다.
- 𝑎는 학습률(learning rate)이라고 부르며, W 값의 감소 또는 증가 되는 비율을 나타낸다.(W를 얼마나 이동시킬지)
지도학습 - 분류(Classification)
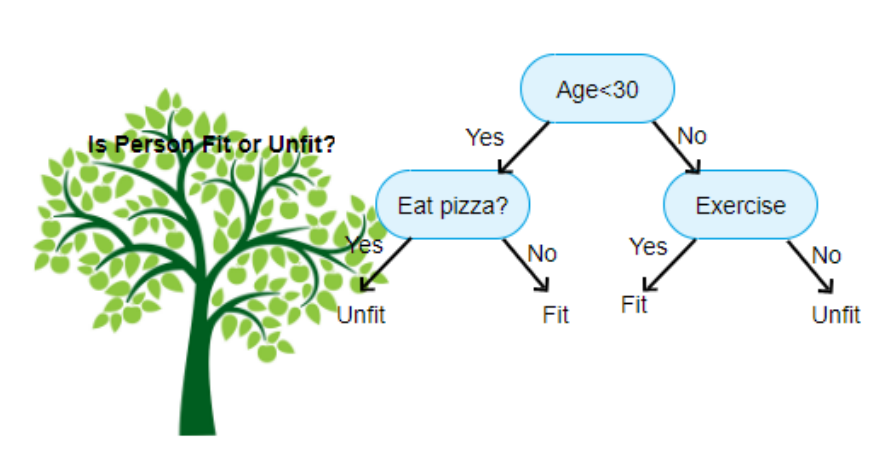
의사결정 트리(Decision Tree)
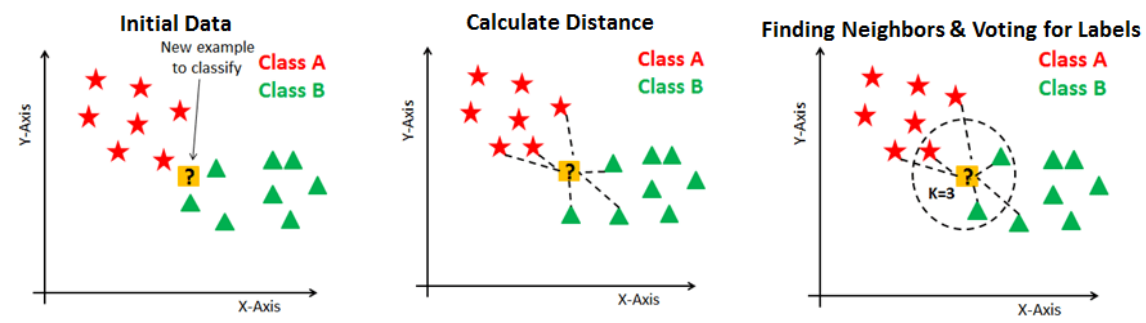
K-nearest neighbor classifier(K-최근접 이웃 분류기)
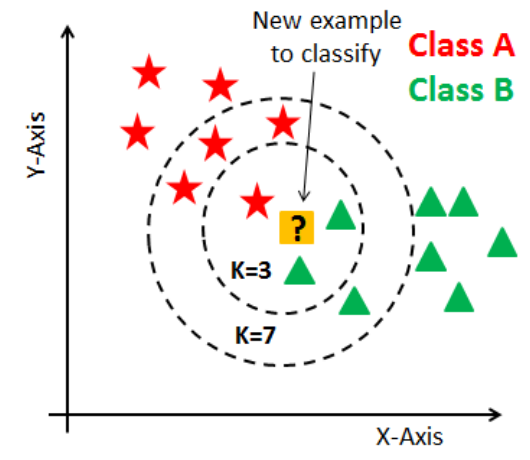
K를 홀수로 하여 어느쪽에든 소속되게 한다
비지도학습 - 군집
K-means Clustering(평균 군집)
KMeans 클러스터링 알고리즘은 n개의 중심점을 찍은 후에, 이 중심점에서 각 점간의 거리의 합이 가장 최소화가 되는 중심점 n의 위치를 찾고, 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 클러스터링 알고리즘이다.
사이킷런으로 시작하는 머신러닝
사이킷런(sciket-learn)은 파이썬 머신러닝 라이브러리 중 가장 많이 사용되는 라이브러리이다.
OOP의 특징을 사용(상속의 개념)한다.
import sklearn
sklearn.__version__ # 클래스의 속성값을 보통 __값__으로 저장해 놓는다
'1.0.2'
붓꽃(Iris) 품종 예측
from sklearn.datasets import load_iris
# load가 아닌 fetch로 된것은 인터넷으로 받는 데이터 세트
from sklearn.tree import DecisionTreeClassifier
# 의사 결정 트리
from sklearn.model_selection import train_test_split
# 데이터 분리(학습/검증) - 데이터 100% 중 학습용과 검증용 데이터를 분리하여 머신러닝 후 학습 이외의 데이터로 테스트하기 위해
import pandas as pd
# 데이터 전처리
- iris data feature(X)
- sepal length(꽃받침 길이)
- sepal width(꽃받침 너비)
- petal length(꽃잎 길이)
- petal width(꽃잎 너비)
- iris data label(y)
- Setosa
- Vesicolor
- Virginica
iris = load_iris(as_frame=True) # as_frame: dictionary_like 형태의 데이터를 dataframe형태로
type(iris)
sklearn.utils.Bunch
iris.data.head(3)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
iris_df = iris.data.copy()
iris_df['label'] = iris.target # target명을 하나의 column으로 추가
iris_df.head(3)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | label | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
iris.data.head(3)
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
iris.target_names
array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=11)
# test_size와 train_size 합쳐서 1이 되게 설정, random_state: random의 seed와 같은 개념
# iris.data와 iris.target가 같은 위치의 데이터를 가져오도록 둘다 파라미터로 넣어준다
# iris.data 가 X-train(8):X_test(2)로, iris.target이 y_train(8):y_test(2)로 나뉘어져 들어간다
# 보통 X(대문자)-문제(input) y(소문자)-답(target)
# 의사결정트리 객체 생성
dt_clf = DecisionTreeClassifier(random_state=11)
# 모델 학습 수행
dt_clf.fit(X_train, y_train)
DecisionTreeClassifier(random_state=11)
# 예측 수행
pred = dt_clf.predict(X_test)
from sklearn.metrics import accuracy_score
# metrics평가와 관련된 것을 모아둔
# 예측 정확도 측정
accuracy_score(y_test, pred)
0.9333333333333333
머신러닝의 흐름
- 데이터 크롤링«이미 완료된 데이터
- 데이터 전처리(모델링)«이미 완료된 데이터
- 데이터 세트 분리
- 학습
- 예측
- 평가
자연어 처리시 무조건 숫자로 바꿔야 함 (글자는 안된다)
dt_clf.predict([[4.67, 3.9, 2, 0.4]]) # 학습에 넣은 데이터 모양대로 넣어야 한다 # setosa라 예측
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but DecisionTreeClassifier was fitted with feature names
warnings.warn(
array([0])
# 예측모델 저장
import pickle
f = open('model', 'wb')
pickle.dump(dt_clf, f)
f.close()
# 예측모델 불러오기
f = open('model', 'rb')
model = pickle.load(f)
f.close()
model.predict([[4.67, 3.9, 2, 0.4]])
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but DecisionTreeClassifier was fitted with feature names
warnings.warn(
array([0])
기본으로 불러오기
iris = load_iris()
type(iris) # dictionary_like
sklearn.utils.Bunch
iris.keys()
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])
# iris.items()
# iris.values()
Model Selection 모듈 소개
- train_test_split() : 학습/테스트 데이터 세트 분리
iris = load_iris()
dt_clf = DecisionTreeClassifier()
# 학습
dt_clf.fit(iris.data, iris.target)
#예측
pred = dt_clf.predict(iris.data)
#평가
accuracy_score(iris.target, pred)
1.0
분리하지 않으면 평가를 해도 100%가 되어버림
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기