
음성 처리(STT) - wav2vec(pytorch)
wav2vec(pytorch)
In [1]:
import os, IPython, matplotlib
import matplotlib.pyplot as plt
import requests, torch, torchaudio
In [2]:
matplotlib.rcParams["figure.figsize"] = [16.0, 4.8]
torch.random.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
Out [2]:
device(type='cuda')
In [3]:
SPEECH_URL = "https://pytorch-tutorial-assets.s3.amazonaws.com/VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"
SPEECH_URL
Out [3]:
'https://pytorch-tutorial-assets.s3.amazonaws.com/VOiCES_devkit/source-16k/train/sp0307/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav'
In [4]:
SPEECH_FILE = "_assets/speech.wav"
In [5]:
if not os.path.exists(SPEECH_FILE):
os.makedirs("_assets", exist_ok=True)
with open(SPEECH_FILE, "wb") as file:
file.write(requests.get(SPEECH_URL).content)
In [6]:
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H # ASR: auto speech recognition
bundle.sample_rate, bundle.get_labels()
Out [6]:
(16000,
('-',
'|',
'E',
'T',
'A',
'O',
'N',
'I',
'H',
'S',
'R',
'D',
'L',
'U',
'M',
'W',
'C',
'F',
'G',
'Y',
'P',
'B',
'V',
'K',
"'",
'X',
'J',
'Q',
'Z'))
In [7]:
model = bundle.get_model().to(device)
Out [7]:
Downloading: "https://download.pytorch.org/torchaudio/models/wav2vec2_fairseq_base_ls960_asr_ls960.pth" to /root/.cache/torch/hub/checkpoints/wav2vec2_fairseq_base_ls960_asr_ls960.pth
0%| | 0.00/360M [00:00<?, ?B/s]
In [8]:
model.eval()
Out [8]:
Wav2Vec2Model(
(feature_extractor): FeatureExtractor(
(conv_layers): ModuleList(
(0): ConvLayerBlock(
(layer_norm): GroupNorm(512, 512, eps=1e-05, affine=True)
(conv): Conv1d(1, 512, kernel_size=(10,), stride=(5,), bias=False)
)
(1): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(2): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(3): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(4): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(3,), stride=(2,), bias=False)
)
(5): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
)
(6): ConvLayerBlock(
(conv): Conv1d(512, 512, kernel_size=(2,), stride=(2,), bias=False)
)
)
)
(encoder): Encoder(
(feature_projection): FeatureProjection(
(layer_norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)
(projection): Linear(in_features=512, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(transformer): Transformer(
(pos_conv_embed): ConvolutionalPositionalEmbedding(
(conv): Conv1d(768, 768, kernel_size=(128,), stride=(1,), padding=(64,), groups=16)
)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
(layers): ModuleList(
(0): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(1): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(2): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(3): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(4): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(5): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(6): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(7): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(8): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(9): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(10): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
(11): EncoderLayer(
(attention): SelfAttention(
(dropout): Dropout(p=0.1, inplace=False)
(k_proj): Linear(in_features=768, out_features=768, bias=True)
(v_proj): Linear(in_features=768, out_features=768, bias=True)
(q_proj): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
(layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(feed_forward): FeedForward(
(intermediate_dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_dropout): Dropout(p=0.0, inplace=False)
(output_dense): Linear(in_features=3072, out_features=768, bias=True)
(output_dropout): Dropout(p=0.1, inplace=False)
)
(final_layer_norm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
)
)
)
(aux): Linear(in_features=768, out_features=29, bias=True)
)
In [9]:
IPython.display.Audio(SPEECH_FILE)
Out [9]:
In [10]:
wave_form, sr = torchaudio.load(SPEECH_FILE)
wave_form = wave_form.to(device)
In [11]:
sr, bundle.sample_rate
Out [11]:
(16000, 16000)
In [12]:
with torch.inference_mode():
features, _ = model.extract_features(wave_form)
- 음향 특성 확인
In [13]:
fig, ax = plt.subplots(len(features), 1, figsize=(16, 4.3*len(features)))
for i, feature in enumerate(features):
ax[i].imshow(feature[0].cpu())
ax[i].set_title(f'feature from transformer layer {i}')
ax[i].set_xlabel('feature dimension')
ax[i].set_ylabel('Frame (time-axis)')
plt.tight_layout()
plt.show
Out [13]:
<function matplotlib.pyplot.show(*args, **kw)>

- 예측 결과 보기
In [14]:
with torch.inference_mode():
emission, _ = model(wave_form)
In [15]:
print(len(bundle.get_labels()), bundle.get_labels())
Out [15]:
29 ('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
In [16]:
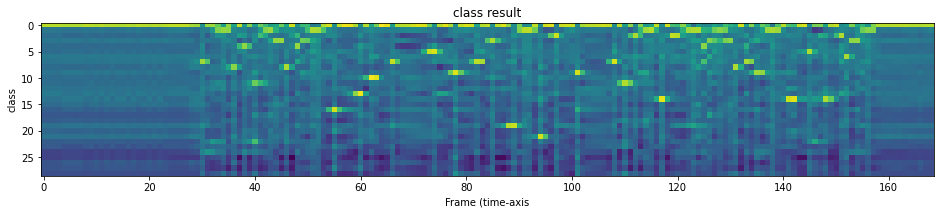
plt.imshow(emission[0].cpu().T)
plt.title("class result")
plt.xlabel("Frame (time-axis")
plt.ylabel("class")
plt.show()
Out [16]:
- transscript 만들기
기대문장: i had that curiousity beside me at this moment
In [17]:
len('i had that curiousity beside me at this moment')
Out [17]:
46
In [18]:
class GreedyCTCDecoder(torch.nn.Module):
def __init__(self, labels, blank=0):
super().__init__()
self.labels = labels
self.blank = blank
def forward(self, emission: torch.Tensor) -> str:
indices = torch.argmax(emission, dim=-1)
indices = torch.unique_consecutive(indices, dim=-1) # ii hhaadd 중복방지
indices = [i for i in indices if i != self.blank]
return "".join([self.labels[i] for i in indices])
In [19]:
decoder = GreedyCTCDecoder(labels=bundle.get_labels())
In [20]:
decoder(emission[0])
Out [20]:
'I|HAD|THAT|CURIOSITY|BESIDE|ME|AT|THIS|MOMENT|'
음성을 그대로 처리 하는 것이 아니라 mel spectrogram으로 이를 변환하여 학습, 예측하는 과정을 거친다.
댓글남기기