
Pandas (8) - 실제 데이터 연습
데이터 불러오기
In [1]:
import pandas as pd
- 한글 불러오기
utf-8 안되면 cp949 아니면 euc-kr
In [2]:
first_df = pd.read_csv('전국_평균_분양가격(2013년_9월부터_2015년_8월까지).csv', encoding='cp949')
first_df.head(3)
Out [2]:
| 지역 | 2013년12월 | 2014년1월 | 2014년2월 | 2014년3월 | 2014년4월 | 2014년5월 | 2014년6월 | 2014년7월 | 2014년8월 | ... | 2014년11월 | 2014년12월 | 2015년1월 | 2015년2월 | 2015년3월 | 2015년4월 | 2015년5월 | 2015년6월 | 2015년7월 | 2015년8월 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 18189 | 17925 | 17925 | 18016 | 18098 | 19446 | 18867 | 18742 | 19274 | ... | 20242 | 20269 | 20670 | 20670 | 19415 | 18842 | 18367 | 18374 | 18152 | 18443 |
| 1 | 부산 | 8111 | 8111 | 9078 | 8965 | 9402 | 9501 | 9453 | 9457 | 9411 | ... | 9208 | 9208 | 9204 | 9235 | 9279 | 9327 | 9345 | 9515 | 9559 | 9581 |
| 2 | 대구 | 8080 | 8080 | 8077 | 8101 | 8267 | 8274 | 8360 | 8360 | 8370 | ... | 8439 | 8253 | 8327 | 8416 | 8441 | 8446 | 8568 | 8542 | 8542 | 8795 |
3 rows × 22 columns
In [3]:
first_df.info()
Out [3]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 17 entries, 0 to 16
Data columns (total 22 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역 17 non-null object
1 2013년12월 17 non-null int64
2 2014년1월 17 non-null int64
3 2014년2월 17 non-null int64
4 2014년3월 17 non-null int64
5 2014년4월 17 non-null int64
6 2014년5월 17 non-null int64
7 2014년6월 17 non-null int64
8 2014년7월 17 non-null int64
9 2014년8월 17 non-null int64
10 2014년9월 17 non-null int64
11 2014년10월 17 non-null int64
12 2014년11월 17 non-null int64
13 2014년12월 17 non-null int64
14 2015년1월 17 non-null int64
15 2015년2월 17 non-null int64
16 2015년3월 17 non-null int64
17 2015년4월 17 non-null int64
18 2015년5월 17 non-null int64
19 2015년6월 17 non-null int64
20 2015년7월 17 non-null int64
21 2015년8월 17 non-null int64
dtypes: int64(21), object(1)
memory usage: 3.0+ KB
In [4]:
last_df = pd.read_csv('주택도시보증공사_전국_평균_분양가격(2019년_12월).csv', encoding='cp949')
last_df.head(3)
Out [4]:
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | |
|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 |
In [5]:
last_df.info()
Out [5]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 규모구분 4335 non-null object
2 연도 4335 non-null int64
3 월 4335 non-null int64
4 분양가격(㎡) 4058 non-null object
dtypes: int64(2), object(3)
memory usage: 169.5+ KB
In [6]:
# 누락값 확인
last_df.isna().sum()
Out [6]:
지역명 0
규모구분 0
연도 0
월 0
분양가격(㎡) 277
dtype: int64
데이터 가공
두 데이터프레임의 분양가격 단위를 통일
In [7]:
from numpy import nan
In [8]:
type(nan)
Out [8]:
float
nan은 float이므로 to_numeric할 수 있으나 str “ “은 불가능하다.
to_numeric의 errors옵션을 coerce로 주면 error발생 시 nan으로 처리한다는 것을 이용할 수 있다.
In [9]:
last_df['분양가격'] = pd.to_numeric(last_df['분양가격(㎡)'], errors='coerce') # df의 astype으로도 변경가능하나 coerce를 지원하지 않음
In [10]:
last_df.info()
Out [10]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 규모구분 4335 non-null object
2 연도 4335 non-null int64
3 월 4335 non-null int64
4 분양가격(㎡) 4058 non-null object
5 분양가격 3957 non-null float64
dtypes: float64(1), int64(2), object(3)
memory usage: 203.3+ KB
평당 분양가격으로 변경
In [11]:
last_df['평당분양가격'] = last_df['분양가격'] * 3.3
In [12]:
last_df.head(3)
Out [12]:
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | 분양가격 | 평당분양가격 | |
|---|---|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 | 5841.0 | 19275.3 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 | 5652.0 | 18651.6 |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 | 5882.0 | 19410.6 |
In [13]:
last_df['평당분양가격'].describe()
Out [13]:
count 3957.000000
mean 10685.824488
std 4172.222780
min 6164.400000
25% 8055.300000
50% 9484.200000
75% 11751.300000
max 42002.400000
Name: 평당분양가격, dtype: float64
규모구분을 쓰기 편하게 가공
In [14]:
last_df.규모구분.unique()
Out [14]:
array(['전체', '전용면적 60㎡이하', '전용면적 60㎡초과 85㎡이하', '전용면적 85㎡초과 102㎡이하',
'전용면적 102㎡초과'], dtype=object)
In [15]:
# '전용면적' 제거
last_df['전용면적'] = last_df.규모구분.str.replace('전용면적', '')
last_df.head(3)
Out [15]:
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 | 5652.0 | 18651.6 | 60㎡이하 |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 | 5882.0 | 19410.6 | 60㎡초과 85㎡이하 |
In [16]:
last_df['전용면적'] = last_df.전용면적.str.replace('초과', '~')
last_df.head(3)
Out [16]:
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 | 5652.0 | 18651.6 | 60㎡이하 |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 | 5882.0 | 19410.6 | 60㎡~ 85㎡이하 |
In [17]:
last_df['전용면적'] = last_df.전용면적.str.replace('이하', '')
last_df.head(3)
Out [17]:
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 | 5652.0 | 18651.6 | 60㎡ |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 | 5882.0 | 19410.6 | 60㎡~ 85㎡ |
In [18]:
# 문제가 될 수 있는 공백제거
last_df['전용면적'] = last_df.전용면적.str.replace(' ', '').str.strip()
last_df.head(3)
Out [18]:
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 | 5652.0 | 18651.6 | 60㎡ |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 | 5882.0 | 19410.6 | 60㎡~85㎡ |
In [19]:
last_df.전용면적.unique()
Out [19]:
array(['전체', '60㎡', '60㎡~85㎡', '85㎡~102㎡', '102㎡~'], dtype=object)
필요없는 데이터 제거
In [20]:
last_df.columns
Out [20]:
Index(['지역명', '규모구분', '연도', '월', '분양가격(㎡)', '분양가격', '평당분양가격', '전용면적'], dtype='object')
In [21]:
last_df.drop(columns=['규모구분', '분양가격(㎡)'], inplace=True)
last_df.head(3)
Out [21]:
| 지역명 | 연도 | 월 | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|
| 0 | 서울 | 2015 | 10 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 2015 | 10 | 5652.0 | 18651.6 | 60㎡ |
| 2 | 서울 | 2015 | 10 | 5882.0 | 19410.6 | 60㎡~85㎡ |
In [22]:
last_df.columns
Out [22]:
Index(['지역명', '연도', '월', '분양가격', '평당분양가격', '전용면적'], dtype='object')
데이터 분석
지역별 평당 분양가격의 평균 확인
In [23]:
last_df.groupby(['지역명'])['평당분양가격'].mean()
Out [23]:
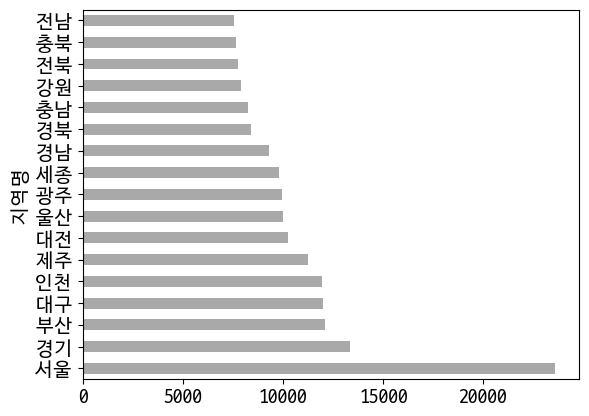
지역명
강원 7890.750000
경기 13356.895200
경남 9268.778138
경북 8376.536515
광주 9951.535821
대구 11980.895455
대전 10253.333333
부산 12087.121200
서울 23599.976400
세종 9796.516456
울산 10014.902013
인천 11915.320732
전남 7565.316532
전북 7724.235484
제주 11241.276712
충남 8233.651883
충북 7634.655600
Name: 평당분양가격, dtype: float64
전용면적별 평당 분양가격 확인
In [24]:
last_df.groupby(['전용면적'])['평당분양가격'].mean()
Out [24]:
전용면적
102㎡~ 11517.705634
60㎡ 10375.137421
60㎡~85㎡ 10271.040071
85㎡~102㎡ 11097.599573
전체 10276.086207
Name: 평당분양가격, dtype: float64
전용면적별, 지역별 평당 분양가격 확인
In [25]:
data = last_df.groupby(['전용면적', '지역명'])['평당분양가격'].mean().reset_index()
In [26]:
data.round(-1) # 1원단위 반올림
Out [26]:
| 전용면적 | 지역명 | 평당분양가격 | |
|---|---|---|---|
| 0 | 102㎡~ | 강원 | 8310.0 |
| 1 | 102㎡~ | 경기 | 14770.0 |
| 2 | 102㎡~ | 경남 | 10360.0 |
| 3 | 102㎡~ | 경북 | 9160.0 |
| 4 | 102㎡~ | 광주 | 11040.0 |
| ... | ... | ... | ... |
| 80 | 전체 | 전남 | 7280.0 |
| 81 | 전체 | 전북 | 7290.0 |
| 82 | 전체 | 제주 | 10780.0 |
| 83 | 전체 | 충남 | 7820.0 |
| 84 | 전체 | 충북 | 7220.0 |
85 rows × 3 columns
In [27]:
# 같은 데이터를 얻는 다른 방법
pd.pivot_table(last_df, index=['전용면적', '지역명'], values=['평당분양가격']).reset_index().round(-1) # aggfunc의 default가 mean이다
Out [27]:
| 전용면적 | 지역명 | 평당분양가격 | |
|---|---|---|---|
| 0 | 102㎡~ | 강원 | 8310.0 |
| 1 | 102㎡~ | 경기 | 14770.0 |
| 2 | 102㎡~ | 경남 | 10360.0 |
| 3 | 102㎡~ | 경북 | 9160.0 |
| 4 | 102㎡~ | 광주 | 11040.0 |
| ... | ... | ... | ... |
| 80 | 전체 | 전남 | 7280.0 |
| 81 | 전체 | 전북 | 7290.0 |
| 82 | 전체 | 제주 | 10780.0 |
| 83 | 전체 | 충남 | 7820.0 |
| 84 | 전체 | 충북 | 7220.0 |
85 rows × 3 columns
데이터 시각화
지역별 평당분양가격
In [28]:
data = last_df.groupby(['지역명'])['평당분양가격'].mean()
In [29]:
data.sort_values(ascending=False).plot(kind='barh', color='darkgray')
Out [29]:
<AxesSubplot:ylabel='지역명'>
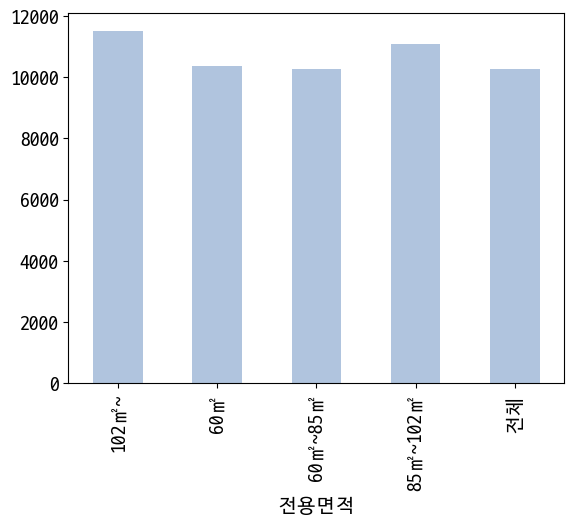
전용면적별 평당분양가격
In [30]:
data = last_df.groupby(['전용면적'])['평당분양가격'].mean().sort_index()
data
Out [30]:
전용면적
102㎡~ 11517.705634
60㎡ 10375.137421
60㎡~85㎡ 10271.040071
85㎡~102㎡ 11097.599573
전체 10276.086207
Name: 평당분양가격, dtype: float64
In [31]:
data.plot(kind='bar', color='lightsteelblue')
Out [31]:
<AxesSubplot:xlabel='전용면적'>
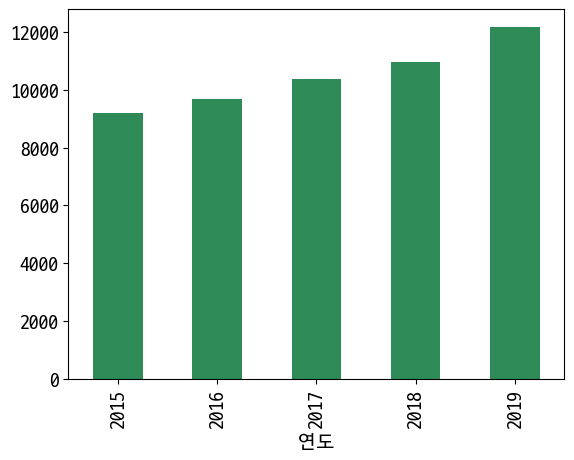
연도별 평당분양가격
In [32]:
data = last_df.groupby(['연도'])['평당분양가격'].mean()
data
Out [32]:
연도
2015 9202.735802
2016 9683.025000
2017 10360.487653
2018 10978.938411
2019 12188.293092
Name: 평당분양가격, dtype: float64
In [33]:
data.plot(kind='bar', color='seagreen')
Out [33]:
<AxesSubplot:xlabel='연도'>
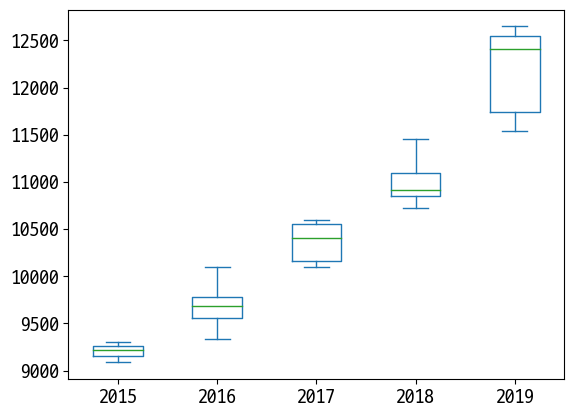
In [34]:
# 연도별 월별
data = last_df.pivot_table(index='월', columns='연도', values='평당분양가격')
data
Out [34]:
| 연도 | 2015 | 2016 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|
| 월 | |||||
| 1 | NaN | 9334.029630 | 10095.132143 | 10719.148000 | 11535.540789 |
| 2 | NaN | 9361.440000 | 10110.885714 | 10766.668000 | 11574.793421 |
| 3 | NaN | 9423.276923 | 10107.428571 | 10905.488000 | 11610.094737 |
| 4 | NaN | 9601.993902 | 10217.232143 | 10920.728571 | 11777.876000 |
| 5 | NaN | 9602.396341 | 10358.819277 | 11087.485714 | 11976.394737 |
| 6 | NaN | 9676.042683 | 10431.618072 | 10921.928571 | 12401.884000 |
| 7 | NaN | 9700.551220 | 10549.536585 | 10868.376316 | 12424.852000 |
| 8 | NaN | 9719.023171 | 10564.869512 | 10811.147368 | 12523.896000 |
| 9 | NaN | 9737.656098 | 10583.601266 | 10915.257692 | 12527.571429 |
| 10 | 9086.488889 | 9924.225882 | 10399.845570 | 11133.269231 | 12619.073077 |
| 11 | 9218.122222 | 9972.757143 | NaN | 11224.762025 | 12647.785714 |
| 12 | 9303.596296 | 10092.264286 | 10597.620000 | 11453.822368 | 12622.847368 |
In [35]:
data.plot(kind='box') # pandas로 box로 하려면 연도별로 안에 data들이 들어 있어야 한다.
Out [35]:
<AxesSubplot:>
seaborn으로 박스플롯 작성
In [36]:
import seaborn as sns
In [37]:
sns.boxplot(data=last_df, x='연도', y='평당분양가격') # pandas 와는 다르게 알아서 해줌
Out [37]:
<AxesSubplot:xlabel='연도', ylabel='평당분양가격'>
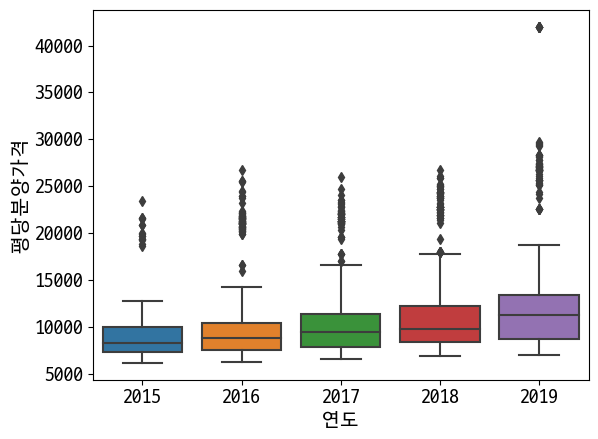
In [38]:
# 연도별 전용면적별 평당분양가격
sns.boxplot(data=last_df, x='연도', y='평당분양가격', hue='전용면적') # pandas 와는 다르게 알아서 해줌
Out [38]:
<AxesSubplot:xlabel='연도', ylabel='평당분양가격'>
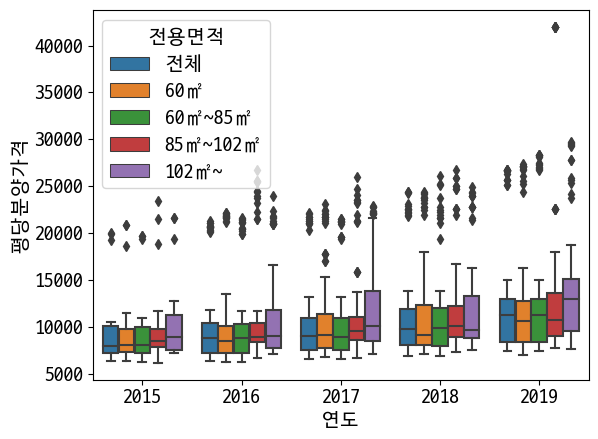
In [39]:
# 바이올린플롯(violinplot) : 사각형인 박스플롯과 다르게 크기를 알 수 있음
sns.violinplot(data=last_df, x='연도', y='평당분양가격')
Out [39]:
<AxesSubplot:xlabel='연도', ylabel='평당분양가격'>
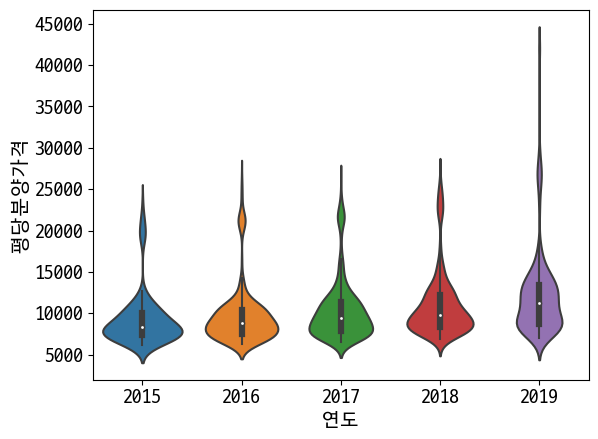
seaborn gallery 에서 그래프 형태를 확인할 수 있다.
두 데이터베이스의 연결
In [40]:
first_df.head(3)
Out [40]:
| 지역 | 2013년12월 | 2014년1월 | 2014년2월 | 2014년3월 | 2014년4월 | 2014년5월 | 2014년6월 | 2014년7월 | 2014년8월 | ... | 2014년11월 | 2014년12월 | 2015년1월 | 2015년2월 | 2015년3월 | 2015년4월 | 2015년5월 | 2015년6월 | 2015년7월 | 2015년8월 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 18189 | 17925 | 17925 | 18016 | 18098 | 19446 | 18867 | 18742 | 19274 | ... | 20242 | 20269 | 20670 | 20670 | 19415 | 18842 | 18367 | 18374 | 18152 | 18443 |
| 1 | 부산 | 8111 | 8111 | 9078 | 8965 | 9402 | 9501 | 9453 | 9457 | 9411 | ... | 9208 | 9208 | 9204 | 9235 | 9279 | 9327 | 9345 | 9515 | 9559 | 9581 |
| 2 | 대구 | 8080 | 8080 | 8077 | 8101 | 8267 | 8274 | 8360 | 8360 | 8370 | ... | 8439 | 8253 | 8327 | 8416 | 8441 | 8446 | 8568 | 8542 | 8542 | 8795 |
3 rows × 22 columns
In [41]:
first_df_melt = first_df.melt(id_vars='지역', var_name='기간', value_name='평당분양가격')
first_df_melt.head(3)
Out [41]:
| 지역 | 기간 | 평당분양가격 | |
|---|---|---|---|
| 0 | 서울 | 2013년12월 | 18189 |
| 1 | 부산 | 2013년12월 | 8111 |
| 2 | 대구 | 2013년12월 | 8080 |
In [42]:
last_df.columns
Out [42]:
Index(['지역명', '연도', '월', '분양가격', '평당분양가격', '전용면적'], dtype='object')
In [43]:
last_df.info()
Out [43]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 연도 4335 non-null int64
2 월 4335 non-null int64
3 분양가격 3957 non-null float64
4 평당분양가격 3957 non-null float64
5 전용면적 4335 non-null object
dtypes: float64(2), int64(2), object(2)
memory usage: 203.3+ KB
In [44]:
first_df_melt.columns # 지역을 지역명으로 변경 # 기간을 연도와 월로 분리 # 연도와 월 int형으로
Out [44]:
Index(['지역', '기간', '평당분양가격'], dtype='object')
In [45]:
# 기간을 연도와 월로 분리
first_df_melt['연도'] = first_df_melt['기간'].str.split('년').str.get(0).astype('int')
# astype으로 가능은 하지만 공백이 있다면 불가능(에러 처리가 없음)
In [46]:
first_df_melt['월'] = first_df_melt['기간'].str.split('년').str.get(1).str.replace('월', '').astype('int')
In [47]:
first_df_melt.head(3)
Out [47]:
| 지역 | 기간 | 평당분양가격 | 연도 | 월 | |
|---|---|---|---|---|---|
| 0 | 서울 | 2013년12월 | 18189 | 2013 | 12 |
| 1 | 부산 | 2013년12월 | 8111 | 2013 | 12 |
| 2 | 대구 | 2013년12월 | 8080 | 2013 | 12 |
In [48]:
# 지역을 지역명으로 변경하고
first_df_melt.columns = ['지역명', '기간', '평당분양가격', '연도', '월']
In [49]:
first_df_melt.columns
Out [49]:
Index(['지역명', '기간', '평당분양가격', '연도', '월'], dtype='object')
In [50]:
# 사용할 column 설정
cols = ['지역명', '연도', '월', '평당분양가격']
In [51]:
# last_df의 전용면적 중 전체만 사용
last_df[last_df['전용면적'] == '전체']
Out [51]:
| 지역명 | 연도 | 월 | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|
| 0 | 서울 | 2015 | 10 | 5841.0 | 19275.3 | 전체 |
| 5 | 인천 | 2015 | 10 | 3163.0 | 10437.9 | 전체 |
| 10 | 경기 | 2015 | 10 | 3138.0 | 10355.4 | 전체 |
| 15 | 부산 | 2015 | 10 | 3112.0 | 10269.6 | 전체 |
| 20 | 대구 | 2015 | 10 | 2682.0 | 8850.6 | 전체 |
| ... | ... | ... | ... | ... | ... | ... |
| 4310 | 전북 | 2019 | 12 | 2468.0 | 8144.4 | 전체 |
| 4315 | 전남 | 2019 | 12 | 2452.0 | 8091.6 | 전체 |
| 4320 | 경북 | 2019 | 12 | 2914.0 | 9616.2 | 전체 |
| 4325 | 경남 | 2019 | 12 | 3063.0 | 10107.9 | 전체 |
| 4330 | 제주 | 2019 | 12 | 3882.0 | 12810.6 | 전체 |
867 rows × 6 columns
In [52]:
# 사용할 데이터만 정제
data_last = last_df.loc[last_df['전용면적'] == '전체', cols]
data_last.head(3)
Out [52]:
| 지역명 | 연도 | 월 | 평당분양가격 | |
|---|---|---|---|---|
| 0 | 서울 | 2015 | 10 | 19275.3 |
| 5 | 인천 | 2015 | 10 | 10437.9 |
| 10 | 경기 | 2015 | 10 | 10355.4 |
In [53]:
data_first = first_df_melt[cols]
data_first.head(3)
Out [53]:
| 지역명 | 연도 | 월 | 평당분양가격 | |
|---|---|---|---|---|
| 0 | 서울 | 2013 | 12 | 18189 |
| 1 | 부산 | 2013 | 12 | 8111 |
| 2 | 대구 | 2013 | 12 | 8080 |
In [54]:
result = pd.concat([data_first, data_last])
result
Out [54]:
| 지역명 | 연도 | 월 | 평당분양가격 | |
|---|---|---|---|---|
| 0 | 서울 | 2013 | 12 | 18189.0 |
| 1 | 부산 | 2013 | 12 | 8111.0 |
| 2 | 대구 | 2013 | 12 | 8080.0 |
| 3 | 인천 | 2013 | 12 | 10204.0 |
| 4 | 광주 | 2013 | 12 | 6098.0 |
| ... | ... | ... | ... | ... |
| 4310 | 전북 | 2019 | 12 | 8144.4 |
| 4315 | 전남 | 2019 | 12 | 8091.6 |
| 4320 | 경북 | 2019 | 12 | 9616.2 |
| 4325 | 경남 | 2019 | 12 | 10107.9 |
| 4330 | 제주 | 2019 | 12 | 12810.6 |
1224 rows × 4 columns
Reference
- 이 포스트는 SeSAC 인공지능 자연어처리, 컴퓨터비전 기술을 활용한 응용 SW 개발자 양성 과정 - 심선조 강사님의 강의를 정리한 내용입니다.
댓글남기기