s="Life is too short."# Life를 This pencil로 바꿔보자.
s.replace("Life","This pencil")print(s)# TMI)공백 없애기
s.replace(" ","")print(s)
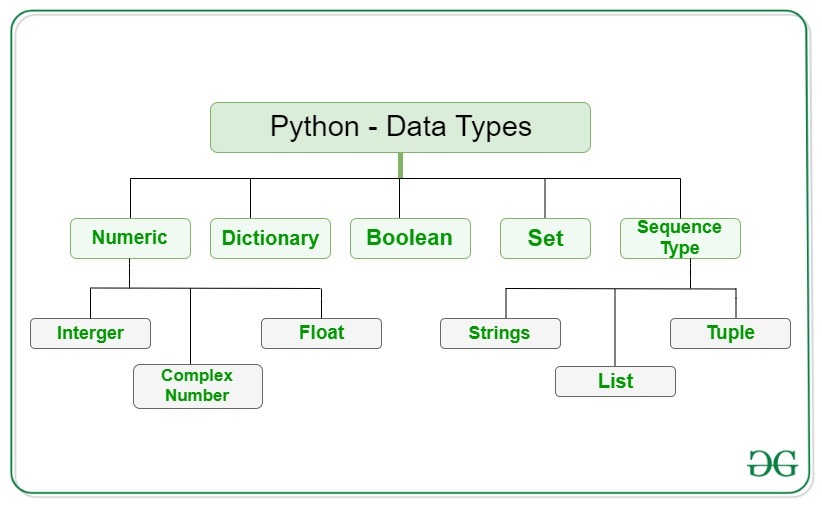
3.3. 연속형 데이터 (Sequential Data Types)
연속형 데이터란, 하나의 변수가 하나의 데이터를 가지고 있던 숫자형 데이터와 달리, 여러개의 데이터를 하나의 변수에 가지고 있는 데이터 타입이다.
연속형 데이터 타입에는 리스트(List), 튜플(Tuple), 문자열(String)이 있다. (문자열을 문자들의 나열로 인식하기 때문에, 연속형 데이터이다.)
연속형 데이터의 크기 제한은 없다. 하지만, 사용하는 컴퓨터의 가용 메모리 용량을 인지하며 사용해야 한다.
각 연속형 데이터 타입마다 특징이 다르다. 그 특징을 파악하여 용도에 맞는 데이터 타입을 사용하는 것이 중요하다.
사전(dictionary) 타입은 associative array라고 불리며, 흔히 알고있는 Hash table 구조이다.
3.3.1 리스트(List)
가장 많이 사용되는 연속형 데이터 타입이자, 굉장히 유연한 구조를 가지고 있어 대부분의 데이터를 편하게 다룰 수 있다.
파이썬에서 [와 ]를 이용하여 표현한다. e.g. [1, 2, 3]
리스트의 원소는 쉼표로 구분되며, 리스트의 원소는 아무 데이터 타입이나 가능하다. 리스트조차 가능하다.
리스트를 이용하면 파이썬에서 다루는 대부분의 데이터는 아무 무리없이 다룰 수 있다. 하지만 수정이 자유롭기 때문에 수정을 하면 안되는 경우에는 사용하면 안된다.
리스트를 만드는 방법
1
2
L=[1,2,3]L
1
2
L1=[]type(L1)
1
2
L2=list()# 빈 리스트를 만드는 같은 방법
type(L2)
1
2
L3=[1,"Hi",3.14,[1,2,3]]# 리스트에는 다양한 타입의 원소를 다 포함할 수 있다. 심지어 리스트도.
L3
1
2
3
L4=[[1,2],[3,4]]# 2x2 행렬 표현처럼 사용할 수 있다. 이를 2차원 리스트라고 한다.
L4# 실제로는 2개의 리스트를 원소로 가지는 리스트이다.
Indexing (***)
연속형 데이터들은 하나의 변수에 여러가지 데이터를 가지기 때문에 여러 데이터를 접근하는 방법이 필요하다.
이를 위해 indexing이라는 기법이 있다. 말그대로 index를 통해 접근(access)하는 방법이다.
리스트의 index는 맨 앞부터 0으로 시작하며, 1씩 증가하는 정수 index를 사용한다.
파이썬에서는 음수 index도 제공하는데, 이는 뒤쪽부터 접근할 수 있는 방법이다.
e.g. [1, 2, 3]이면 뒤에서 첫번째(맨 마지막)원소는 index가 -1이고, 뒤에서 두번째 원소는 index가 -2이다.
index를 통해 접근하는 방법은 해당 변수이름에 []를 사용하며, []안에 index를 넣어서 접근할 수 있다.
e.g L = [1, 2, 3]이면 L[0]은 1이고, L[2]는 L[-1]이며 3이다.
1
L=[1,2,3,4,5]
1
2
# L의 첫번째 원소
L[0]# index 0
1
2
# L의 5번째 원소
L[4]
1
L[8]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-70-87bd48964891> in <module>
1 # L에 없는 index는?----> 2 L[8]
IndexError: list index out of range
1
2
3
# L의 마지막 원소
L[-1]L[-3]# L[len(L)-3] == L[5-3] == L[2] -> 3번째 원소 == 3
1
L[0]+L[1]
1
2
L2=[1,[2,3],5]L2
1
L2[1][0]
Slicing (**)
슬라이싱은 리스트에서 뿐만 아니라, 리스트와 비슷한 구조인 numpy array와 pandas series, dataframe에서도 많이 이용되니 꼭 알아두어야 한다.
슬라이싱은 리스트의 일부분만 잘라낸다는 의미이다. (말그대로 슬라이싱)
리스트의 일부만 사용하고 싶을 때 쓰는 기법이며, indexing을 범위로 하는 느낌이다.
리스트의 index와 :를 사용하여 슬라이싱을 할 수 있다.
e.g. L = [1, 2, 3, 4] L[0:2]는 [1, 2]이다.
# 시작 index를 생략하면, 자동으로 index는 0이 된다. (맨 처음)
L[:-1]# L[:-1] == L[:len(L)-1] == L[:5-1] == L[:4]
1
2
# 끝 index를 생략하면, 자동으로 index는(리스트의 길이)가 된다. (맨 마지막)
L[-2:]# L[-2:len(L)]
문자열도 연속형 데이터 타입이기 때문에, indexing과 slicing이 다 된다.
리스트 연산하기
리스트 더하기
1
2
3
L=[1,2,3]L2=[4,5]L+L2
리스트 곱하기
1
L*3
리스트 수정하기
1
2
L[2]=1L
1
2
L2[0]=7L2
리스트 관련 함수
리스트에 원소 추가하기 append() (***)
1
2
3
4
5
6
7
L=[]L.append(3)L.append(2)L.append(1)L
리스트 원소 정렬하기 sort()
1
2
3
4
L=[4,3,16]L.sort()# ascending order
#L.sort(reverse=True) # descending order
L
리스트 뒤집기(정렬 X) reverse()
1
2
3
#L.reverse() # reverse()와 같은 결과를 내는 신박한 방법도 있다.
L=[1,2,3,4,5,6]L[::-1]
리스트에서 원소 제거하기 pop()
1
2
3
4
L1=L.pop()print(L1)L2=L.pop()print(L2)
3.3.2 튜플(Tuple)
tuple은 list과 거의 같다.
indexing, slicing 모두 동일하게 사용 가능하다.
원소들도 자유롭게 사용 가능하다.
거의 같은데, 다른 점이 딱 2가지 있다.
1) 리스트는 []를 사용하고, 튜플은 ()을 사용한다.2) 리스트는 생성 후에 변경이 가능하고(mutable) 튜플은 생성 후에 변경이 불가능하다.(immutable)
Mutable : 생성된 이후에 변경(assignment)이 자유롭게 가능한 data type.
e.g. List, dict, set
immutable : 생성된 이후에 변경이 불가능한 data type
e.g. int, float, string, tuple, frozenset
성능적인 이슈 -> 변경되지는 않는 그 자체로 장점이 생김.
프로그래밍적인 이슈 -> 데이터 수정 자체를 하지 않는 경우 실수를 방지할 수 있다.
1
2
t=(1,2)t
1
2
t1=()t1,type(t1)# 사실 이 때까지 이렇게 2항에 대해서 출력한 모든 결과는 tuple이었다.
1
2
t2=('a','b',('a','b'))t2
1
t2[:2]
1
t[0]
1
t[-1]
1
t[0]=3
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-108-3618893200c3> in <module>
----> 1 t[0] = 3
TypeError: 'tuple' object does not support item assignment
1
2
3
4
# 튜플의 연산
t=(1,2)t2=(3,4)t+t2
1
t2*3
1
len(t*3)
3.3.3 집합(Set)
집합 자료형은 정말 말그대로 수학에서 배우는 집합 그 자체이다.
공집합을 생성할 때는 반드시 set()으로 생성해야 한다. {}로 생성하면 빈 사전이 생성된다.
e.g. {1, 2, 3} : 집합, {‘a’:1, ‘b’:2} : 사전
집합의 연산자인 교집합, 합집합, 차집합을 모두 지원한다.
집합의 특징이 2가지 있는데, 이 특징이 리스트와의 차이점이라 사용한다. 첫번째 특징이 집합 자료형을 사용하는 주된 이유이다.
1) 집합은 원소의 중복을 허용하지 않는다. 즉, 원소의 종류를 나타내기 좋다.
2) 집합은 원소의 순서가 존재하지 않는다. 즉, 원소의 index가 없다.
1
2
s={1,2,3}s,type(s),type(s)
1
s[1]
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-117-119c3881ee56> in <module>
----> 1 s[1]
TypeError: 'set' object is not subscriptable
D['a']=4# assignment를 할 때, key값이 없다면 key-value pair를 추가. 있다면, value를 수정.
D# 리스트의 경우.
# L = [1, 2, 3]
# L[0] = 4
# L
1
2
D["b"]# key값이 이미 존재하는 경우에는 key값을 통한 indexing이 되며, key값이 존재하지 않을 때는 assignment를 사용하여 원소를 추가한다.
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-1-2e181af46200> in <module>
----> 1 D['b']
NameError: name 'D' is not defined
1
2
D2={'a':1,'a':2,'b':3}# key 중복문제
D2
TIP 사전을 만들 때 key는 중복이 있으면 절대 안된다.
사전에서 key가 될 수 있는 data type은 immutable이어야 한다.

댓글남기기