
MySQL (2)
서브 쿼리
하나의 쿼리 구문 내에서 또 다른 쿼리를 사용하는 구문을 말한다.
괄로호 묶어야 한다.
SELECT 절에서의 서브 쿼리
출력되는 서브 쿼리는 하나의 컬럼을 출력해야 한다.
alias가 필수는 아니지만 쓰지 않을 경우 출력결과의 속성이 너무 길어진다.
바깥 쿼리의 컬럼마다 서브쿼리가 실행되어 성능면으로 좋지 않으므로 추천하지 않는다.
-- 제품 분류별 제품수
SELECT part_id, COUNT(*) FROM product GROUP BY part_id;
+---------+----------+
| part_id | COUNT(*) |
+---------+----------+
| 1 | 8 |
| 2 | 16 |
| 3 | 7 |
| 4 | 4 |
| 5 | 16 |
| 6 | 8 |
| 7 | 4 |
| 8 | 7 |
+---------+----------+
SELECT part_id, part_name FROM part;
+---------+-----------+
| part_id | part_name |
+---------+-----------+
| 1 | 프레즐 |
| 2 | 스틱 |
| 3 | 핫도그 |
| 4 | 커피 |
| 5 | 에이드 |
| 6 | 차 |
| 7 | 딥 |
| 8 | 기타 |
+---------+-----------+
SELECT
part_id,
part_name,
(SELECT product_name FROM product WHERE part_id = part.part_id LIMIT 1) product_name
FROM part;
+---------+-----------+--------------------------------+
| part_id | part_name | product_name |
+---------+-----------+--------------------------------+
| 1 | 프레즐 | 오리지날 프레즐 |
| 2 | 스틱 | 오리지날 스틱 |
| 3 | 핫도그 | 블랙올리브치즈핫도그 |
| 4 | 커피 | 아메리카노(hot) |
| 5 | 에이드 | 레몬에이드(H) |
| 6 | 차 | 핫초코 |
| 7 | 딥 | 체다치즈 딥 |
| 8 | 기타 | 시나몬토핑 |
+---------+-----------+--------------------------------+FROM 절에서의 서브 쿼리
반드시 alias를 지정해줘야 한다.
-- ALIAS가 필요한 이유
SELECT SUB.part_tag, SUB.part_name FROM (SELECT * FROM part) SUB;
+----------+-----------+
| part_tag | part_name |
+----------+-----------+
| pretzel | 프레즐 |
| stick | 스틱 |
| hotdog | 핫도그 |
| coffee | 커피 |
| ade | 에이드 |
| tea | 차 |
| dip | 딥 |
| etc | 기타 |
+----------+-----------+WHERE 절에서의 서브 쿼리
연산자에 따라 서브 쿼리 출력결과를 주의 (IN 연산자 뒤에는 여러 결과가 올 수 있다.)
서브 쿼리 연습
-- 제품 중에서 가장 비싼 제품
-- 정렬을 이용하면 중복된 데이터에 대해서는 알 수 없다.
SELECT * FROM product ORDER BY product_price DESC LIMIT 1;
SELECT MAX(product_price) FROM product;
+--------------------+
| MAX(product_price) |
+--------------------+
| 4700 |
+--------------------+SELECT * FROM product WHERE product_price = (SELECT MAX(product_price) FROM product);
-- WHERE절에서의 LIKE사용
SELECT product_name FROM product WHERE product_name LIKE '%프레즐';
+------------------------------+
| product_name |
+------------------------------+
| 오리지날 프레즐 |
| 어니언 프레즐 |
| 갈릭 프레즐 |
| 아몬드 프레즐 |
| 할라피뇨치즈 프레즐 |
+------------------------------+-- 평균가 이상의 제품을 출력해보자.
SELECT product_name, product_price FROM product
WHERE product_price >= (SELECT AVG(product_price) FROM product) ORDER BY product_price;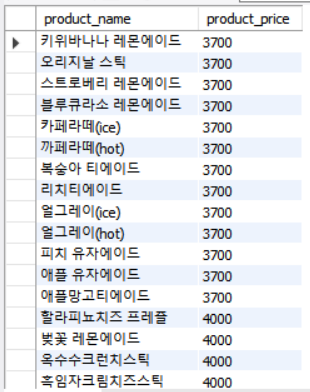
-- 두번째로 값이 높은 제품을 출력해보자.
SELECT MAX(product_price) FROM product;
SELECT MAX(product_price) FROM product
WHERE product_price < (SELECT MAX(product_price) FROM product);
SELECT * FROM product
WHERE product_price = (SELECT MAX(product_price) FROM product
WHERE product_price < (SELECT MAX(product_price) FROM product));
-- 일일별 판매 총액을 출력해보자.
SELECT ordered_date, pay_result, SUM(pay_price)
FROM `order` WHERE pay_result='Y' GROUP BY ordered_date;
SELECT ordered_date, pay_result, SUM(pay_price)
FROM `order` GROUP BY ordered_date, pay_result HAVING pay_result='Y';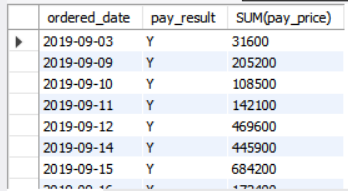
-- orderlist에서 값, order에서 날짜를 가져와 위의 조건를 출력해보자.
-- JOIN과 서브쿼리 이용
SELECT ordered_date, pay_result, SUM(pay_price)
FROM (SELECT * FROM `order` INNER JOIN orderlist USING(order_id)) AS SUB
GROUP BY ordered_date, pay_result HAVING pay_result='Y';
-- orderlist와 product_id에서 제품별 총 판매액
SELECT product_name, SUM(unit_count * (product_price + option_price)) AS sum
FROM (SELECT * FROM product NATURAL JOIN orderlist) A
GROUP BY product_id, product_name;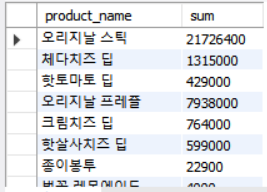
데이터 입력(VIEW, INSERT INTO SELECT)
뷰(VIEW)
-
- 뷰 사용 주의점
- 데이터가 아니라 실시간으로 데이터를 모아서 보여주는 것이다.
뷰는 실제 테이블이 아니다.
기본적으로 SELECT 전용으로 사용이 권장된다. (데이터를 조작가능하지만…)
-- 뷰 생성
CREATE VIEW pay_total AS
SELECT ordered_date, SUM(pay_price) AS total
FROM (SELECT * FROM `order` NATURAL JOIN orderlist) AS S
GROUP BY ordered_date;
-- 뷰 사용
SELECT * FROM pay_total;
-- 뷰 삭제
DROP VIEW pay_total;INSERT INTO SELECT
SELECT 결과로 생성
-- 구조복사->SELECT결과 붙여넣기
CREATE TABLE auth_copy AS SELECT * FROM auth;
-- 테이블 구조만 복사
CREATE TABLE auth2 AS
SELECT * FROM auth WHERE auth_id=0;
-- 데이터 내용을 엑셀로 열어보기
-- 보안상 막아놓음
SELECT * INTO OUTFILE 'c:\\temp\\data.txt' FROM auth;Transaction
InnoDB 엔진이 지원한다.
일련의 절차를 가지는 작업의 단위
커밋(COMMIT), 롤백(ROLLBACK)
세이브포인트(SAVEPOINT)
-
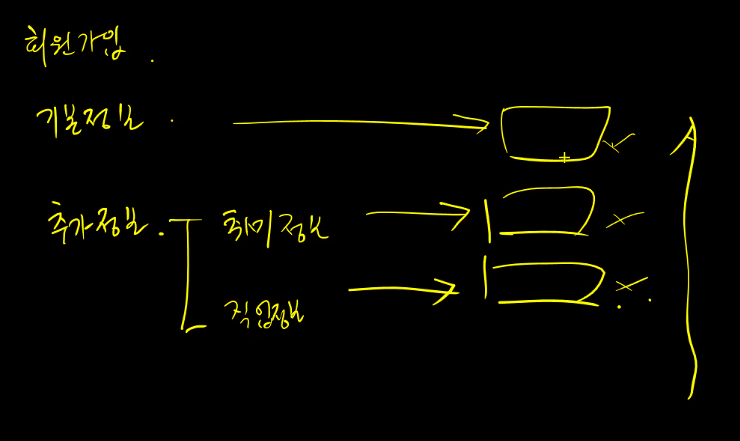
트랜젝션이 필요한 경우
-
트랜젝션이 필요한 경우
-- 자동반영 끄기
SET AUTOCOMMIT=0;
SHOW VARIABLES LIKE 'AUTO%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_generate_certs | ON |
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
| autocommit | OFF |
| automatic_sp_privileges | ON |
+--------------------------+-------+
-- 자동반영 켜기
SET AUTOCOMMIT=1;
SELECT * FROM category;
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_generate_certs | ON |
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
| autocommit | ON |
| automatic_sp_privileges | ON |
+--------------------------+-------+환경변수는 세션별로 각각 설정된다
SET AUTOCOMMIT=0;
SHOW VARIABLES LIKE 'AUTO%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_generate_certs | ON |
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
| autocommit | OFF |
| automatic_sp_privileges | ON |
+--------------------------+-------+
DELETE FROM book;
SELECT * FROM book;
ROLLBACK; -- 되돌리기-- 새로운 트랜젝션 시작
START TRANSACTION;
-- 적용 후 트랜젝션 재시작
COMMIT트랜젝션을 커밋하기 전까지는 다른 유저에게는 바뀐내용이 보이지 않는다.
데이터 편집(UPDATE)
SELECT * FROM category;
+--------+-----------+
| c_code | c_name |
+--------+-----------+
| FT | 소설 |
| LF | 라노벨 |
| RE | 참고서 |
+--------+-----------+
UPDATE category SET c_name = '레퍼런스' WHERE c_code = 'RE';
+--------+--------------+
| c_code | c_name |
+--------+--------------+
| FT | 소설 |
| LF | 라노벨 |
| RE | 레퍼런스 |
+--------+--------------+INSERT INTO book VALUES (1, '참고서', 20000, 'RE');
-- 자식테이블의 제약 - 오류
UPDATE book SET c_code = 'RR' WHERE c_code = 'RE';
-- 부모테이블의 제약 - CASCADE 설정이 적용된다면 둘다 삭제됨 => RESTRICT라면 오류
-- (triger: 참조, 외래키 연결되었을 때의 ON UPDATE ON DELETE)
DELETE FROM category WHERE c_code = 'RE';참조의 무결성으로 UPDATE시에 부모테이블과 자식테이들 둘다 제약을 받는다. (INSERT는 자식만 DELETE는 부모만)
-- 실습을 위한 자료 생성
CREATE TABLE ulist (
id int unsigned auto_increment primary key,
name varchar(50) not null)
engine=innodb default charset=utf8;
INSERT INTO ulist(name) VALUES ('홍길동'), ('심청이'), ('에디슨'), ('강감찬'), ('임꺽정');
DELETE FROM ulist WHERE id = 1; -- MySQL에서는 삭제되지 않는다.MySQL에는 수정과 삭제 시 데이터 안전을 위해 락이 걸려있다.
-- 안전설정 환경변수 변경
SET SQL_SAFE_UPDATES = 0;
DELETE FROM ulist WHERE id = 1;
-- id를 하나씩 줄인다.
UPDATE ulist SET id = id - 1;
-- order by로 처리 순서도 결정할 수 있다.
UPDATE ulist SET id = id + 1 ORDER BY id DESC;
SELECT * FROM ulist;
+----+-----------+
| id | name |
+----+-----------+
| 2 | 심청이 |
| 3 | 에디슨 |
| 4 | 강감찬 |
| 5 | 임꺽정 |
+----+-----------+JOIN을 통한 편집
-- 늑대와 춤을 책값을 10% 올리기
SELECT * FROM book WHERE b_name LIKE '늑대와 춤을';
+--------+------------------+---------+--------+
| b_code | b_name | b_price | c_code |
+--------+------------------+---------+--------+
| FT0001 | 늑대와 춤을 | 15000 | FT |
+--------+------------------+---------+--------+
UPDATE book SET b_price = b_price * 1.1 WHERE b_name = '늑대와 춤을';
SELECT * FROM book WHERE b_name LIKE '늑대와 춤을';
+--------+------------------+---------+--------+
| b_code | b_name | b_price | c_code |
+--------+------------------+---------+--------+
| FT0001 | 늑대와 춤을 | 16500 | FT |
+--------+------------------+---------+--------+-- JOIN default 는 INNER JOIN, 다른 JOIN 모두 가능
-- 분류는 소설이고 이름은 늑대와 춤을 인 책의 값을 20000으로 바꿔보자
UPDATE category NATURAL JOIN book SET b_price = 20000
WHERE c_name = '소설' AND b_name = '늑대와 춤을';
SELECT * FROM book WHERE b_name LIKE '늑대와 춤을';
+--------+------------------+---------+--------+
| b_code | b_name | b_price | c_code |
+--------+------------------+---------+--------+
| FT0001 | 늑대와 춤을 | 20000 | FT |
+--------+------------------+---------+--------+-- inner join
UPDATE category INNER JOIN book USING(c_code) SET b_price = 20000
WHERE c_name = '소설' AND b_name = '늑대와 춤을';
-- theta join
UPDATE category A, book B SET b_price = 15000
WHERE A.c_code = B.c_code AND A.c_name = '소설' AND B.b_name = '늑대와 춤을';
SELECT * FROM book WHERE b_name LIKE '늑대와 춤을';
+--------+------------------+---------+--------+
| b_code | b_name | b_price | c_code |
+--------+------------------+---------+--------+
| FT0001 | 늑대와 춤을 | 15000 | FT |
+--------+------------------+---------+--------+JOIN을 통한 삭제
-- 소설에 포함된 늑대와 춤을 서적정보를 삭제
DELETE book FROM category NATURAL JOIN book
WHERE category.c_name = '소설' AND book.b_name = '늑대와 춤을';
SELECT * FROM category, book
WHERE category.c_code = book.c_code AND b_name = '늑대와 춤을';
-- 참고서 분류의 스프링 부트 서적을 inner join을 이용해 삭제
DELETE B FROM category C JOIN book B USING(c_code)
WHERE C.c_name = '참고서' AND B.b_name = '스프링 부트';
SELECT * FROM category C JOIN book B USING(c_code)
WHERE C.c_name = '참고서' AND B.b_name = '스프링 부트';데이터베이스 모델링
업무분석 - 개념설계 - 논리설계 - 물리설계
물리설계 해보기
CREATE USER project IDENTIFIED BY 'Iloveyou7!';
CREATE DATABASE project;
GRANT all privileges ON project.* TO project;MySQL Workbench에서 작업
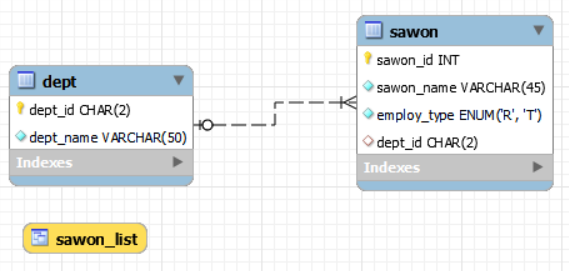
LOAD DATA INFILE
외부의 CSV 파일을 읽어 들여 테이블에 데이터를 저장한다.
보통 옵션으로 잠겨있기에 해제하고 시도해야 한다.
-- mysql 프롬프트에서
SET GLOBAL local_infile=true;# mysql실행 시 옵션을 추가한다.
mysql --local-infile=1 -u root -pLOAD DATA LOCAL INFILE 'dept.CSV' INTO TABLE dept
FIELDS TERMINATED BY ',' -- 필드 구분 문자 default `,`
OPTIONALLY ENCLOSED BY '\'' -- 필드를 감싸는 문자 default `\n`
LINES TERMINATED BY '\n' -- 레코드 구분 문자 default `\n`
IGNORE 1 LINES;LOAD DATA LOCAL INFILE 'sawon.CSV' INTO TABLE sawon
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '\''
LINES TERMINATED BY '\n'
IGNORE 1 LINES;백업과 복원
:: 외부(windows)에서 데이터 입력
mysql -ustudent -p -h192.168.56.100 student < c:\data.txt# 덤프
mysqldump -uroot -p student > student.sql
# 복원
mysql -uroot -p student < student.sql
# 데이터만 덤프
mysqldump -uroot -p --no-create-info student > data.sql
# 데이터 제외 테이블만 덤프
mysqldump -uroot -p --no-data student > create.sql
# 덤프 옵션 도움말
mysqldump --help | lessReference
- 이 포스트는 SeSAC 인공지능 SW 개발자 양성 과정 - 김기희 강사님의 강의내용을 정리한 것입니다.
댓글남기기