
음성 처리 - 기초적인 음성합성과 음성복원
Sound Tools
Audacity
유용한 사운드 편집 툴
https://www.audacityteam.org/
음성 합성
In [1]:
import numpy as np
import matplotlib.pyplot as plt
import IPython.display as ipd
import soundfile
import librosa.display
In [2]:
sound_ah, sr = soundfile.read('edit/ah.wav')
ipd.Audio(sound_ah, rate=sr)
Out [2]:
In [3]:
sound_ee, sr = soundfile.read('edit/ee.wav')
ipd.Audio(sound_ee, rate=sr)
Out [3]:
In [4]:
sound_woo, sr = soundfile.read('edit/woo.wav')
ipd.Audio(sound_woo, rate=sr)
Out [4]:
In [5]:
sound_eh, sr = soundfile.read('edit/eh.wav')
ipd.Audio(sound_eh, rate=sr)
Out [5]:
In [6]:
sound_oh, sr = soundfile.read('edit/oh.wav')
ipd.Audio(sound_oh, rate=sr)
Out [6]:
In [7]:
plt.figure(figsize=(14, 8))
tmp = len(sound_ah)//4
plt.subplot(511)
plt.plot(range(tmp), sound_ah[:tmp])
plt.subplot(512)
plt.plot(range(tmp), sound_ee[:tmp])
plt.subplot(513)
plt.plot(range(tmp), sound_woo[:tmp])
plt.subplot(514)
plt.plot(range(tmp), sound_eh[:tmp])
plt.subplot(515)
plt.plot(range(tmp), sound_oh[:tmp])
plt.show()
Out [7]:
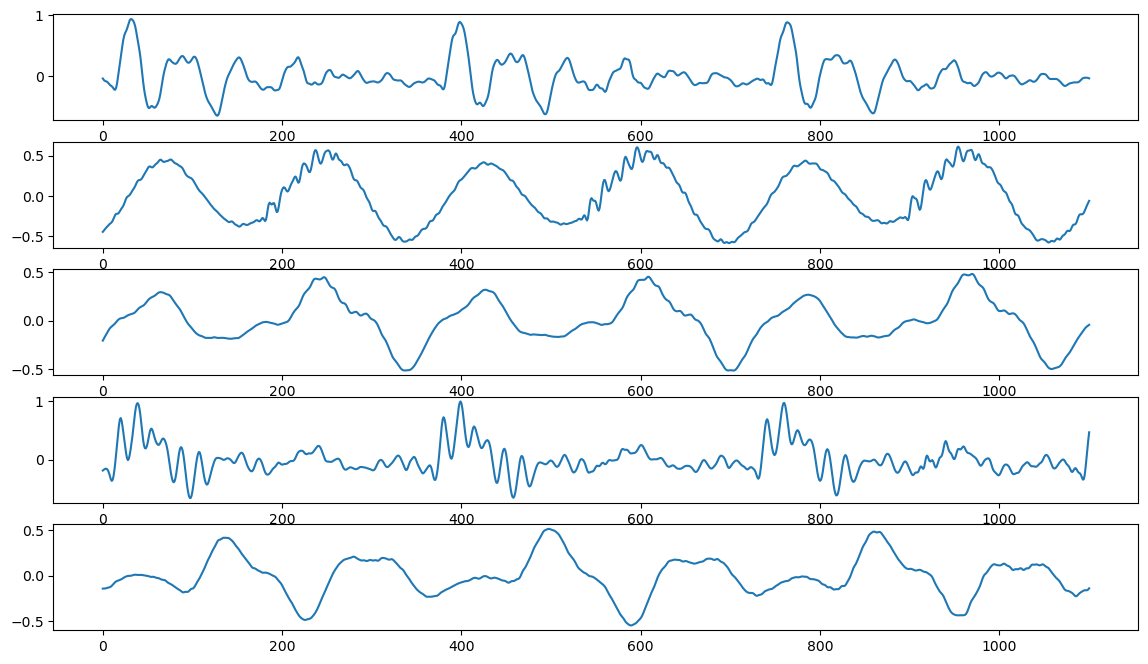
주파수 분석
In [8]:
X_ah = np.fft.fft(sound_ah)
mag_ah = np.abs(X_ah)
f_ah = np.linspace(0, sr, len(mag_ah))
f_left_ah = f_ah[:len(mag_ah)//20]
spectrum_X_ah = mag_ah[:len(mag_ah)//20]
plt.stem(f_left_ah, spectrum_X_ah, 'o-')
plt.xlabel('frequency')
plt.ylabel('magnitude')
plt.title('spectrum of <ah>')
plt.show()
Out [8]:
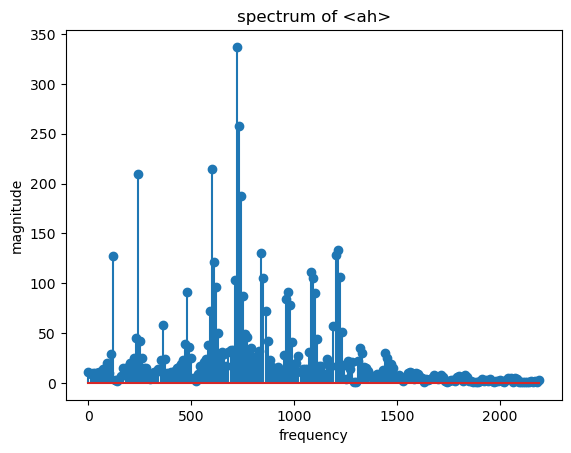
In [9]:
def draw_spectrum(sound):
X = np.fft.fft(sound)
mag = np.abs(X)
f = np.linspace(0, sr, len(mag))
f_left = f[:len(mag)//20]
spectrum_X = mag[:len(mag)//20]
plt.stem(f_left, spectrum_X, 'o-')
In [10]:
aiueo = [sound_ah, sound_ee, sound_woo, sound_eh, sound_oh]
aiueo_str = ['ah', 'ee', 'woo', 'eh', 'oh']
plt.figure(figsize=(14, 4), layout='tight')
for idx, sound in enumerate(aiueo):
num = round(len(aiueo)/3)*100 + 3*10 + (idx+1)
plt.subplot(num)
draw_spectrum(sound)
plt.xlabel('frequency')
plt.ylabel('magnitude')
plt.title(f'spectrum of <{aiueo_str[idx]}>')
plt.show()
Out [10]:
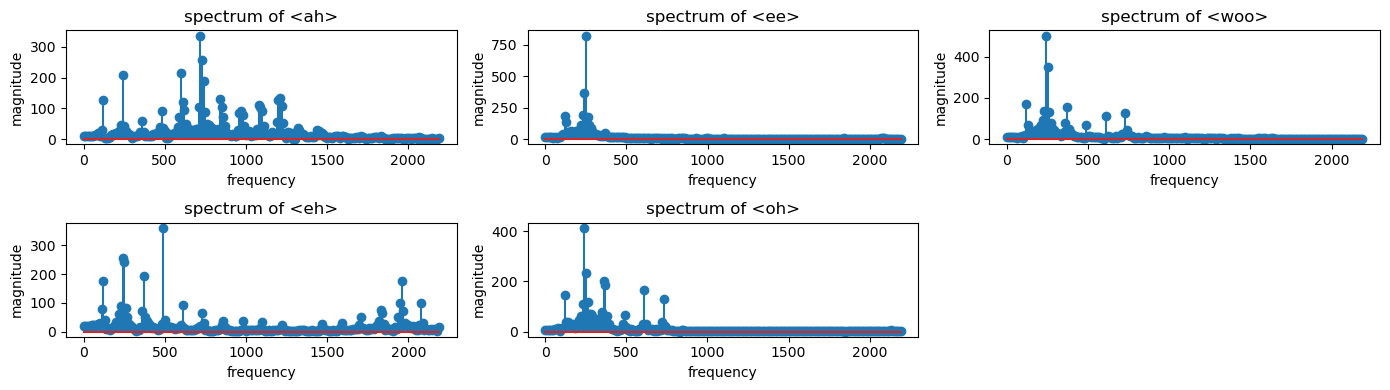
melspectrogram
In [11]:
D = abs(librosa.stft(sound_ah))
mel_spec = librosa.feature.melspectrogram(S=D, n_mels=128) # 적절한 구분으로 구간을 나눔
mel_db = librosa.amplitude_to_db(mel_spec, ref=np.max)
librosa.display.specshow(mel_db, sr=sr, x_axis='time', y_axis='mel')
plt.title('mel freq power spectrogram of <ah>')
plt.colorbar(format='%+2.0f dB')
plt.show()
Out [11]:
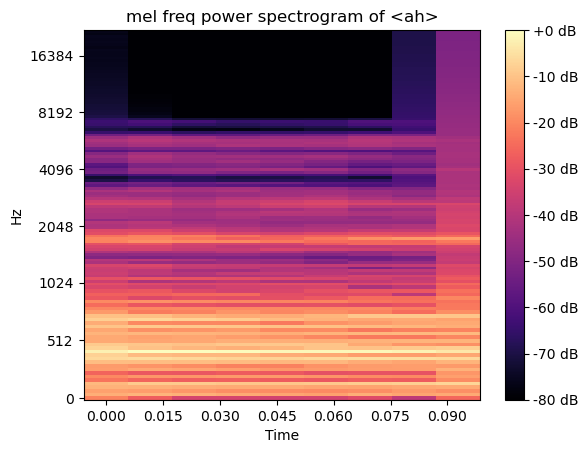
In [12]:
def melspectrogram(sound):
D = abs(librosa.stft(sound))
mel_spec = librosa.feature.melspectrogram(S=D, n_mels=128)
mel_db = librosa.amplitude_to_db(mel_spec, ref=np.max)
librosa.display.specshow(mel_db, sr=sr, x_axis='time', y_axis='mel')
In [13]:
aiueo = [sound_ah, sound_ee, sound_woo, sound_eh, sound_oh]
aiueo_str = ['ah', 'ee', 'woo', 'eh', 'oh']
plt.figure(figsize=(14, 6), layout='tight')
for idx, sound in enumerate(aiueo):
num = round(len(aiueo)/3)*100 + 3*10 + (idx+1)
plt.subplot(num)
melspectrogram(sound)
plt.title(f'mel freq of <{aiueo_str[idx]}>')
plt.colorbar(format='%+2.0f dB')
plt.show()
Out [13]:
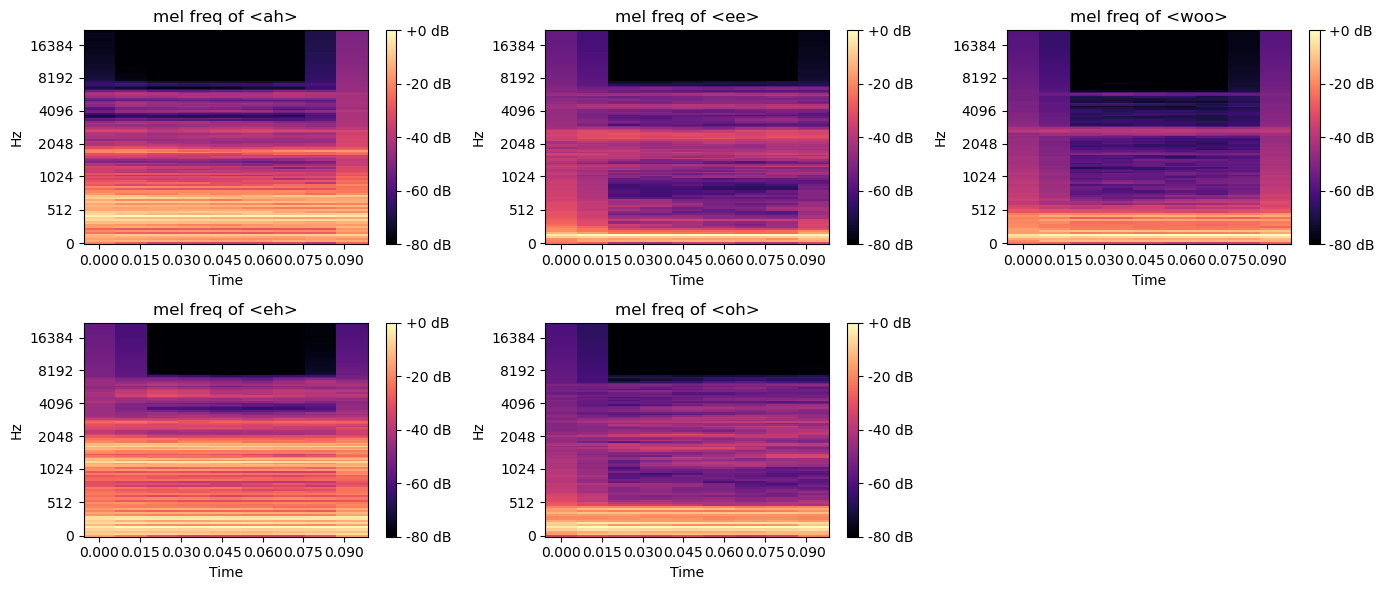
‘아이’ 합성
- 아아, 이이
In [14]:
sound_ah_200ms = np.append(sound_ah, sound_ah)
ipd.Audio(sound_ah_200ms, rate=sr)
Out [14]:
In [15]:
sound_ee_200ms = np.append(sound_ee, sound_ee)
ipd.Audio(sound_ee_200ms, rate=sr)
Out [15]:
- 아아이이
In [16]:
sound_ai_400ms = np.append(sound_ah_200ms, sound_ee_200ms)
ipd.Audio(sound_ai_400ms, rate=sr)
Out [16]:
네이버 사전 발음
In [17]:
sound_ah_by_nav_dict, sr = soundfile.read('dict/edit/ah.wav')
sound_ee_by_nav_dict, sr = soundfile.read('dict/edit/ee.wav')
In [18]:
sound_ah_200ms_by_nav_dict = np.append(sound_ah_by_nav_dict, sound_ah_by_nav_dict)
ipd.Audio(sound_ah_200ms_by_nav_dict, rate=sr)
Out [18]:
In [19]:
sound_ee_200ms_by_nav_dict = np.append(sound_ee_by_nav_dict, sound_ee_by_nav_dict)
ipd.Audio(sound_ee_200ms_by_nav_dict, rate=sr)
Out [19]:
In [20]:
sound_ai_400ms_by_nav_dict = np.append(sound_ah_200ms_by_nav_dict, sound_ee_200ms_by_nav_dict)
ipd.Audio(sound_ai_400ms_by_nav_dict, rate=sr)
Out [20]:
In [21]:
sound_ai_400ms_by_nav_dict, sr = soundfile.read('dict/edit/i.wav')
ipd.Audio(sound_ai_400ms_by_nav_dict, rate=sr)
Out [21]:
In [22]:
aiueo = [sound_ai_400ms, sound_ai_400ms_by_nav_dict]
aiueo_str = ['sound_ai_400ms', 'sound_ai_400ms_by_nav_dict']
plt.figure(figsize=(14, 4), layout='tight')
for idx, sound in enumerate(aiueo):
num = round(len(aiueo)/2)*100 + 2*10 + (idx+1)
plt.subplot(num)
melspectrogram(sound)
plt.title(f'mel freq of <{aiueo_str[idx]}>')
plt.colorbar(format='%+2.0f dB')
plt.show()
Out [22]:
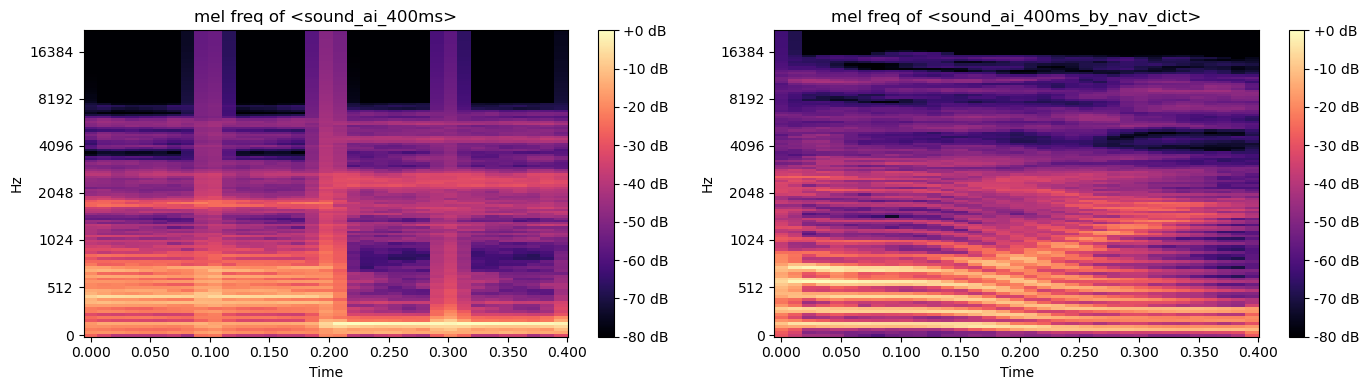
‘러브’ 합성
디코더의 작업을 수작업으로 해보기
럽: ㄹ(80ms) + 어(140ms) + ㅂ(80ms) # fs 44100, 100ms:4410개
In [23]:
sound_L, sr = soundfile.read('dict/edit/l.wav')
sound_어, sr = soundfile.read('dict/edit/eh.wav')
sound_v, sr = soundfile.read('dict/edit/v.wav')
In [24]:
ipd.Audio(sound_L, rate=sr)
Out [24]:
In [25]:
ipd.Audio(sound_어, rate=sr)
Out [25]:
In [26]:
ipd.Audio(sound_v, rate=sr)
Out [26]:
In [27]:
len(sound_L), len(sound_어), len(sound_v)
Out [27]:
(4412, 4397, 4423)
In [28]:
4412*0.8/4410
Out [28]:
0.8003628117913834
In [29]:
sound_L_2 = np.append(sound_L, sound_L)
sound_L_150ms = sound_L_2[:int(4410*0.8)]
In [30]:
4410*1.4/4397
Out [30]:
1.4041391858085057
In [31]:
sound_어_2 = np.append(sound_어, sound_어)
sound_어_100ms = sound_어_2[:int(4410*1.4)]
In [32]:
4410*0.8/4407
Out [32]:
0.8005445881552076
In [33]:
sound_v_2 = np.append(sound_v, sound_v)
sound_v_150ms = sound_v_2[:int(4410*0.8)]
In [34]:
syn_럽 = np.append(np.append(sound_L_150ms, sound_어_100ms), sound_v_150ms)
In [35]:
ipd.Audio(syn_럽, rate=sr)
Out [35]:
In [36]:
sound_love, sr = soundfile.read('dict/edit/love.wav')
ipd.Audio(sound_love, rate=sr)
Out [36]:
In [37]:
aiueo = [sound_love, syn_럽]
aiueo_str = ['sound_love', 'syn_love']
plt.figure(figsize=(14, 4), layout='tight')
for idx, sound in enumerate(aiueo):
num = round(len(aiueo)/2)*100 + 2*10 + (idx+1)
plt.subplot(num)
melspectrogram(sound)
plt.title(f'mel freq of <{aiueo_str[idx]}>')
plt.colorbar(format='%+2.0f dB')
plt.show()
Out [37]:
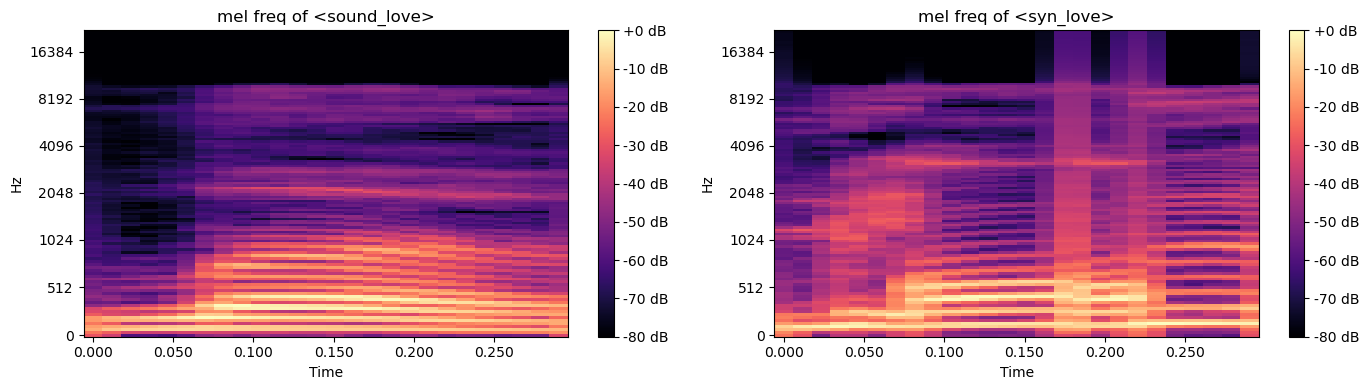
음성 복원
In [38]:
sound_iloveyou, sr = soundfile.read('dict/iloveyou.mp3')
ipd.Audio(sound_iloveyou, rate=sr)
Out [38]:
In [39]:
D = abs(librosa.stft(sound_iloveyou))
mel_spec = librosa.feature.melspectrogram(S=D, n_mels=10)
In [40]:
restored_iloveyou = librosa.feature.inverse.mel_to_audio(mel_spec)
In [41]:
len(sound_iloveyou), len(restored_iloveyou)
Out [41]:
(20284, 19968)
In [42]:
soundfile.write('sounds/restored_iloveyou.wav', restored_iloveyou, 44100, format='WAV')
In [43]:
ipd.Audio(restored_iloveyou, rate=sr)
Out [43]:
위상이 깨져서 나오는 효과
- 허수와 실수의 계산
In [44]:
num1 = 3 + 4j
num2 = 5 + 6j
num3 = num1 + num2
num3
Out [44]:
(8+10j)
In [45]:
num1_real = 3
num1_image = 4
num2_real = 5
num2_image = 6
num3_real = num1_real + num2_real
num3_image = num1_image + num2_image
print(f'실수부:{num3_real}, 허수부:{num3_image}')
Out [45]:
실수부:8, 허수부:10
In [46]:
num1 = abs(3 + 4j)
num2 = abs(5 + 6j)
num3 = num1 + num2
num3
Out [46]:
12.810249675906654
In [47]:
abs(8+10j)
Out [47]:
12.806248474865697
수치상 별 차이가 없지만 소리에서 큰 차이가 있다!
In [48]:
X_analog = np.linspace(0, 5*2*np.pi, 1000)
y_analog = np.sin(X_analog) * 255.0/2.0
plt.figure(figsize=(10, 2))
plt.plot(X_analog, y_analog)
plt.grid()
plt.show()
Out [48]:
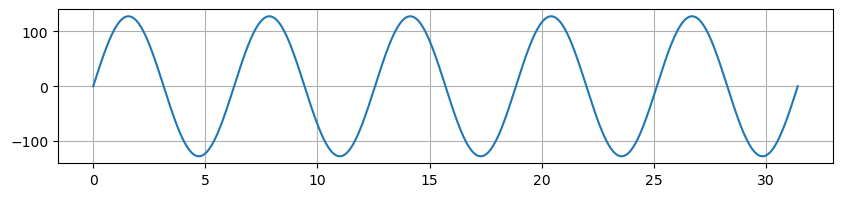
In [49]:
X_analog = np.linspace(0, 5*2*np.pi, 1000)
y_analog = np.sin(X_analog-0.5*np.pi) * 255.0/2.0 # 1/4주기(90도) 만큼 오른쪽으로 이동(위상) - 위상이 다른 신호
plt.figure(figsize=(10, 2))
plt.plot(X_analog, y_analog)
plt.grid()
plt.show()
Out [49]:
위상이 다른 신호이지만 abs를 적용하면 위상이 없어져 같은 신호가 되어버린다!
이 사라진 위상을 살리는데에 인공지능을 사용한다.
댓글남기기