
자연어 처리 - BERT와 한국어 텍스트 분류
BERT
- 언어 모델(Language modeling)
다음 단어가 무엇인지, 어떤 확률로 등장할지를 나타내는 값
버트는 기존 방식인 앞의 단어들을 사용해 다음 단어를 예측하는 것에서 특정 단어를 가리고 앞뒤 상관없이 문장 안의 단어들을 모두 사용해서 가려진 단어들을 예측한다. (양방향)
기본 모델 구조는 트랜스포머 이며 버트는 트랜스포머의 인코더 구조만 사용한다.
언어적 용인 가능성, 자연어 추론, 유사도 예측, 감정 분석, 개체명 인식, 기계독해 등 특히 분류에 사용된다
버트를 활용한 한국어 텍스트 분류 모델
In [1]:
from google.colab import drive
drive.mount('/content/drive')
Out [1]:
Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True).
In [2]:
!pip install transformers
Out [2]:
Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/
Requirement already satisfied: transformers in /usr/local/lib/python3.8/dist-packages (4.25.1)
Requirement already satisfied: filelock in /usr/local/lib/python3.8/dist-packages (from transformers) (3.9.0)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.8/dist-packages (from transformers) (4.64.1)
Requirement already satisfied: requests in /usr/local/lib/python3.8/dist-packages (from transformers) (2.25.1)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.8/dist-packages (from transformers) (2022.6.2)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.8/dist-packages (from transformers) (1.21.6)
Requirement already satisfied: huggingface-hub<1.0,>=0.10.0 in /usr/local/lib/python3.8/dist-packages (from transformers) (0.11.1)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.8/dist-packages (from transformers) (6.0)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.8/dist-packages (from transformers) (21.3)
Requirement already satisfied: tokenizers!=0.11.3,<0.14,>=0.11.1 in /usr/local/lib/python3.8/dist-packages (from transformers) (0.13.2)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.8/dist-packages (from huggingface-hub<1.0,>=0.10.0->transformers) (4.4.0)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/local/lib/python3.8/dist-packages (from packaging>=20.0->transformers) (3.0.9)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.8/dist-packages (from requests->transformers) (2022.12.7)
Requirement already satisfied: chardet<5,>=3.0.2 in /usr/local/lib/python3.8/dist-packages (from requests->transformers) (4.0.0)
Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.8/dist-packages (from requests->transformers) (1.24.3)
Requirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.8/dist-packages (from requests->transformers) (2.10)
In [3]:
import os
import re
import numpy as np
from tqdm import tqdm
import tensorflow as tf
from transformers import *
from keras.utils import pad_sequences
from keras.callbacks import EarlyStopping, ModelCheckpoint
import pandas as pd
import matplotlib.pyplot as plt
Out [3]:
/usr/local/lib/python3.8/dist-packages/transformers/generation_utils.py:24: FutureWarning: Importing `GenerationMixin` from `src/transformers/generation_utils.py` is deprecated and will be removed in Transformers v5. Import as `from transformers import GenerationMixin` instead.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/transformers/generation_tf_utils.py:24: FutureWarning: Importing `TFGenerationMixin` from `src/transformers/generation_tf_utils.py` is deprecated and will be removed in Transformers v5. Import as `from transformers import TFGenerationMixin` instead.
warnings.warn(
In [4]:
# 시각화
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string], '')
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
In [5]:
#random seed 고정
tf.random.set_seed(1234)
np.random.seed(1234)
BATCH_SIZE = 32
NUM_EPOCHS = 3
VALID_SPLIT = 0.2
MAX_LEN = 39 # EDA에서 추출된 Max Length
DATA_IN_PATH = "/content/drive/MyDrive/Colab Notebooks/BERT_review_cls/"#'data_in/KOR'
DATA_OUT_PATH = "/content/drive/MyDrive/Colab Notebooks/BERT_review_cls/"
In [6]:
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased", cache_dir='bert_ckpt', do_lower_case=False)
Out [6]:
loading file vocab.txt from cache at bert_ckpt/models--bert-base-multilingual-cased/snapshots/fdfce55e83dbed325647a63e7e1f5de19f0382ba/vocab.txt
loading file added_tokens.json from cache at None
loading file special_tokens_map.json from cache at None
loading file tokenizer_config.json from cache at bert_ckpt/models--bert-base-multilingual-cased/snapshots/fdfce55e83dbed325647a63e7e1f5de19f0382ba/tokenizer_config.json
loading configuration file config.json from cache at bert_ckpt/models--bert-base-multilingual-cased/snapshots/fdfce55e83dbed325647a63e7e1f5de19f0382ba/config.json
Model config BertConfig {
"_name_or_path": "bert-base-multilingual-cased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"transformers_version": "4.25.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 119547
}
토크나이저 테스트
In [7]:
test_sentence = "안녕하세요, 반갑습니다."
encode = tokenizer.encode(test_sentence)
token_print = [tokenizer.decode(token) for token in encode]
print(encode)
print(token_print)
Out [7]:
[101, 9521, 118741, 35506, 24982, 48549, 117, 9321, 118610, 119081, 48345, 119, 102]
['[ C L S ]', '안', '# # 녕', '# # 하', '# # 세', '# # 요', ',', '반', '# # 갑', '# # 습', '# # 니 다', '.', '[ S E P ]']
In [8]:
kor_encode = tokenizer.encode("안녕하세요, 반갑습니다")
eng_encode = tokenizer.encode("Hello world")
kor_decode = tokenizer.decode(kor_encode)
eng_decode = tokenizer.decode(eng_encode)
print(kor_encode)
# [101, 9521, 118741, 35506, 24982, 48549, 117, 9321, 118610, 119081, 48345, 102]
print(eng_encode)
# [101, 31178, 11356, 102]
print(kor_decode)
# [CLS] 안녕하세요, 반갑습니다 [SEP]
print(eng_decode)
# [CLS] Hello world [SEP]
Out [8]:
[101, 9521, 118741, 35506, 24982, 48549, 117, 9321, 118610, 119081, 48345, 102]
[101, 31178, 11356, 102]
[CLS] 안녕하세요, 반갑습니다 [SEP]
[CLS] Hello world [SEP]
데이터 전처리
In [9]:
# 데이터 전처리 준비
DATA_TRAIN_PATH = os.path.join(DATA_IN_PATH, "naver_movie", "ratings_train.txt")
DATA_TEST_PATH = os.path.join(DATA_IN_PATH, "naver_movie", "ratings_test.txt")
train_data = pd.read_csv(DATA_TRAIN_PATH, header = 0, delimiter = '\t', quoting = 3)
train_data = train_data.dropna()
train_data.head()
Out [9]:
| id | document | label | |
|---|---|---|---|
| 0 | 9976970 | 아 더빙.. 진짜 짜증나네요 목소리 | 0 |
| 1 | 3819312 | 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 | 1 |
| 2 | 10265843 | 너무재밓었다그래서보는것을추천한다 | 0 |
| 3 | 9045019 | 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 | 0 |
| 4 | 6483659 | 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 ... | 1 |
In [10]:
# 스페셜 토큰
print(tokenizer.all_special_tokens, "\n", tokenizer.all_special_ids)
# 토크나이저 테스트하기
kor_encode = tokenizer.encode("안녕하세요, 반갑습니다. ")
eng_encode = tokenizer.encode("Hello world")
kor_decode = tokenizer.decode(kor_encode)
eng_decode = tokenizer.decode(eng_encode)
print(kor_encode)
print(eng_encode)
print(kor_decode)
print(eng_decode)
Out [10]:
['[UNK]', '[SEP]', '[PAD]', '[CLS]', '[MASK]']
[100, 102, 0, 101, 103]
[101, 9521, 118741, 35506, 24982, 48549, 117, 9321, 118610, 119081, 48345, 119, 102]
[101, 31178, 11356, 102]
[CLS] 안녕하세요, 반갑습니다. [SEP]
[CLS] Hello world [SEP]
In [11]:
# Bert Tokenizer
# 참조: https://huggingface.co/transformers/main_classes/tokenizer.html?highlight=encode_plus#transformers.PreTrainedTokenizer.encode_plus
def bert_tokenizer(sent, MAX_LEN):
encoded_dict = tokenizer.encode_plus(
text = sent,
add_special_tokens = True, # Add '[CLS]' and '[SEP]'
max_length = MAX_LEN, # Pad & truncate all sentences.
truncation = True,
padding = 'max_length',
# pad_to_max_length = True,
return_attention_mask = True # Construct attn. masks.
)
input_id = encoded_dict['input_ids']
attention_mask = encoded_dict['attention_mask'] # And its attention mask (simply differentiates padding from non-padding).
token_type_id = encoded_dict['token_type_ids'] # differentiate two sentences
return input_id, attention_mask, token_type_id
In [12]:
# train_data = train_data[:1000] # for test
input_ids = []
attention_masks = []
token_type_ids = []
train_data_labels = []
for train_sent, train_label in tqdm(zip(train_data["document"], train_data["label"]), total=len(train_data)):
try:
input_id, attention_mask, token_type_id = bert_tokenizer(train_sent, MAX_LEN)
input_ids.append(input_id)
attention_masks.append(attention_mask)
token_type_ids.append(token_type_id)
train_data_labels.append(train_label)
except Exception as e:
print(e)
print(train_sent)
pass
train_movie_input_ids = np.array(input_ids, dtype=int)
train_movie_attention_masks = np.array(attention_masks, dtype=int)
train_movie_type_ids = np.array(token_type_ids, dtype=int)
train_movie_inputs = (train_movie_input_ids, train_movie_attention_masks, train_movie_type_ids)
train_data_labels = np.asarray(train_data_labels, dtype=np.int32) #레이블 토크나이징 리스트
print("# sents: {}, # labels: {}".format(len(train_movie_input_ids), len(train_data_labels)))
Out [12]:
100%|██████████| 149995/149995 [01:13<00:00, 2033.64it/s]
# sents: 149995, # labels: 149995
In [13]:
# 최대 길이: 39
input_id = train_movie_input_ids[1]
attention_mask = train_movie_attention_masks[1]
token_type_id = train_movie_type_ids[1]
print(input_id)
print(attention_mask)
print(token_type_id)
print(tokenizer.decode(input_id))
Out [13]:
[ 101 100 119 119 119 9928 58823 30005 11664 9757
118823 30858 18227 119219 119 119 119 119 9580 41605
25486 12310 20626 23466 8843 118986 12508 9523 17196 16439
102 0 0 0 0 0 0 0 0]
[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0
0 0]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0]
[CLS] [UNK]... 포스터보고 초딩영화줄.... 오버연기조차 가볍지 않구나 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
In [14]:
class TFBertClassifier(tf.keras.Model):
def __init__(self, model_name, dir_path, num_class):
super(TFBertClassifier, self).__init__()
self.bert = TFBertModel.from_pretrained(model_name, cache_dir=dir_path)
self.dropout = tf.keras.layers.Dropout(self.bert.config.hidden_dropout_prob)
self.classifier = tf.keras.layers.Dense(num_class,
kernel_initializer=tf.keras.initializers.TruncatedNormal(self.bert.config.initializer_range),
name="classifier")
def call(self, inputs, attention_mask=None, token_type_ids=None, training=False):
#outputs 값: # sequence_output, pooled_output, (hidden_states), (attentions)
outputs = self.bert(inputs, attention_mask=attention_mask, token_type_ids=token_type_ids)
pooled_output = outputs[1]
pooled_output = self.dropout(pooled_output, training=training)
logits = self.classifier(pooled_output)
return logits
cls_model = TFBertClassifier(model_name='bert-base-multilingual-cased',
dir_path='bert_ckpt',
num_class=2)
Out [14]:
loading configuration file config.json from cache at bert_ckpt/models--bert-base-multilingual-cased/snapshots/fdfce55e83dbed325647a63e7e1f5de19f0382ba/config.json
Model config BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"transformers_version": "4.25.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 119547
}
Downloading: 0%| | 0.00/1.08G [00:00<?, ?B/s]
loading weights file tf_model.h5 from cache at bert_ckpt/models--bert-base-multilingual-cased/snapshots/fdfce55e83dbed325647a63e7e1f5de19f0382ba/tf_model.h5
Some layers from the model checkpoint at bert-base-multilingual-cased were not used when initializing TFBertModel: ['mlm___cls', 'nsp___cls']
- This IS expected if you are initializing TFBertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFBertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the layers of TFBertModel were initialized from the model checkpoint at bert-base-multilingual-cased.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFBertModel for predictions without further training.
In [15]:
# 학습 준비하기
optimizer = tf.keras.optimizers.Adam(3e-5)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
cls_model.compile(optimizer=optimizer, loss=loss, metrics=[metric])
In [16]:
model_name = "tf2_bert_naver_movie"
# overfitting을 막기 위한 ealrystop 추가
earlystop_callback = EarlyStopping(monitor='val_accuracy', min_delta=0.0001,patience=2)
# min_delta: the threshold that triggers the termination (acc should at least improve 0.0001)
# patience: no improvment epochs (patience = 1, 1번 이상 상승이 없으면 종료)\
checkpoint_path = os.path.join(DATA_OUT_PATH, model_name, 'weights.h5')
checkpoint_dir = os.path.dirname(checkpoint_path)
# Create path if exists
if os.path.exists(checkpoint_dir):
print("{} -- Folder already exists \n".format(checkpoint_dir))
else:
os.makedirs(checkpoint_dir, exist_ok=True)
print("{} -- Folder create complete \n".format(checkpoint_dir))
cp_callback = ModelCheckpoint(
checkpoint_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=True)
# 학습과 eval 시작
history = cls_model.fit(train_movie_inputs, train_data_labels, epochs=NUM_EPOCHS, batch_size=BATCH_SIZE,
validation_split = VALID_SPLIT, callbacks=[earlystop_callback, cp_callback])
#steps_for_epoch
print(history.history)
Out [16]:
/content/drive/MyDrive/Colab Notebooks/BERT_review_cls/tf2_bert_naver_movie -- Folder already exists
Epoch 1/3
3750/3750 [==============================] - ETA: 0s - loss: 0.4192 - accuracy: 0.8034
Epoch 1: val_accuracy improved from -inf to 0.84789, saving model to /content/drive/MyDrive/Colab Notebooks/BERT_review_cls/tf2_bert_naver_movie/weights.h5
3750/3750 [==============================] - 1184s 311ms/step - loss: 0.4192 - accuracy: 0.8034 - val_loss: 0.3522 - val_accuracy: 0.8479
Epoch 2/3
3750/3750 [==============================] - ETA: 0s - loss: 0.3285 - accuracy: 0.8563
Epoch 2: val_accuracy improved from 0.84789 to 0.85723, saving model to /content/drive/MyDrive/Colab Notebooks/BERT_review_cls/tf2_bert_naver_movie/weights.h5
3750/3750 [==============================] - 1160s 309ms/step - loss: 0.3285 - accuracy: 0.8563 - val_loss: 0.3239 - val_accuracy: 0.8572
Epoch 3/3
3750/3750 [==============================] - ETA: 0s - loss: 0.2739 - accuracy: 0.8841
Epoch 3: val_accuracy improved from 0.85723 to 0.86046, saving model to /content/drive/MyDrive/Colab Notebooks/BERT_review_cls/tf2_bert_naver_movie/weights.h5
3750/3750 [==============================] - 1159s 309ms/step - loss: 0.2739 - accuracy: 0.8841 - val_loss: 0.3285 - val_accuracy: 0.8605
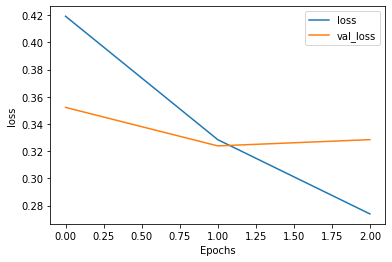
{'loss': [0.4192160665988922, 0.3284885287284851, 0.2738771438598633], 'accuracy': [0.8034268021583557, 0.8563368916511536, 0.8841127753257751], 'val_loss': [0.35219264030456543, 0.3238900601863861, 0.32848498225212097], 'val_accuracy': [0.8478949069976807, 0.8572285771369934, 0.8604620099067688]}
In [17]:
plot_graphs(history, 'loss')
Out [17]:
모델 테스트
In [18]:
test_data = pd.read_csv(DATA_TEST_PATH, header = 0, delimiter = '\t', quoting = 3)
test_data = test_data.dropna()
test_data.head()
Out [18]:
| id | document | label | |
|---|---|---|---|
| 0 | 6270596 | 굳 ㅋ | 1 |
| 1 | 9274899 | GDNTOPCLASSINTHECLUB | 0 |
| 2 | 8544678 | 뭐야 이 평점들은.... 나쁘진 않지만 10점 짜리는 더더욱 아니잖아 | 0 |
| 3 | 6825595 | 지루하지는 않은데 완전 막장임... 돈주고 보기에는.... | 0 |
| 4 | 6723715 | 3D만 아니었어도 별 다섯 개 줬을텐데.. 왜 3D로 나와서 제 심기를 불편하게 하죠?? | 0 |
In [19]:
input_ids = []
attention_masks = []
token_type_ids = []
test_data_labels = []
for test_sent, test_label in tqdm(zip(test_data["document"], test_data["label"])):
try:
input_id, attention_mask, token_type_id = bert_tokenizer(test_sent, MAX_LEN)
input_ids.append(input_id)
attention_masks.append(attention_mask)
token_type_ids.append(token_type_id)
test_data_labels.append(test_label)
except Exception as e:
print(e)
print(test_sent)
pass
test_movie_input_ids = np.array(input_ids, dtype=int)
test_movie_attention_masks = np.array(attention_masks, dtype=int)
test_movie_type_ids = np.array(token_type_ids, dtype=int)
test_movie_inputs = (test_movie_input_ids, test_movie_attention_masks, test_movie_type_ids)
test_data_labels = np.asarray(test_data_labels, dtype=np.int32) #레이블 토크나이징 리스트
print("num sents, labels {}, {}".format(len(test_movie_input_ids), len(test_data_labels)))
Out [19]:
49997it [00:15, 3141.60it/s]
num sents, labels 49997, 49997
In [20]:
results = cls_model.evaluate(test_movie_inputs, test_data_labels, batch_size=1024)
print("test loss, test acc: ", results)
Out [20]:
49/49 [==============================] - 113s 2s/step - loss: 0.3333 - accuracy: 0.8580
test loss, test acc: [0.333324134349823, 0.8580114841461182]
댓글남기기