
음성 처리 - TTS 논문
TTS/STT
Text to Sound / Sound to Text
- Tacotron
seq2seq 구조를 이용하여 text를 학습하여 mel spectogram을 생성, 이를 sound로 변환하는 방법이다.
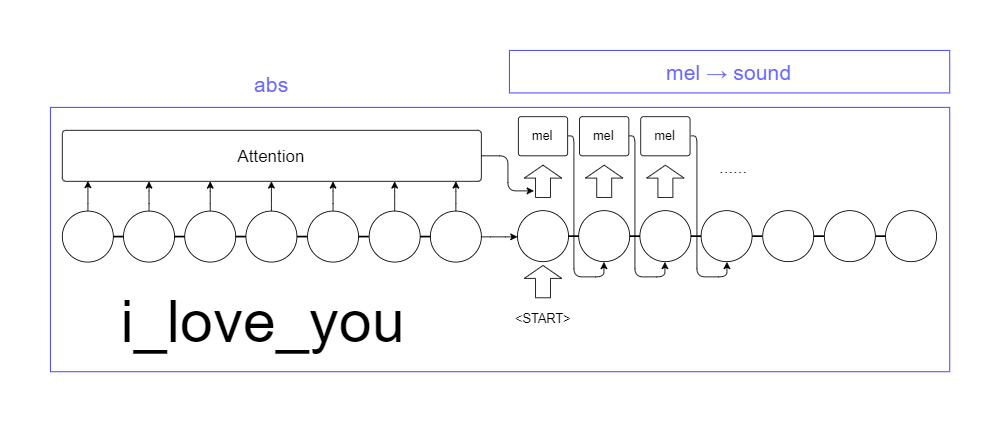
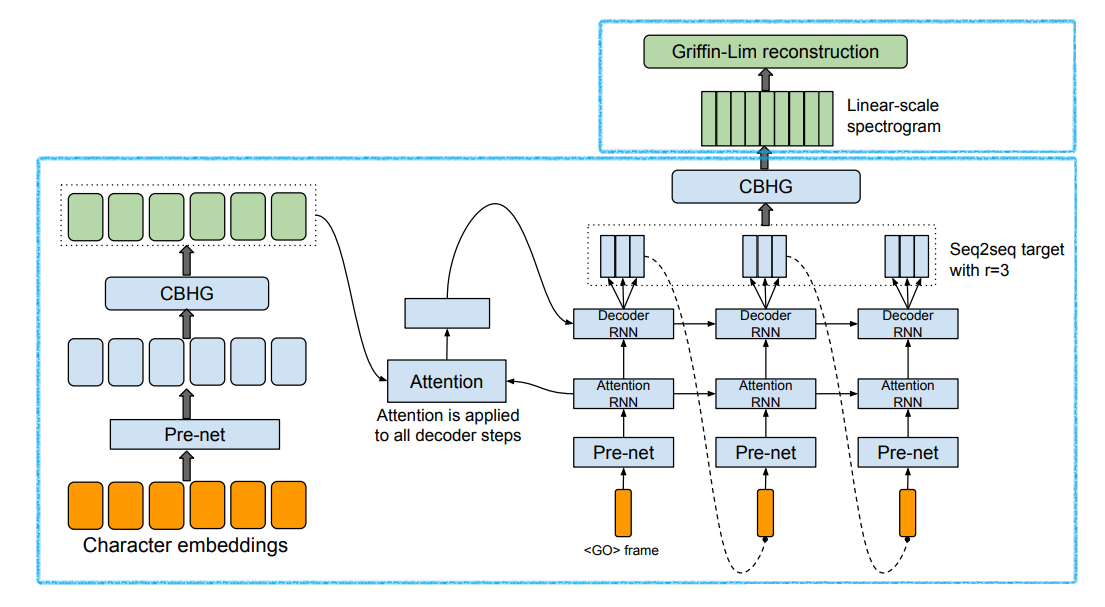
- Tacotron2
Tacotron2에서는 생성한 mel spectrogram을 WaveNet에 넣는 과정을 추가했다.
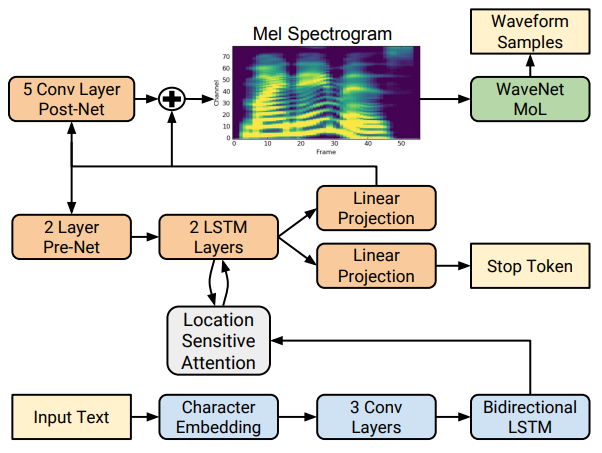
하지만 convolution을 어떻게 하든 절대값(abs)을 취해 날아간 위상 정보는 생성이 불가능하다!
- MelGAN
사라진 위상정보를 이미지 생성 방법인 GAN을 이용하여 새롭게 생성할 수 있다.
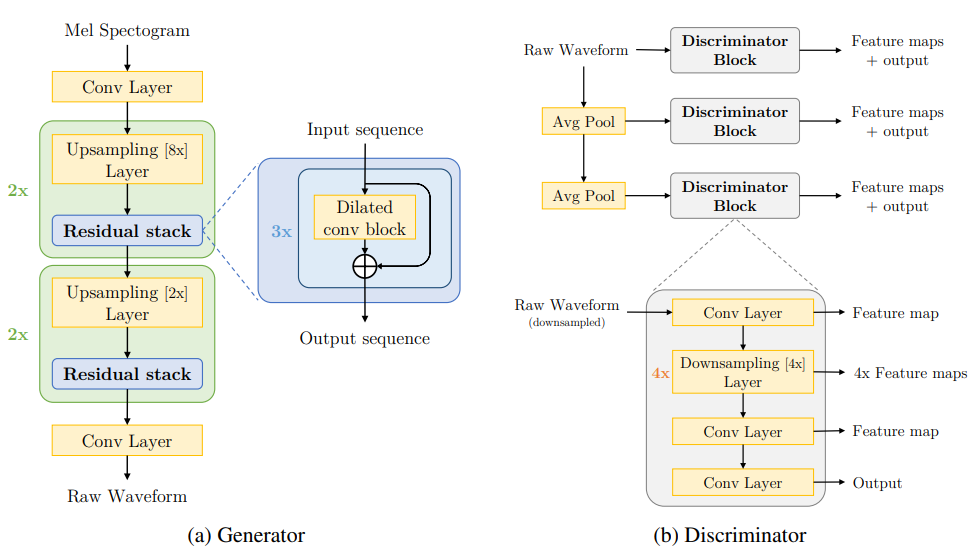
Reference
-
Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, Quoc Le, Yannis Agiomyrgiannakis, Rob Clark and Rif A. Saurous. TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS. arXiv:1703.10135v2 [cs.CL] 6 Apr 2017.
-
Jonathan Shen1, Ruoming Pang, Ron J. Weiss, Mike Schuster, Navdeep Jaitly, Zongheng Yang, Zhifeng Chen, Yu Zhang, Yuxuan Wang, RJ Skerry-Ryan, Rif A. Saurous, Yannis Agiomyrgiannakis and Yonghui Wu. NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS. arXiv:1712.05884v2 [cs.CL] 16 Feb 2018.
-
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior Koray and Kavukcuoglu. WAVENET: A GENERATIVE MODEL FOR RAW AUDIO. arXiv:1609.03499v2 [cs.SD] 19 Sep 2016.
-
Kundan Kumar, Rithesh Kumar, Thibault de Boissiere, Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandre de Brebisson, Yoshua Bengio and Aaron Courville. MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis. arXiv:1910.06711v3 [eess.AS] 9 Dec 2019.
댓글남기기