
자연어 처리 - 간단한 RNN 예제
간단한 RNN 예제
RNN(Recurrent Neural Network)
In [1]:
text = '''저 별을 따다가 니 귀에 걸어주고파
저 달 따다가 니 목에 걸어주고파
세상 모든 좋은 것만 해주고 싶은
이런 내 맘을 그댄 아나요'''
저? -> 별을
저 별을? -> 따다가
저 별을 따다가? -> 니
저 별을 따다가 니 귀에? -> 걸어주고파
다음에 올 단어를 예측! -> RNN
데이터 전처리
In [2]:
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.utils import to_categorical, pad_sequences
단어 정수화
In [3]:
tok = Tokenizer()
tok.fit_on_texts([text])
tok.word_index
Out [3]:
{'저': 1,
'따다가': 2,
'니': 3,
'걸어주고파': 4,
'별을': 5,
'귀에': 6,
'달': 7,
'목에': 8,
'세상': 9,
'모든': 10,
'좋은': 11,
'것만': 12,
'해주고': 13,
'싶은': 14,
'이런': 15,
'내': 16,
'맘을': 17,
'그댄': 18,
'아나요': 19}
In [4]:
vocab_size = len(tok.word_index) + 1 # zero padding용 공간 추가
vocab_size
Out [4]:
20
문단 정수화
In [5]:
for sentence in text.split('\n'):
res = tok.texts_to_sequences([sentence])[0]
print(res)
Out [5]:
[1, 5, 2, 3, 6, 4]
[1, 7, 2, 3, 8, 4]
[9, 10, 11, 12, 13, 14]
[15, 16, 17, 18, 19]
저? -> 별을
저 별을? -> 따다가
저 별을 따다가? -> 니
저 별을 따다가 니 귀에? -> 걸어주고파
In [6]:
# 다음 단어를 유추할 수 있게 확장
seq_list = []
for sentence in text.split('\n'):
res = tok.texts_to_sequences([sentence])[0]
for i in range(1, len(res)):
seq = res[:i+1]
seq_list.append(seq)
seq_list
Out [6]:
[[1, 5],
[1, 5, 2],
[1, 5, 2, 3],
[1, 5, 2, 3, 6],
[1, 5, 2, 3, 6, 4],
[1, 7],
[1, 7, 2],
[1, 7, 2, 3],
[1, 7, 2, 3, 8],
[1, 7, 2, 3, 8, 4],
[9, 10],
[9, 10, 11],
[9, 10, 11, 12],
[9, 10, 11, 12, 13],
[9, 10, 11, 12, 13, 14],
[15, 16],
[15, 16, 17],
[15, 16, 17, 18],
[15, 16, 17, 18, 19]]
In [7]:
# 최대 문장 길이 구하기
max_len = max(len(sent) for sent in seq_list)
max_len
Out [7]:
6
zero padding
In [8]:
seq_padded = pad_sequences(seq_list, maxlen = max_len)
seq_padded
Out [8]:
array([[ 0, 0, 0, 0, 1, 5],
[ 0, 0, 0, 1, 5, 2],
[ 0, 0, 1, 5, 2, 3],
[ 0, 1, 5, 2, 3, 6],
[ 1, 5, 2, 3, 6, 4],
[ 0, 0, 0, 0, 1, 7],
[ 0, 0, 0, 1, 7, 2],
[ 0, 0, 1, 7, 2, 3],
[ 0, 1, 7, 2, 3, 8],
[ 1, 7, 2, 3, 8, 4],
[ 0, 0, 0, 0, 9, 10],
[ 0, 0, 0, 9, 10, 11],
[ 0, 0, 9, 10, 11, 12],
[ 0, 9, 10, 11, 12, 13],
[ 9, 10, 11, 12, 13, 14],
[ 0, 0, 0, 0, 15, 16],
[ 0, 0, 0, 15, 16, 17],
[ 0, 0, 15, 16, 17, 18],
[ 0, 15, 16, 17, 18, 19]])
In [9]:
# 앞의 단어들(X)이 오면 뒤에 올 단어(y)가 온다고 학습
X = seq_padded[:, :-1]
y = seq_padded[:, -1]
X, y
Out [9]:
(array([[ 0, 0, 0, 0, 1],
[ 0, 0, 0, 1, 5],
[ 0, 0, 1, 5, 2],
[ 0, 1, 5, 2, 3],
[ 1, 5, 2, 3, 6],
[ 0, 0, 0, 0, 1],
[ 0, 0, 0, 1, 7],
[ 0, 0, 1, 7, 2],
[ 0, 1, 7, 2, 3],
[ 1, 7, 2, 3, 8],
[ 0, 0, 0, 0, 9],
[ 0, 0, 0, 9, 10],
[ 0, 0, 9, 10, 11],
[ 0, 9, 10, 11, 12],
[ 9, 10, 11, 12, 13],
[ 0, 0, 0, 0, 15],
[ 0, 0, 0, 15, 16],
[ 0, 0, 15, 16, 17],
[ 0, 15, 16, 17, 18]]),
array([ 5, 2, 3, 6, 4, 7, 2, 3, 8, 4, 10, 11, 12, 13, 14, 16, 17,
18, 19]))
label값의 원-핫 인코딩
In [10]:
y_hot = to_categorical(y, num_classes=vocab_size)
y_hot
Out [10]:
array([[0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 1.]], dtype=float32)
딥러닝
모델 정의, 학습
In [11]:
from keras.models import Sequential
from keras.layers import Embedding, Dense, SimpleRNN
In [12]:
model = Sequential([
Embedding(vocab_size, 10), # vocab_size개의 단어를 10개의 특성으로 나타냄-다음 단어를 유추하기 위한 단어배치 Embedding (Word2Vec의 vector_size)
SimpleRNN(32),
Dense(vocab_size, activation='sigmoid')
])
model.summary()
Out [12]:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 10) 200
simple_rnn (SimpleRNN) (None, 32) 1376
dense (Dense) (None, 20) 660
=================================================================
Total params: 2,236
Trainable params: 2,236
Non-trainable params: 0
_________________________________________________________________
In [13]:
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
In [14]:
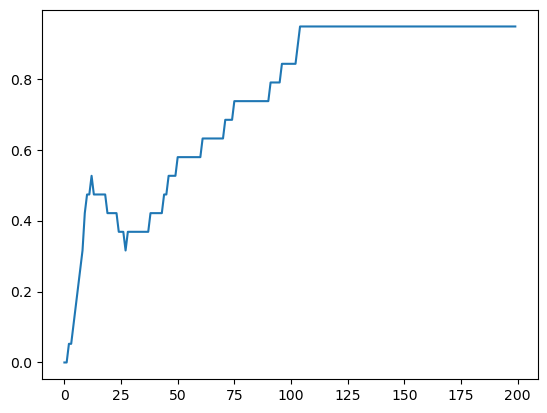
history = model.fit(X, y, epochs=200, verbose=1)
Out [14]:
Epoch 1/200
1/1 [==============================] - 1s 923ms/step - loss: 2.9929 - accuracy: 0.0526
Epoch 2/200
1/1 [==============================] - 0s 4ms/step - loss: 2.9843 - accuracy: 0.0526
Epoch 3/200
1/1 [==============================] - 0s 7ms/step - loss: 2.9757 - accuracy: 0.1053
Epoch 4/200
1/1 [==============================] - 0s 4ms/step - loss: 2.9671 - accuracy: 0.1053
Epoch 5/200
1/1 [==============================] - 0s 5ms/step - loss: 2.9583 - accuracy: 0.1053
...
Epoch 196/200
1/1 [==============================] - 0s 5ms/step - loss: 0.3381 - accuracy: 0.9474
Epoch 197/200
1/1 [==============================] - 0s 5ms/step - loss: 0.3345 - accuracy: 0.9474
Epoch 198/200
1/1 [==============================] - 0s 3ms/step - loss: 0.3310 - accuracy: 0.9474
Epoch 199/200
1/1 [==============================] - 0s 3ms/step - loss: 0.3275 - accuracy: 0.9474
Epoch 200/200
1/1 [==============================] - 0s 5ms/step - loss: 0.3241 - accuracy: 0.9474
In [15]:
import matplotlib.pyplot as plt
plt.plot(history.history['accuracy'])
Out [15]:
[<matplotlib.lines.Line2D at 0x22c66f06670>]
예측
In [16]:
start_text = '이런 내 맘을 그댄' # expect: 아나요
encoded = tok.texts_to_sequences([start_text])[0]
encoded
Out [16]:
[15, 16, 17, 18]
In [17]:
pedded = pad_sequences([encoded], maxlen=max_len)
pedded
Out [17]:
array([[ 0, 0, 15, 16, 17, 18]])
In [18]:
res = model.predict(pedded, verbose=1)
res
Out [18]:
1/1 [==============================] - 0s 151ms/step
array([[0.23961598, 0.5145148 , 0.23955514, 0.47244322, 0.64895254,
0.10036285, 0.8044668 , 0.11209651, 0.5889684 , 0.44754112,
0.19595115, 0.24980979, 0.5465937 , 0.86290205, 0.06897352,
0.5562962 , 0.23613842, 0.04350452, 0.5932769 , 0.99096566]],
dtype=float32)
In [19]:
res_softmax = np.argmax(res, axis=1)
res_softmax
Out [19]:
array([19], dtype=int64)
In [20]:
start_text, *tok.sequences_to_texts([res_softmax])
Out [20]:
('이런 내 맘을 그댄', '아나요')
In [21]:
start_text = '저 별을 따다가 니' # expect: 귀에
encoded = tok.texts_to_sequences([start_text])[0]
pedded = pad_sequences([encoded], maxlen=max_len)
res = model.predict(pedded, verbose=1)
res_softmax = np.argmax(res, axis=1)
print(f'{start_text}:', *tok.sequences_to_texts([res_softmax]))
Out [21]:
1/1 [==============================] - 0s 17ms/step
저 별을 따다가 니: 귀에
In [22]:
def word_predict(string):
start_text = string
encoded = tok.texts_to_sequences([start_text])[0]
pedded = pad_sequences([encoded], maxlen=max_len)
res = model.predict(pedded, verbose=1)
res_softmax = np.argmax(res, axis=1)
print(f'{start_text}:', *tok.sequences_to_texts([res_softmax]))
In [23]:
word_predict('저 별을 따다가 니')
Out [23]:
1/1 [==============================] - 0s 15ms/step
저 별을 따다가 니: 귀에
단순히 어떤 단어가 뒤에 올지에 대한 특성이므로 Embedding으로 문맥을 학습하기는 제한적이다.
원-핫 인코딩한 label로 학습
In [24]:
model2 = Sequential([
Embedding(vocab_size, 10), # vocab_size개의 단어를 10개의 특성으로 나타냄-다음 단어를 유추하기 위한 단어배치 Embedding (Word2Vec의 vector_size)
SimpleRNN(32),
Dense(vocab_size, activation='softmax')
])
model2.summary()
Out [24]:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 10) 200
simple_rnn_1 (SimpleRNN) (None, 32) 1376
dense_1 (Dense) (None, 20) 660
=================================================================
Total params: 2,236
Trainable params: 2,236
Non-trainable params: 0
_________________________________________________________________
In [25]:
model2.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
In [26]:
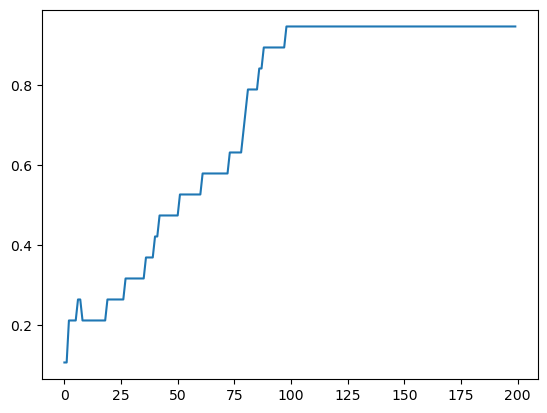
history2 = model2.fit(X, y_hot, epochs=200, verbose=1)
Out [26]:
Epoch 1/200
1/1 [==============================] - 1s 807ms/step - loss: 2.9847 - accuracy: 0.1053
Epoch 2/200
1/1 [==============================] - 0s 5ms/step - loss: 2.9756 - accuracy: 0.1053
Epoch 3/200
1/1 [==============================] - 0s 4ms/step - loss: 2.9664 - accuracy: 0.2105
Epoch 4/200
1/1 [==============================] - 0s 4ms/step - loss: 2.9572 - accuracy: 0.2105
Epoch 5/200
1/1 [==============================] - 0s 6ms/step - loss: 2.9479 - accuracy: 0.2105
...
Epoch 196/200
1/1 [==============================] - 0s 4ms/step - loss: 0.2396 - accuracy: 0.9474
Epoch 197/200
1/1 [==============================] - 0s 5ms/step - loss: 0.2371 - accuracy: 0.9474
Epoch 198/200
1/1 [==============================] - 0s 4ms/step - loss: 0.2348 - accuracy: 0.9474
Epoch 199/200
1/1 [==============================] - 0s 6ms/step - loss: 0.2324 - accuracy: 0.9474
Epoch 200/200
1/1 [==============================] - 0s 3ms/step - loss: 0.2301 - accuracy: 0.9474
In [27]:
plt.plot(history2.history['accuracy'])
Out [27]:
[<matplotlib.lines.Line2D at 0x22c6987fdf0>]
댓글남기기