
자연어 처리 - Transformer와 챗봇 만들기
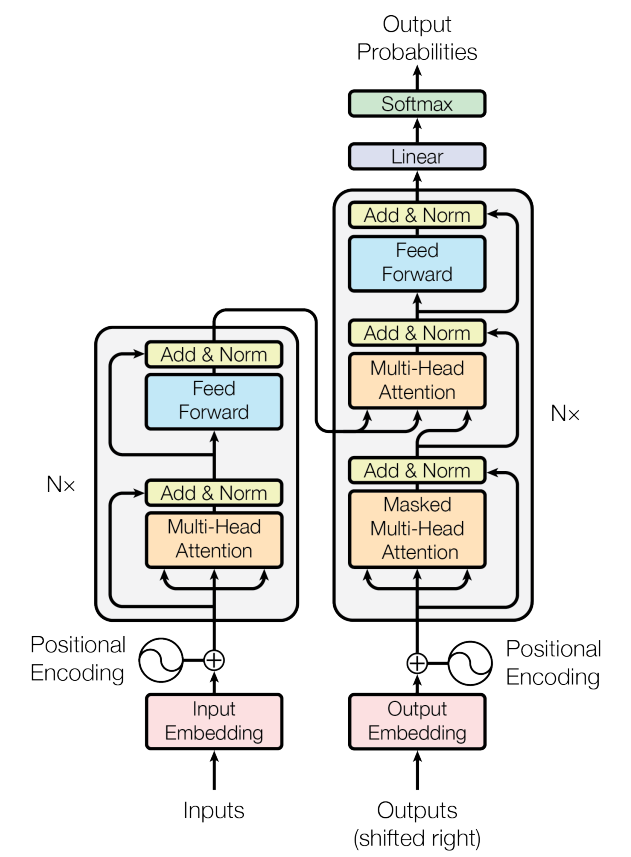
Transformer 모델
기존의 시퀀스 투 시퀀스의 인코더 디코더 구조를 가지고 있지만 CNN, RNN을 기반으로 구성된 기존 모델과 다르게 단순히 어텐션 구조만으로 전체 모델을 만들어 어텐션 기법의 중요성을 강조했다.
기계 번역, 문장 생성 등 다양한 분야에 사용되고 대부분 더 좋은 성능을 보여준다.
- RNN의 문제
- RNN은 병렬처리 연산이 불가능하다!
RNN은 이전 시간축(단어)에서 연산한 결과를 다음 시간축(단어)의 연산에 넣어줘야 하는 재귀적인 특성을 가지기 떄문이다. - 입력과 출력간의 대응되는 단어들 사이의 물리적인 거리가 멀다면 아무리 어텐션을 적용한다고 해도 대응관계를 잘 학습하지 못할 수가 있다.
문장의 길이가 긴 경우에 모든 단어의 정보가 잘 반영된다고 보기 어렵다.
- RNN은 병렬처리 연산이 불가능하다!
-
셀프 어텐션(self-attention)
문장에서 각 단어끼리 얼마나 관계가 있는지를 계산해서 반영하는 방법
문장 안에서 단어들 간의 관계를 측정할 수 있다. - 기존 seq2seq에서 사용하던 어텐션과의 차이
기존 어텐션은 입력-출력 간에 대응되는 단어 관계를 학습
셀프 어텐션은 각 시퀀스 내부의 단어들 간의 대응 관계를 학습 => 기존 seq2seq의 RNN을 대체
-
포지션 인코딩(Positional Encoding)
seq2seq는 RNN을 사용하기 때문에 시퀀스 내부의 시간적인 순서를 고려할 수 있었다.
RNN을 사용하지 않는 transformer 모델에서 단어를 입력할 경우 한번에 넣게 되므로 순서에 대한 정보를 반영하기 위해 사용하는 기법이다. -
삼각함수를 사용하는 이유
sin, cos는 본질적으로 같은 파형이다. (인접한 것이 겹치지 않게 따로 적용)
좌우 시프트가 용이해지므로 순서 정보 주입에 sin, cos를 적용해 준다.
챗봇 만들기 - transformer
preprocess.py
데이터 불러오기, 다양한 기능의 함수 구현
In [1]:
import os, re, json
import numpy as np
import pandas as pd
from tqdm import tqdm
from konlpy.tag import Okt
In [2]:
FILTERS = "([~.,!?\"':;)(])"
PAD = "<PAD>"
STD = "<SOS>"
END = "<END>"
UNK = "<UNK>"
PAD_INDEX = 0
STD_INDEX = 1
END_INDEX = 2
UNK_INDEX = 3
MARKER = [PAD, STD, END, UNK]
CHANGE_FILTER = re.compile(FILTERS)
MAX_SEQUENCE = 25
데이터 불러오기
In [3]:
def load_data(path):
data_df = pd.read_csv(path, header=0)
data_df = data_df[:111] # ..시간단축을 위해..
question, answer = list(data_df['Q']), list(data_df['A'])
return question, answer
In [4]:
def data_tokenizer(data):
words = []
for sent in data:
sent = re.sub(CHANGE_FILTER, "", sent)
for word in sent.split():
words.append(word)
return [word for word in words if word]
In [5]:
def prepro_like_morphlized(data):
morph_analyzer = Okt()
result_data = list()
for seq in tqdm(data):
morphlized_seq = " ".join(morph_analyzer.morphs(seq.replace(' ', '')))
result_data.append(morphlized_seq)
return result_data
단어사전 만들기
In [6]:
def load_vocabulary(path, vocab_path, tokenize_as_morph=False):
vocab_list = []
if not os.path.exists(vocab_path):
if os.path.exists(path):
data_df = pd.read_csv(path, encoding='utf-8')
question, answer = list(data_df['Q']), list(data_df['A'])
if tokenize_as_morph:
question = prepro_like_morphlized(question)
answer = prepro_like_morphlized(answer)
data = []
data.extend(question)
data.extend(answer)
words = data_tokenizer(data)
words = list(set(words))
words[:0] = MARKER
with open(vocab_path, 'w', encoding='utf-8') as vf:
for word in words:
vf.write(word + '\n')
with open(vocab_path, 'r', encoding='utf-8') as vf:
for line in vf:
vocab_list.append(line.strip()) # 줄바꿈 제거
word2idx, idx2word = make_vocabulary(vocab_list)
return word2idx, idx2word, len(word2idx)
In [7]:
def make_vocabulary(vocab_list):
word2idx = {word:idx for idx, word in enumerate(vocab_list)}
idx2word = {idx:word for idx, word in enumerate(vocab_list)}
return word2idx, idx2word
전처리
In [8]:
def enc_processing(value, dictionary, tokenize_as_morph=False):
sequences_input_idx = []
sequences_length = []
if tokenize_as_morph:
value = prepro_like_morphlized(value)
for sequence in value:
sequence = re.sub(CHANGE_FILTER, "", sequence)
sequence_idx = []
for word in sequence.split():
if dictionary.get(word) is not None:
sequence_idx.extend([dictionary[word]])
else:
sequence_idx.extend([dictionary[UNK]])
if len(sequence_idx) > MAX_SEQUENCE:
sequence_idx = sequence_idx[:MAX_SEQUENCE]
sequences_length.append(len(sequence_idx))
sequence_idx += (MAX_SEQUENCE - len(sequence_idx)) * [dictionary[PAD]]
sequences_input_idx.append(sequence_idx)
return np.asarray(sequences_input_idx), sequences_length
In [9]:
def dec_input_processing(value, dictionary, tokenize_as_morph=False):
sequences_input_idx = []
sequences_length = []
if tokenize_as_morph:
value=prepro_like_morphlized(value)
for sequence in value:
sequence = re.sub(CHANGE_FILTER, "", sequence)
sequence_idx = [dictionary[STD]] + [dictionary[word] if word in dictionary else dictionary[UNK] for word in sequence.split()]
if len(sequence_idx) > MAX_SEQUENCE:
sequence_idx = sequence_idx[:MAX_SEQUENCE]
sequences_length.append(len(sequence_idx))
sequence_idx += (MAX_SEQUENCE - len(sequence_idx)) * [dictionary[PAD]]
sequences_input_idx.append(sequence_idx)
return np.asarray(sequences_input_idx), sequences_length
In [10]:
def dec_target_processing(value, dictionary, tokenize_as_morph=False):
sequences_target_idx = []
if tokenize_as_morph:
value = prepro_like_morphlized(value)
for sequence in value:
sequence = re.sub(CHANGE_FILTER, "", sequence)
sequence_idx = [dictionary[word] if word in dictionary else dictionary[UNK] for word in sequence.split()]
if len(sequence_idx) >= MAX_SEQUENCE:
sequence_idx = sequence_idx[:MAX_SEQUENCE-1] + [dictionary[END]]
else:
sequence_idx += [dictionary[END]]
sequence_idx += (MAX_SEQUENCE - len(sequence_idx)) * [dictionary[PAD]]
sequences_target_idx.append(sequence_idx)
return np.asarray(sequences_target_idx)
Preprocess.ipynb
preprocess.py의 함수를 불러와 학습 데이터 준비
In [11]:
# from preprocess import *
PATH = 'datasets/data_in/ChatBotData.csv'
VOCAB_PATH = 'datasets/data_in/vocabulary.txt'
In [12]:
os.remove(VOCAB_PATH)
In [13]:
inputs, outputs = load_data(PATH)
char2idx, idx2char, vocab_size = load_vocabulary(PATH, VOCAB_PATH, tokenize_as_morph=True)
Out [13]:
100%|███████████████████████████████████████████████████████████████████████████| 11823/11823 [00:14<00:00, 839.40it/s]
100%|███████████████████████████████████████████████████████████████████████████| 11823/11823 [00:14<00:00, 797.71it/s]
In [14]:
idx_inputs, input_seq_len = enc_processing(inputs, char2idx, tokenize_as_morph=True)
idx_outputs, output_seq_len = dec_input_processing(outputs, char2idx, tokenize_as_morph=True)
idx_targets = dec_target_processing(outputs, char2idx, tokenize_as_morph=True)
Out [14]:
100%|██████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1383.62it/s]
100%|███████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 803.06it/s]
100%|███████████████████████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 801.91it/s]
In [15]:
data_config = {'char2idx':char2idx,
'idx2char':idx2char,
'vocab_size':vocab_size,
'pad_symbol':PAD,
'std_symbol':STD,
'end_symbol':END,
'unk_symbol':UNK}
In [16]:
DATA_IN_PATH = 'datasets/data_in/'
TRAIN_INPUTS = 'train_inputs.npy'
TRAIN_OUTPUTS = 'train_outputs.npy'
TRAIN_TARGETS = 'train_targets.npy'
DATA_CONFIGS = 'data_configs.json'
np.save(open(DATA_IN_PATH + TRAIN_INPUTS, 'wb'), idx_inputs)
np.save(open(DATA_IN_PATH + TRAIN_OUTPUTS, 'wb'), idx_outputs)
np.save(open(DATA_IN_PATH + TRAIN_TARGETS, 'wb'), idx_targets)
json.dump(data_config, open(DATA_IN_PATH + DATA_CONFIGS, 'w'))
transformer.ipynb
In [17]:
import tensorflow as tf
import numpy as np
import os, json
from keras.callbacks import EarlyStopping, ModelCheckpoint
import matplotlib.pyplot as plt
# from preprocess import *
In [18]:
def plot_graphs(history, string):
plt.plot(history.history[string])
plt.plot(history.history['val_'+string], '')
plt.xlabel("Epochs")
plt.ylabel(string)
plt.legend([string, 'val_'+string])
plt.show()
In [19]:
DATA_IN_PATH = 'datasets/data_in/'
DATA_OUT_PATH = 'datasets/data_out/'
TRAIN_INPUTS = 'train_inputs.npy'
TRAIN_OUTPUTS = 'train_outputs.npy'
TRAIN_TARGETS = 'train_targets.npy'
DATA_CONFIGS = 'data_configs.json'
In [20]:
SEED_NUM = 1234
tf.random.set_seed(SEED_NUM)
In [21]:
index_inputs = np.load(open(DATA_IN_PATH + TRAIN_INPUTS, 'rb'))
index_outputs = np.load(open(DATA_IN_PATH + TRAIN_OUTPUTS , 'rb'))
index_targets = np.load(open(DATA_IN_PATH + TRAIN_TARGETS , 'rb'))
prepro_configs = json.load(open(DATA_IN_PATH + DATA_CONFIGS, 'r'))
In [22]:
model_name = 'transformer'
BATCH_SIZE = 2
MAX_SEQUENCE = 25
EPOCHS = 30
VALID_SPLIT = 0.1
char2idx = prepro_configs['char2idx']
end_index = prepro_configs['end_symbol']
vocab_size = prepro_configs['vocab_size']
kargs = {'model_name': model_name,
'num_layers': 2,
'd_model': 512,
'num_heads': 8,
'dff': 2048,
'input_vocab_size': vocab_size,
'target_vocab_size': vocab_size,
'maximum_position_encoding': MAX_SEQUENCE,
'end_token_idx': char2idx[end_index],
'rate': 0.1
}
패딩 및 포워드 마스킹
In [23]:
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# add extra dimensions to add the padding
# to the attention logits.
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
In [24]:
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
In [25]:
def create_masks(inp, tar):
# Encoder padding mask
enc_padding_mask = create_padding_mask(inp)
# Used in the 2nd attention block in the decoder.
# This padding mask is used to mask the encoder outputs.
dec_padding_mask = create_padding_mask(inp)
# Used in the 1st attention block in the decoder.
# It is used to pad and mask future tokens in the input received by
# the decoder.
look_ahead_mask = create_look_ahead_mask(tf.shape(tar)[1])
dec_target_padding_mask = create_padding_mask(tar)
combined_mask = tf.maximum(dec_target_padding_mask, look_ahead_mask)
return enc_padding_mask, combined_mask, dec_padding_mask
In [26]:
enc_padding_mask, look_ahead_mask, dec_padding_mask = create_masks(index_inputs, index_outputs)
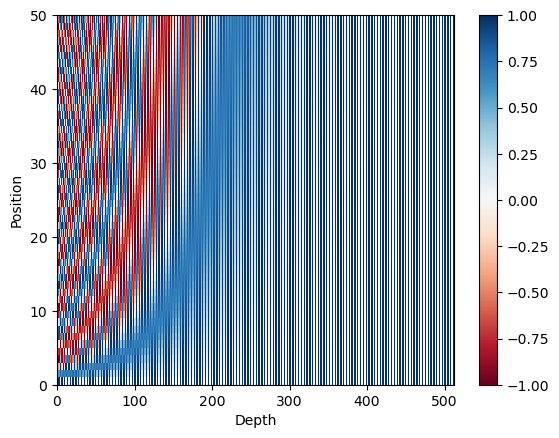
포지셔널 인코딩
In [27]:
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * i//2) / np.float32(d_model))
return pos * angle_rates
In [28]:
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# 짝수번째 sin 적용 ; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# 홀수번째 cos 적용; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
In [29]:
pos_encoding = positional_encoding(50, 512)
print (pos_encoding.shape)
plt.pcolormesh(pos_encoding[0], cmap='RdBu')
plt.xlabel('Depth')
plt.xlim((0, 512))
plt.ylabel('Position')
plt.colorbar()
plt.show()
Out [29]:
(1, 50, 512)
어텐션
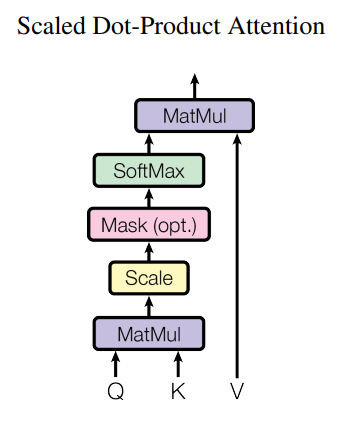
In [30]:
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
멀티헤드 어텐션
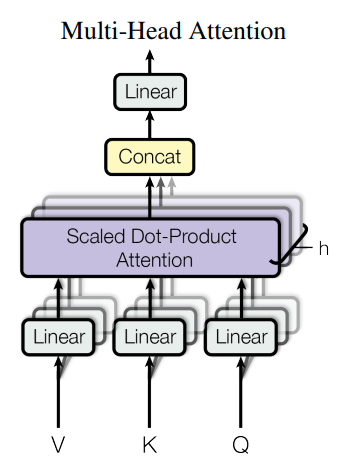
In [31]:
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(MultiHeadAttention, self).__init__()
self.num_heads = kargs['num_heads']
self.d_model = kargs['d_model']
assert self.d_model % self.num_heads == 0
self.depth = self.d_model // self.num_heads
self.wq = tf.keras.layers.Dense(kargs['d_model'])
self.wk = tf.keras.layers.Dense(kargs['d_model'])
self.wv = tf.keras.layers.Dense(kargs['d_model'])
self.dense = tf.keras.layers.Dense(kargs['d_model'])
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
포인트 와이즈 피드포워드 네트워크
In [32]:
def point_wise_feed_forward_network(**kargs):
return tf.keras.Sequential([
tf.keras.layers.Dense(kargs['dff'], activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(kargs['d_model']) # (batch_size, seq_len, d_model)
])
인코더 레이어
In [33]:
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(**kargs)
self.ffn = point_wise_feed_forward_network(**kargs)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(kargs['rate'])
self.dropout2 = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
디코더 레이어
In [34]:
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(**kargs)
self.mha2 = MultiHeadAttention(**kargs)
self.ffn = point_wise_feed_forward_network(**kargs)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(kargs['rate'])
self.dropout2 = tf.keras.layers.Dropout(kargs['rate'])
self.dropout3 = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, enc_output, look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2
인코더
In [35]:
class Encoder(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(Encoder, self).__init__()
self.d_model = kargs['d_model']
self.num_layers = kargs['num_layers']
self.embedding = tf.keras.layers.Embedding(kargs['input_vocab_size'], self.d_model)
self.pos_encoding = positional_encoding(kargs['maximum_position_encoding'],
self.d_model)
self.enc_layers = [EncoderLayer(**kargs)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, mask):
seq_len = tf.shape(x)[1]
# adding embedding and position encoding.
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x)
for i in range(self.num_layers):
x = self.enc_layers[i](x, mask)
return x # (batch_size, input_seq_len, d_model)
디코더
In [36]:
class Decoder(tf.keras.layers.Layer):
def __init__(self, **kargs):
super(Decoder, self).__init__()
self.d_model = kargs['d_model']
self.num_layers = kargs['num_layers']
self.embedding = tf.keras.layers.Embedding(kargs['target_vocab_size'], self.d_model)
self.pos_encoding = positional_encoding(kargs['maximum_position_encoding'], self.d_model)
self.dec_layers = [DecoderLayer(**kargs)
for _ in range(self.num_layers)]
self.dropout = tf.keras.layers.Dropout(kargs['rate'])
def call(self, x, enc_output, look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, look_ahead_mask, padding_mask)
attention_weights['decoder_layer{}_block1'.format(i+1)] = block1
attention_weights['decoder_layer{}_block2'.format(i+1)] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weights
트렌스포머 모델
In [37]:
class Transformer(tf.keras.Model):
def __init__(self, **kargs):
super(Transformer, self).__init__(name=kargs['model_name'])
self.end_token_idx = kargs['end_token_idx']
self.encoder = Encoder(**kargs)
self.decoder = Decoder(**kargs)
self.final_layer = tf.keras.layers.Dense(kargs['target_vocab_size'])
def call(self, x):
inp, tar = x
enc_padding_mask, look_ahead_mask, dec_padding_mask = create_masks(inp, tar)
enc_output = self.encoder(inp, enc_padding_mask) # (batch_size, inp_seq_len, d_model)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, _ = self.decoder(
tar, enc_output, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output
def inference(self, x):
inp = x
tar = tf.expand_dims([STD_INDEX], 0)
enc_padding_mask, look_ahead_mask, dec_padding_mask = create_masks(inp, tar)
enc_output = self.encoder(inp, enc_padding_mask)
predict_tokens = list()
for t in range(0, MAX_SEQUENCE):
dec_output, _ = self.decoder(tar, enc_output, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output)
outputs = tf.argmax(final_output, -1).numpy()
pred_token = outputs[0][-1]
if pred_token == self.end_token_idx:
break
predict_tokens.append(pred_token)
tar = tf.expand_dims([STD_INDEX] + predict_tokens, 0)
_, look_ahead_mask, dec_padding_mask = create_masks(inp, tar)
return predict_tokens
모델 loss 정의
In [38]:
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='accuracy')
def loss(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_mean(loss_)
def accuracy(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
mask = tf.expand_dims(tf.cast(mask, dtype=pred.dtype), axis=-1)
pred *= mask
acc = train_accuracy(real, pred)
return tf.reduce_mean(acc)
In [39]:
model = Transformer(**kargs)
model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss=loss,
metrics=[accuracy])
Callback 선언
In [40]:
# overfitting을 막기 위한 ealrystop 추가
earlystop_callback = EarlyStopping(monitor='val_accuracy', min_delta=0.0001, patience=10)
# min_delta: the threshold that triggers the termination (acc should at least improve 0.0001)
# patience: no improvment epochs (patience = 1, 1번 이상 상승이 없으면 종료)
checkpoint_path = DATA_OUT_PATH + model_name + '/weights.h5'
checkpoint_dir = os.path.dirname(checkpoint_path)
# Create path if exists
if os.path.exists(checkpoint_dir):
print("{} -- Folder already exists \n".format(checkpoint_dir))
else:
os.makedirs(checkpoint_dir, exist_ok=True)
print("{} -- Folder create complete \n".format(checkpoint_dir))
cp_callback = ModelCheckpoint(
checkpoint_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=True)
Out [40]:
datasets/data_out/transformer -- Folder already exists
모델 학습
In [41]:
history = model.fit([index_inputs, index_outputs], index_targets,
batch_size=BATCH_SIZE, epochs=30,#EPOCHS,
validation_split=VALID_SPLIT, callbacks=[earlystop_callback, cp_callback])
Out [41]:
Epoch 1/30
50/50 [==============================] - ETA: 0s - loss: 1.9805 - accuracy: 0.8035
Epoch 1: val_accuracy improved from -inf to 0.79992, saving model to datasets/data_out/transformer\weights.h5
50/50 [==============================] - 19s 238ms/step - loss: 1.9805 - accuracy: 0.8035 - val_loss: 1.9613 - val_accuracy: 0.7999
Epoch 2/30
50/50 [==============================] - ETA: 0s - loss: 1.4727 - accuracy: 0.7941
Epoch 2: val_accuracy improved from 0.79992 to 0.80089, saving model to datasets/data_out/transformer\weights.h5
50/50 [==============================] - 11s 226ms/step - loss: 1.4727 - accuracy: 0.7941 - val_loss: 1.8880 - val_accuracy: 0.8009
...
Epoch 29/30
50/50 [==============================] - ETA: 0s - loss: 0.0193 - accuracy: 0.9277
Epoch 29: val_accuracy improved from 0.92673 to 0.92849, saving model to datasets/data_out/transformer\weights.h5
50/50 [==============================] - 11s 229ms/step - loss: 0.0193 - accuracy: 0.9277 - val_loss: 2.3333 - val_accuracy: 0.9285
Epoch 30/30
50/50 [==============================] - ETA: 0s - loss: 0.0175 - accuracy: 0.9294
Epoch 30: val_accuracy improved from 0.92849 to 0.93013, saving model to datasets/data_out/transformer\weights.h5
50/50 [==============================] - 11s 226ms/step - loss: 0.0175 - accuracy: 0.9294 - val_loss: 2.3645 - val_accuracy: 0.9301
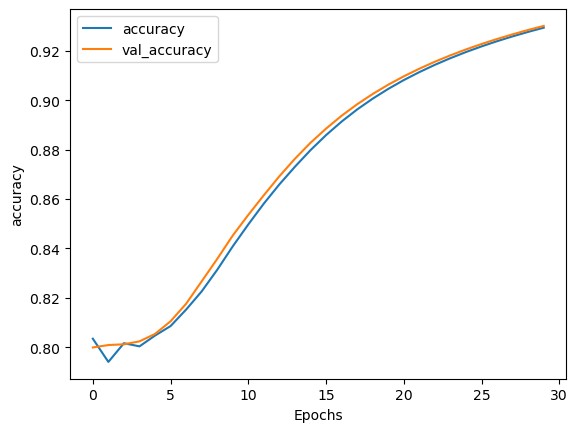
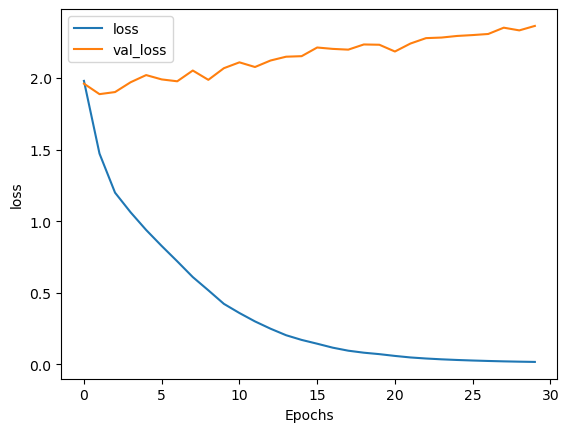
결과 플롯
In [42]:
plot_graphs(history, 'accuracy')
Out [42]:
In [43]:
plot_graphs(history, 'loss')
Out [43]:
베스트 모델 불러오기
In [44]:
DATA_OUT_PATH = 'datasets/data_out/'
SAVE_FILE_NM = 'weights.h5'
model.load_weights(os.path.join(DATA_OUT_PATH, model_name, SAVE_FILE_NM))
모델 결과 출력하기
In [45]:
char2idx = prepro_configs['char2idx']
idx2char = prepro_configs['idx2char']
In [46]:
text = "여자친구 승진 선물로 뭐가 좋을까?"
test_index_inputs, _ = enc_processing([text], char2idx)
outputs = model.inference(test_index_inputs)
print(' '.join([idx2char[str(o)] for o in outputs]))
Out [46]:
공적 인 일 부터 하세요
댓글남기기