
Machine Learning (4) - 타이타닉 생존자 예측
사이킷런으로 시작하는 머신러닝
사이킷런으로 수행하는 타이타닉 생존자 예측
데이터 처리
In [1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
In [2]:
df = pd.read_csv('titanic.csv')
In [3]:
df.head(2)
Out [3]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
In [4]:
df.info()
Out [4]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
In [5]:
df.isnull().sum()
Out [5]:
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
Null값 수정
- Age: nan값 평균값으로
- Cabin: nan값 ‘N’으로 변경
- Embarked: nan값 ‘N’으로 변경
In [6]:
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Cabin'].fillna('N', inplace=True)
df['Embarked'].fillna('N', inplace=True)
In [7]:
print("null값 :", df.isnull().sum().sum())
Out [7]:
null값 : 0
In [8]:
df.info()
Out [8]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 891 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 891 non-null object
11 Embarked 891 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
문자열 컬럼 수정
- Name, Ticket: 안씀
- Sex, Cabin, Embarked: 수정
In [9]:
df['Sex'].value_counts() # Nan은 체크하지 않으므로 미리 처리해야함
# 바로 숫자로 변경가능
Out [9]:
male 577
female 314
Name: Sex, dtype: int64
In [10]:
df['Cabin'].value_counts()
# 첫문자만 남기고 제거해야함
Out [10]:
N 687
C23 C25 C27 4
G6 4
B96 B98 4
C22 C26 3
...
E34 1
C7 1
C54 1
E36 1
C148 1
Name: Cabin, Length: 148, dtype: int64
In [11]:
df['Embarked'].value_counts()
# 바로 숫자로 변경가능
Out [11]:
S 644
C 168
Q 77
N 2
Name: Embarked, dtype: int64
In [12]:
# cabin의 첫글자만 남기기
df['Cabin'] = df['Cabin'].str[:1]
데이터 탐색
In [13]:
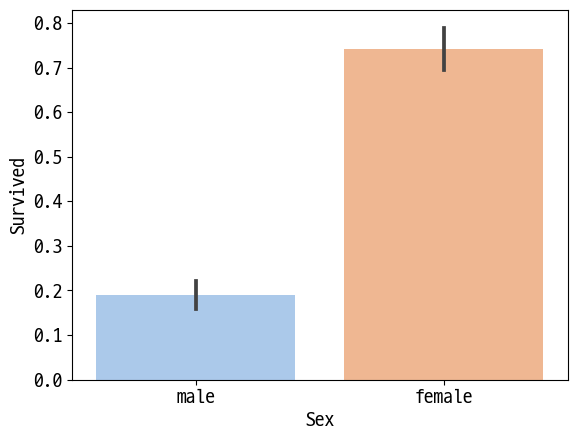
df.groupby(['Sex', 'Survived'])['Survived'].count()
Out [13]:
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
In [14]:
sns.barplot(data=df, x='Sex', y='Survived', palette='pastel')
Out [14]:
<AxesSubplot:xlabel='Sex', ylabel='Survived'>
In [15]:
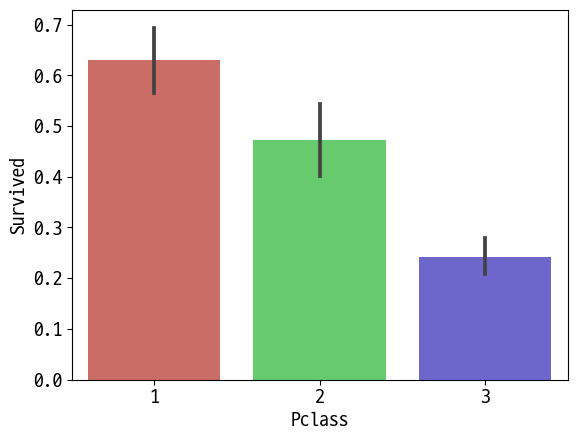
sns.barplot(data=df, x='Pclass', y='Survived', palette='hls')
Out [15]:
<AxesSubplot:xlabel='Pclass', ylabel='Survived'>
In [16]:
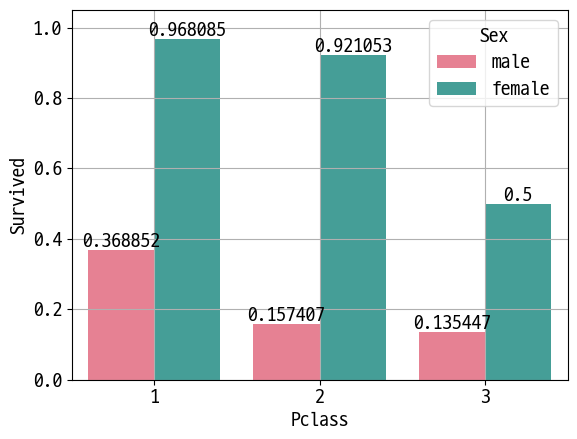
ax = sns.barplot(data=df, x='Pclass', y='Survived', hue='Sex', palette='husl', errwidth=0)
plt.grid()
for p in ax.containers:
ax.bar_label(p,)
Out [16]:
In [17]:
df['Age'].value_counts()
# 나잇대 그룹으로 묶기
Out [17]:
29.699118 177
24.000000 30
22.000000 27
18.000000 26
28.000000 25
...
36.500000 1
55.500000 1
0.920000 1
23.500000 1
74.000000 1
Name: Age, Length: 89, dtype: int64
In [18]:
def get_category(age):
cat = ''
if age <= -1: cat = 'Unknown'
elif age <= 5: cat = 'Baby'
elif age <= 12: cat = 'Child'
elif age <= 18: cat = 'Teenager'
elif age <= 25: cat = 'Student'
elif age <= 35: cat = 'Young Adult'
elif age <= 60: cat = 'Adult'
else: cat = 'Elderly'
return cat
In [19]:
df['Age_cat'] = df['Age'].apply(lambda x : get_category(x))
In [20]:
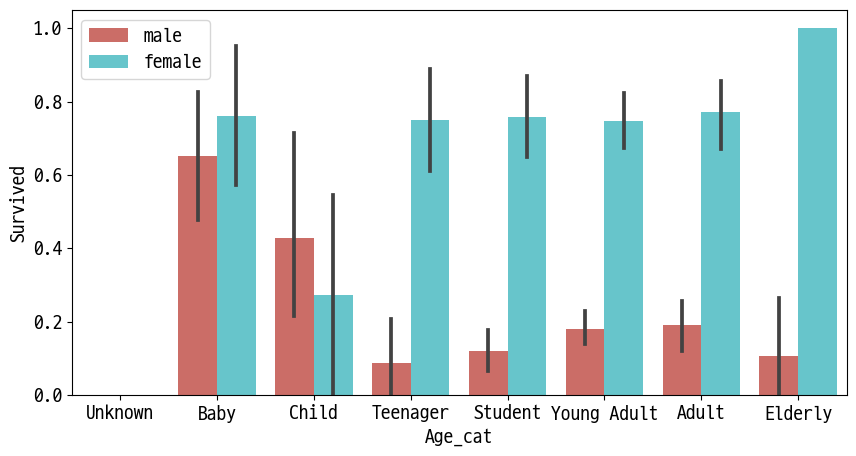
plt.figure(figsize=(10, 5))
group_name = ['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Elderly']
sns.barplot(data=df, x='Age_cat', y='Survived', hue='Sex', order=group_name, palette='hls')
plt.legend(loc='upper left')
Out [20]:
<matplotlib.legend.Legend at 0x1a6bf7b7910>
In [21]:
df.drop('Age_cat', axis=1, inplace=True)
머신러닝
LabelEncoder 적용
In [22]:
from sklearn.preprocessing import LabelEncoder
In [23]:
def encode_features(dataDF):
features = ['Sex', 'Cabin', 'Embarked']
for feature in features:
le = LabelEncoder()
dataDF[feature] = le.fit_transform(dataDF[feature])
print(le.classes_) # label 정보 저장
return dataDF
In [24]:
df = encode_features(df)
Out [24]:
['female' 'male']
['A' 'B' 'C' 'D' 'E' 'F' 'G' 'N' 'T']
['C' 'N' 'Q' 'S']
In [25]:
df.head(2)
Out [25]:
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | 1 | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | 7 | 3 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | 0 | 38.0 | 1 | 0 | PC 17599 | 71.2833 | 2 | 0 |
재사용 가능한 함수 작성
In [26]:
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(), inplace=True)
df['Cabin'].fillna('N', inplace=True)
df['Embarked'].fillna('N', inplace=True)
df['Fare'].fillna('0', inplace=True)
return df
# 불필요한 feature 제거
def drop_features(df):
df.drop(['PassengerId', 'Name', 'Ticket'], axis=1, inplace=True)
return df
# 레이블 인코딩
def format_features(df):
from sklearn.preprocessing import LabelEncoder
df['Cabin'] = df['Cabin'].str[:1]
features = ['Sex', 'Cabin', 'Embarked']
for feature in features:
le = LabelEncoder()
df[feature] = le.fit_transform(df[feature])
print(le.classes_)
return df
# 데이터 전처리 함수 전체 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
원본 재로딩, 함수 작동 확인
In [27]:
df = pd.read_csv('titanic.csv')
y = df['Survived']
X = df.drop(columns=['Survived'])
X = transform_features(X)
Out [27]:
['female' 'male']
['A' 'B' 'C' 'D' 'E' 'F' 'G' 'N' 'T']
['C' 'N' 'Q' 'S']
In [28]:
X.head(2)
Out [28]:
| Pclass | Sex | Age | SibSp | Parch | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 1 | 22.0 | 1 | 0 | 7.2500 | 7 | 3 |
| 1 | 1 | 0 | 38.0 | 1 | 0 | 71.2833 | 2 | 0 |
머신러닝
In [29]:
from sklearn.model_selection import train_test_split
In [30]:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=11)
In [31]:
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier # tree가 여러개
from sklearn.linear_model import LogisticRegression # 이진분류에 사용(이름은 회귀지만 분류 알고리즘)
from sklearn.metrics import accuracy_score
In [32]:
# 의사결정트리, 랜덤포레스트, 로지스틱회귀를 위한 사이킷런 Classifier 클래스 생성
dt_clf = DecisionTreeClassifier(random_state=11)
rf_clf = RandomForestClassifier(random_state=11)
lr_clf = LogisticRegression(solver='liblinear') # fit_intercept=True: y절편을 고정하지 않고 찾음
In [33]:
# DesisionTreeClassifier 학습/예측/평가
dt_clf.fit(X_train, y_train)
dt_pred = dt_clf.predict(X_test)
print("의사결정트리 정확도 :", accuracy_score(y_test, dt_pred))
Out [33]:
의사결정트리 정확도 : 0.7877094972067039
In [34]:
# RandomForestClassifier 학습/예측/평가
rf_clf.fit(X_train, y_train)
rf_pred = rf_clf.predict(X_test)
print("랜덤포레스트 정확도 :", accuracy_score(y_test, rf_pred))
Out [34]:
랜덤포레스트 정확도 : 0.8547486033519553
In [35]:
# LogisticRegression 학습/예측/평가
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
print("로지스틱회귀 정확도 :", accuracy_score(y_test, lr_pred))
Out [35]:
로지스틱회귀 정확도 : 0.8659217877094972
교차검증
KFold
In [36]:
from sklearn.model_selection import KFold
In [37]:
def exec_kfold(clf, folds=5):
kfold = KFold(n_splits=folds, shuffle=False)
scores = []
for iter_count, (train_index, test_index) in enumerate(kfold.split(X)):
# X_train, X_test = X.values[train_index], X.values[test_index]
# y_train, y_test = y.values[train_index], y.values[test_index]
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
# Classifier 학습, 예측, 정확도 계산
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
scores.append(accuracy)
print(f"{iter_count+1}차 교차 검증 정확도 : {accuracy:.4f}")
mean_score = np.mean(scores)
print(f"평균 정확도 : {mean_score:.4f}")
In [38]:
exec_kfold(dt_clf, folds=5)
Out [38]:
1차 교차 검증 정확도 : 0.7542
2차 교차 검증 정확도 : 0.7809
3차 교차 검증 정확도 : 0.7865
4차 교차 검증 정확도 : 0.7697
5차 교차 검증 정확도 : 0.8202
평균 정확도 : 0.7823
cross_val_score()
In [39]:
from sklearn.model_selection import cross_val_score
In [40]:
scores = cross_val_score(dt_clf, X, y, cv=5)
In [41]:
for iter_count, accuracy in enumerate(scores):
print(f"{iter_count+1}차 교차 검증 정확도 : {accuracy:.4f}")
print(f"평균 정확도 : {np.mean(scores):.4f}") # cross_val_score()는 StratifiedKFold를 사용하기에 KFold와는 결과가 다름
Out [41]:
1차 교차 검증 정확도 : 0.7430
2차 교차 검증 정확도 : 0.7753
3차 교차 검증 정확도 : 0.7921
4차 교차 검증 정확도 : 0.7865
5차 교차 검증 정확도 : 0.8427
평균 정확도 : 0.7879
GridSearchCV
In [42]:
from sklearn.model_selection import GridSearchCV
In [43]:
param = {
'max_depth':[2, 3, 5, 10],
'min_samples_split':[2, 3, 5],
'min_samples_leaf':[1, 5, 8] # root node (트리 최상위), leaf node(트리 최말단) # leaf node가 되기 위한 최소 샘플 수 # defaut 1
}
In [44]:
grid = GridSearchCV(dt_clf, param, cv=5, scoring='accuracy') # 경우의 수: 4*3*3*5
grid.fit(X_train, y_train)
Out [44]:
GridSearchCV(cv=5, estimator=DecisionTreeClassifier(random_state=11),
param_grid={'max_depth': [2, 3, 5, 10],
'min_samples_leaf': [1, 5, 8],
'min_samples_split': [2, 3, 5]},
scoring='accuracy')
In [45]:
pred = grid.predict(X_test)
In [46]:
print("의사결정트리 GridSearchCV 정확도 :", accuracy_score(y_test, pred))
Out [46]:
의사결정트리 GridSearchCV 정확도 : 0.8715083798882681
In [47]:
# 최적 하이머 파라미터
grid.best_params_
Out [47]:
{'max_depth': 3, 'min_samples_leaf': 5, 'min_samples_split': 2}
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기