
Machine Learning (19) - MNIST 손글씨 분류
데이터 불러오기
In [1]:
from sklearn.datasets import fetch_openml
In [2]:
mnist = fetch_openml('mnist_784')
28*28 사이즈의 784개의 자료
In [3]:
type(mnist) # dictionary like
Out [3]:
sklearn.utils.Bunch
In [4]:
mnist.keys()
Out [4]:
dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url'])
In [5]:
mnist.data.shape
Out [5]:
(70000, 784)
In [6]:
mnist.target.shape
Out [6]:
(70000,)
In [7]:
# 타깃 분포 확인
mnist.target.value_counts()
Out [7]:
1 7877
7 7293
3 7141
2 6990
9 6958
0 6903
6 6876
8 6825
4 6824
5 6313
Name: class, dtype: int64
In [8]:
mnist.data.min().min(), mnist.data.max().max()
# 0~255 까지의 256색을 표현 -> 이후에 머신러닝이 숫자에 민감한 로직을 사용하면 0~1로 바꾸기 위해 255로 나눔
Out [8]:
(0.0, 255.0)
랜덤 포레스트
In [9]:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
In [10]:
X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, test_size=0.1)
In [11]:
# 나눠진 타깃 분포 확인
y_train.value_counts()
Out [11]:
1 7117
7 6489
3 6432
2 6291
9 6262
0 6223
6 6207
8 6140
4 6131
5 5708
Name: class, dtype: int64
In [12]:
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
In [13]:
print(f'정확도 : {accuracy:.4f}')
Out [13]:
정확도 : 0.9723
실제 데이터로 확인
In [14]:
import numpy as np
import matplotlib.pyplot as plt
In [15]:
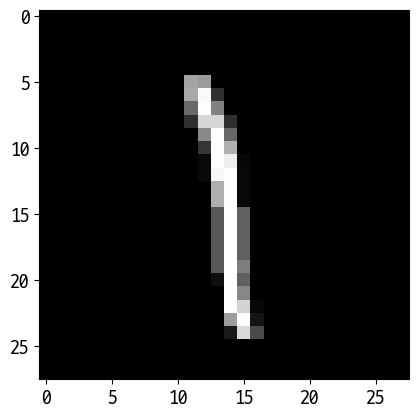
tmp = X_test.iloc[666]
tmp = np.array(tmp)
tmp = tmp.reshape(28, 28)
plt.imshow(tmp, cmap='gray')
y_test.iloc[666]
Out [15]:
'1'
In [16]:
import glob
from PIL import Image
In [17]:
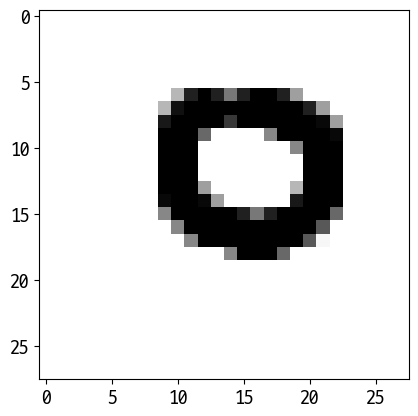
for path in glob.glob('./img/*.png'):
img = Image.open(path).convert('L')
plt.imshow(img, cmap='gray')
img = np.resize(img, (1, 784))
# 흑백 반전, 실수값 전환
img = 255.0 - (img)
pred = clf.predict(img)
print(pred)
plt.show()
Out [17]:
['9']
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
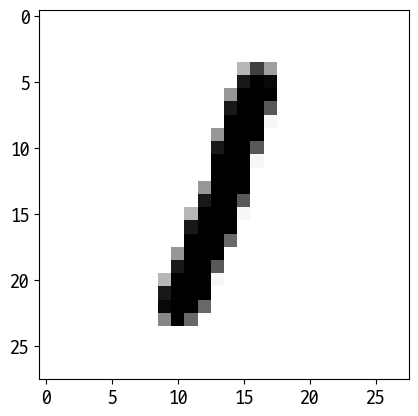
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
['1']
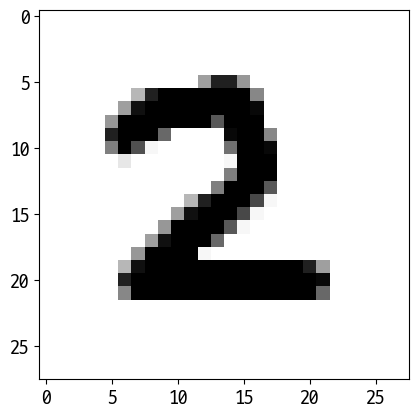
['2']
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
['3']
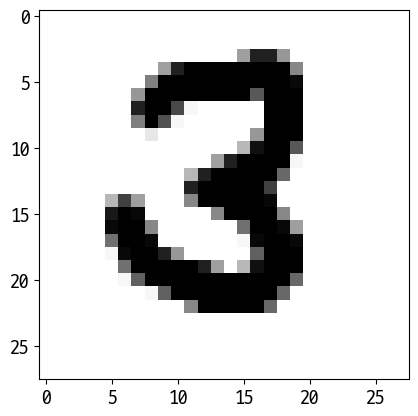
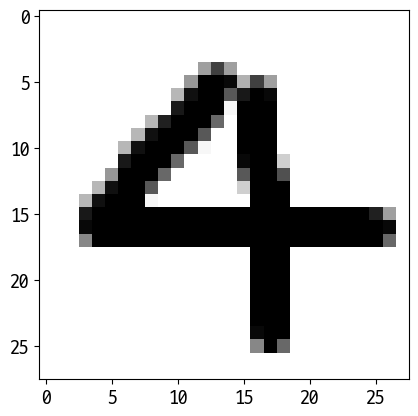
['4']
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
['4']
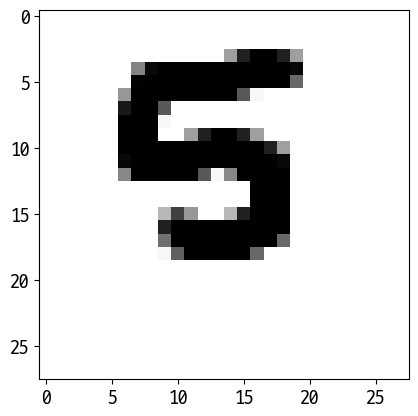
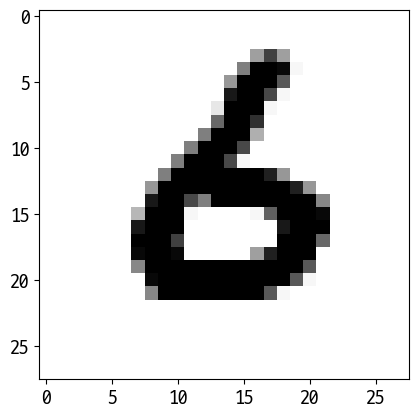
['6']
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
['2']
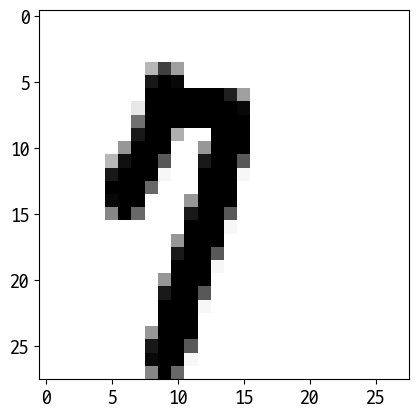
['8']
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
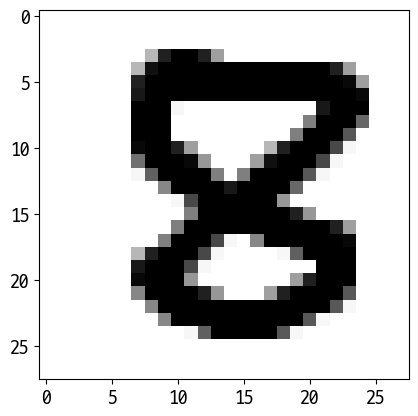
C:\Users\user\anaconda3\lib\site-packages\sklearn\base.py:450: UserWarning: X does not have valid feature names, but RandomForestClassifier was fitted with feature names
warnings.warn(
['8']
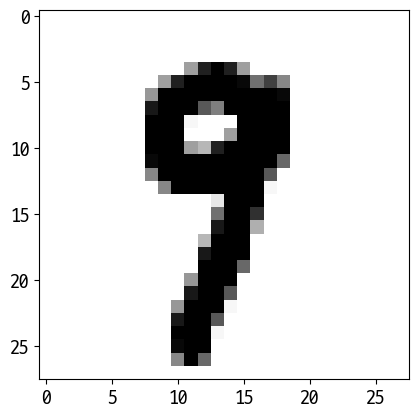
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기