
Pandas (1) - 기초
판다스 시작
데이터 집합 불러오기
In [1]:
import pandas as pd
- csv comma seperated value
- tsv tab seperated value
- 섞어 쓰든 상관은 없으니 어떻게 구분되어 있는지는 알아야 함
In [2]:
df = pd.read_csv('data/gapminder.tsv', sep='\t') # 상대경로
In [3]:
type(df)
Out [3]:
pandas.core.frame.DataFrame
- 데이터프레임은 시리즈들의 모음
In [4]:
print(df.head())
Out [4]:
country continent year lifeExp pop gdpPercap
0 Afghanistan Asia 1952 28.801 8425333 779.445314
1 Afghanistan Asia 1957 30.332 9240934 820.853030
2 Afghanistan Asia 1962 31.997 10267083 853.100710
3 Afghanistan Asia 1967 34.020 11537966 836.197138
4 Afghanistan Asia 1972 36.088 13079460 739.981106
In [5]:
df.head(3) # default는 5
Out [5]:
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 | 28.801 | 8425333 | 779.445314 |
| 1 | Afghanistan | Asia | 1957 | 30.332 | 9240934 | 820.853030 |
| 2 | Afghanistan | Asia | 1962 | 31.997 | 10267083 | 853.100710 |
In [6]:
df.tail(3)
Out [6]:
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 1701 | Zimbabwe | Africa | 1997 | 46.809 | 11404948 | 792.449960 |
| 1702 | Zimbabwe | Africa | 2002 | 39.989 | 11926563 | 672.038623 |
| 1703 | Zimbabwe | Africa | 2007 | 43.487 | 12311143 | 469.709298 |
In [7]:
df.sample(3) # default는 1개 랜덤으로 출력
Out [7]:
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 260 | Central African Republic | Africa | 1992 | 49.396 | 3265124 | 747.905525 |
| 1625 | Uruguay | Americas | 1977 | 69.481 | 2873520 | 6504.339663 |
| 1220 | Philippines | Asia | 1992 | 66.458 | 67185766 | 2279.324017 |
In [8]:
# numpy에서 사용한 함수들 대부분 사용 가능
df.shape
Out [8]:
(1704, 6)
In [9]:
df.size
Out [9]:
10224
In [10]:
df.ndim
Out [10]:
2
| Columns | |
|---|---|
| Index | Values |
In [11]:
df.columns
Out [11]:
Index(['country', 'continent', 'year', 'lifeExp', 'pop', 'gdpPercap'], dtype='object')
In [12]:
df.index
Out [12]:
RangeIndex(start=0, stop=1704, step=1)
In [13]:
df.values # ndarray 2차원
Out [13]:
array([['Afghanistan', 'Asia', 1952, 28.801, 8425333, 779.4453145],
['Afghanistan', 'Asia', 1957, 30.332, 9240934, 820.8530296],
['Afghanistan', 'Asia', 1962, 31.997, 10267083, 853.10071],
...,
['Zimbabwe', 'Africa', 1997, 46.809, 11404948, 792.4499603],
['Zimbabwe', 'Africa', 2002, 39.989, 11926563, 672.0386227],
['Zimbabwe', 'Africa', 2007, 43.487, 12311143, 469.7092981]],
dtype=object)
In [14]:
df.dtypes # object는 str
Out [14]:
country object
continent object
year int64
lifeExp float64
pop int64
gdpPercap float64
dtype: object
In [15]:
df.info() # 메서드
Out [15]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1704 entries, 0 to 1703
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 country 1704 non-null object
1 continent 1704 non-null object
2 year 1704 non-null int64
3 lifeExp 1704 non-null float64
4 pop 1704 non-null int64
5 gdpPercap 1704 non-null float64
dtypes: float64(2), int64(2), object(2)
memory usage: 80.0+ KB
데이터 추출하기
In [16]:
df['country']
Out [16]:
0 Afghanistan
1 Afghanistan
2 Afghanistan
3 Afghanistan
4 Afghanistan
...
1699 Zimbabwe
1700 Zimbabwe
1701 Zimbabwe
1702 Zimbabwe
1703 Zimbabwe
Name: country, Length: 1704, dtype: object
In [17]:
type(df['country'])
Out [17]:
pandas.core.series.Series
In [18]:
# Series에서의 head
df['country'].head(3)
Out [18]:
0 Afghanistan
1 Afghanistan
2 Afghanistan
Name: country, dtype: object
In [19]:
df['country'].tail(3)
Out [19]:
1701 Zimbabwe
1702 Zimbabwe
1703 Zimbabwe
Name: country, dtype: object
In [20]:
df['country'].sample(3)
Out [20]:
1306 Sao Tome and Principe
779 Italy
934 Malawi
Name: country, dtype: object
In [21]:
df[['country', 'continent']] # 하나의 parameter를 넣어야 하기에 list로 넣음
Out [21]:
| country | continent | |
|---|---|---|
| 0 | Afghanistan | Asia |
| 1 | Afghanistan | Asia |
| 2 | Afghanistan | Asia |
| 3 | Afghanistan | Asia |
| 4 | Afghanistan | Asia |
| ... | ... | ... |
| 1699 | Zimbabwe | Africa |
| 1700 | Zimbabwe | Africa |
| 1701 | Zimbabwe | Africa |
| 1702 | Zimbabwe | Africa |
| 1703 | Zimbabwe | Africa |
1704 rows × 2 columns
In [22]:
type(df[['country', 'continent']])
Out [22]:
pandas.core.frame.DataFrame
- loc 인덱스명을 기준으로 추출
- iloc: 인덱스 번호를 기준으로 추출
In [23]:
df.head(3)
Out [23]:
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 | 28.801 | 8425333 | 779.445314 |
| 1 | Afghanistan | Asia | 1957 | 30.332 | 9240934 | 820.853030 |
| 2 | Afghanistan | Asia | 1962 | 31.997 | 10267083 | 853.100710 |
In [24]:
df.loc[2]
Out [24]:
country Afghanistan
continent Asia
year 1962
lifeExp 31.997
pop 10267083
gdpPercap 853.10071
Name: 2, dtype: object
In [25]:
df.loc[2:5]
Out [25]:
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 2 | Afghanistan | Asia | 1962 | 31.997 | 10267083 | 853.100710 |
| 3 | Afghanistan | Asia | 1967 | 34.020 | 11537966 | 836.197138 |
| 4 | Afghanistan | Asia | 1972 | 36.088 | 13079460 | 739.981106 |
| 5 | Afghanistan | Asia | 1977 | 38.438 | 14880372 | 786.113360 |
In [26]:
df.loc[[1, 5, 10]]
Out [26]:
| country | continent | year | lifeExp | pop | gdpPercap | |
|---|---|---|---|---|---|---|
| 1 | Afghanistan | Asia | 1957 | 30.332 | 9240934 | 820.853030 |
| 5 | Afghanistan | Asia | 1977 | 38.438 | 14880372 | 786.113360 |
| 10 | Afghanistan | Asia | 2002 | 42.129 | 25268405 | 726.734055 |
In [27]:
df.loc[1, 'country']
Out [27]:
'Afghanistan'
In [28]:
df.loc[1:6, 'country':'year']
Out [28]:
| country | continent | year | |
|---|---|---|---|
| 1 | Afghanistan | Asia | 1957 |
| 2 | Afghanistan | Asia | 1962 |
| 3 | Afghanistan | Asia | 1967 |
| 4 | Afghanistan | Asia | 1972 |
| 5 | Afghanistan | Asia | 1977 |
| 6 | Afghanistan | Asia | 1982 |
In [29]:
df.loc[[1, 6], ['country', 'year']]
Out [29]:
| country | year | |
|---|---|---|
| 1 | Afghanistan | 1957 |
| 6 | Afghanistan | 1982 |
In [30]:
df.iloc[0]
Out [30]:
country Afghanistan
continent Asia
year 1952
lifeExp 28.801
pop 8425333
gdpPercap 779.445314
Name: 0, dtype: object
In [31]:
df.iloc[0, 0]
Out [31]:
'Afghanistan'
In [32]:
df.iloc[0:1, 0:3]
Out [32]:
| country | continent | year | |
|---|---|---|---|
| 0 | Afghanistan | Asia | 1952 |
In [33]:
df.iloc[-1]
Out [33]:
country Zimbabwe
continent Africa
year 2007
lifeExp 43.487
pop 12311143
gdpPercap 469.709298
Name: 1703, dtype: object
In [34]:
df.iloc[1:4, 0:2]
Out [34]:
| country | continent | |
|---|---|---|
| 1 | Afghanistan | Asia |
| 2 | Afghanistan | Asia |
| 3 | Afghanistan | Asia |
In [35]:
df.loc[1:4, 'country':'year']
Out [35]:
| country | continent | year | |
|---|---|---|---|
| 1 | Afghanistan | Asia | 1957 |
| 2 | Afghanistan | Asia | 1962 |
| 3 | Afghanistan | Asia | 1967 |
| 4 | Afghanistan | Asia | 1972 |
기초적인 통계 계산하기
In [36]:
df.mean(numeric_only=True) # default axis=0
Out [36]:
year 1.979500e+03
lifeExp 5.947444e+01
pop 2.960121e+07
gdpPercap 7.215327e+03
dtype: float64
In [37]:
df.mean(numeric_only=True, axis=0) # numpy의 axis와 같다!
Out [37]:
year 1.979500e+03
lifeExp 5.947444e+01
pop 2.960121e+07
gdpPercap 7.215327e+03
dtype: float64
In [38]:
df.mean(numeric_only=True, axis=1)
Out [38]:
0 2.107023e+06
1 2.310936e+06
2 2.567483e+06
3 2.885201e+06
4 3.270552e+06
...
1699 2.304793e+06
1700 2.676771e+06
1701 2.851946e+06
1702 2.982319e+06
1703 3.078416e+06
Length: 1704, dtype: float64
In [39]:
# 그룹으로 묶어서 연산
# 연도별 기대수명
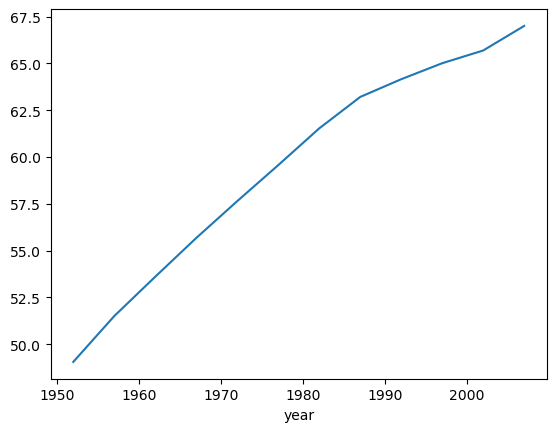
df.groupby('year')['lifeExp'].mean()
Out [39]:
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
1977 59.570157
1982 61.533197
1987 63.212613
1992 64.160338
1997 65.014676
2002 65.694923
2007 67.007423
Name: lifeExp, dtype: float64
In [40]:
# 연도별, 대륙별 기대수명
df.groupby(['year', 'continent'])['lifeExp'].mean()
Out [40]:
year continent
1952 Africa 39.135500
Americas 53.279840
Asia 46.314394
Europe 64.408500
Oceania 69.255000
1957 Africa 41.266346
Americas 55.960280
Asia 49.318544
Europe 66.703067
Oceania 70.295000
1962 Africa 43.319442
Americas 58.398760
Asia 51.563223
Europe 68.539233
Oceania 71.085000
1967 Africa 45.334538
Americas 60.410920
Asia 54.663640
Europe 69.737600
Oceania 71.310000
1972 Africa 47.450942
Americas 62.394920
Asia 57.319269
Europe 70.775033
Oceania 71.910000
1977 Africa 49.580423
Americas 64.391560
Asia 59.610556
Europe 71.937767
Oceania 72.855000
1982 Africa 51.592865
Americas 66.228840
Asia 62.617939
Europe 72.806400
Oceania 74.290000
1987 Africa 53.344788
Americas 68.090720
Asia 64.851182
Europe 73.642167
Oceania 75.320000
1992 Africa 53.629577
Americas 69.568360
Asia 66.537212
Europe 74.440100
Oceania 76.945000
1997 Africa 53.598269
Americas 71.150480
Asia 68.020515
Europe 75.505167
Oceania 78.190000
2002 Africa 53.325231
Americas 72.422040
Asia 69.233879
Europe 76.700600
Oceania 79.740000
2007 Africa 54.806038
Americas 73.608120
Asia 70.728485
Europe 77.648600
Oceania 80.719500
Name: lifeExp, dtype: float64
In [41]:
# 연도별, 대륙별 기대수명
df.groupby(['year', 'continent'])[['lifeExp', 'gdpPercap']].mean()
Out [41]:
| lifeExp | gdpPercap | ||
|---|---|---|---|
| year | continent | ||
| 1952 | Africa | 39.135500 | 1252.572466 |
| Americas | 53.279840 | 4079.062552 | |
| Asia | 46.314394 | 5195.484004 | |
| Europe | 64.408500 | 5661.057435 | |
| Oceania | 69.255000 | 10298.085650 | |
| 1957 | Africa | 41.266346 | 1385.236062 |
| Americas | 55.960280 | 4616.043733 | |
| Asia | 49.318544 | 5787.732940 | |
| Europe | 66.703067 | 6963.012816 | |
| Oceania | 70.295000 | 11598.522455 | |
| 1962 | Africa | 43.319442 | 1598.078825 |
| Americas | 58.398760 | 4901.541870 | |
| Asia | 51.563223 | 5729.369625 | |
| Europe | 68.539233 | 8365.486814 | |
| Oceania | 71.085000 | 12696.452430 | |
| 1967 | Africa | 45.334538 | 2050.363801 |
| Americas | 60.410920 | 5668.253496 | |
| Asia | 54.663640 | 5971.173374 | |
| Europe | 69.737600 | 10143.823757 | |
| Oceania | 71.310000 | 14495.021790 | |
| 1972 | Africa | 47.450942 | 2339.615674 |
| Americas | 62.394920 | 6491.334139 | |
| Asia | 57.319269 | 8187.468699 | |
| Europe | 70.775033 | 12479.575246 | |
| Oceania | 71.910000 | 16417.333380 | |
| 1977 | Africa | 49.580423 | 2585.938508 |
| Americas | 64.391560 | 7352.007126 | |
| Asia | 59.610556 | 7791.314020 | |
| Europe | 71.937767 | 14283.979110 | |
| Oceania | 72.855000 | 17283.957605 | |
| 1982 | Africa | 51.592865 | 2481.592960 |
| Americas | 66.228840 | 7506.737088 | |
| Asia | 62.617939 | 7434.135157 | |
| Europe | 72.806400 | 15617.896551 | |
| Oceania | 74.290000 | 18554.709840 | |
| 1987 | Africa | 53.344788 | 2282.668991 |
| Americas | 68.090720 | 7793.400261 | |
| Asia | 64.851182 | 7608.226508 | |
| Europe | 73.642167 | 17214.310727 | |
| Oceania | 75.320000 | 20448.040160 | |
| 1992 | Africa | 53.629577 | 2281.810333 |
| Americas | 69.568360 | 8044.934406 | |
| Asia | 66.537212 | 8639.690248 | |
| Europe | 74.440100 | 17061.568084 | |
| Oceania | 76.945000 | 20894.045885 | |
| 1997 | Africa | 53.598269 | 2378.759555 |
| Americas | 71.150480 | 8889.300863 | |
| Asia | 68.020515 | 9834.093295 | |
| Europe | 75.505167 | 19076.781802 | |
| Oceania | 78.190000 | 24024.175170 | |
| 2002 | Africa | 53.325231 | 2599.385159 |
| Americas | 72.422040 | 9287.677107 | |
| Asia | 69.233879 | 10174.090397 | |
| Europe | 76.700600 | 21711.732422 | |
| Oceania | 79.740000 | 26938.778040 | |
| 2007 | Africa | 54.806038 | 3089.032605 |
| Americas | 73.608120 | 11003.031625 | |
| Asia | 70.728485 | 12473.026870 | |
| Europe | 77.648600 | 25054.481636 | |
| Oceania | 80.719500 | 29810.188275 |
In [42]:
# 고유값 갯수 확인
df.nunique()
Out [42]:
country 142
continent 5
year 12
lifeExp 1626
pop 1704
gdpPercap 1704
dtype: int64
In [43]:
# 그룹화한 데이터 갯수 세기
# 대륙별 나라가 몇개나 있는가?
df.groupby('continent')['country'].nunique()
Out [43]:
continent
Africa 52
Americas 25
Asia 33
Europe 30
Oceania 2
Name: country, dtype: int64
그래프 그리기
In [44]:
# 데이터 요약 작업 # 후에 배울 seaborn에서는 알아서 요약 작업을 해줌
data = df.groupby('year')['lifeExp'].mean()
data
Out [44]:
year
1952 49.057620
1957 51.507401
1962 53.609249
1967 55.678290
1972 57.647386
1977 59.570157
1982 61.533197
1987 63.212613
1992 64.160338
1997 65.014676
2002 65.694923
2007 67.007423
Name: lifeExp, dtype: float64
In [45]:
# 간단한 그래프
data.plot()
Out [45]:
<AxesSubplot:xlabel='year'>
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기